 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBuilding Low-Resource NER Models Using Non-Speaker Annotation
Jun 17, 2020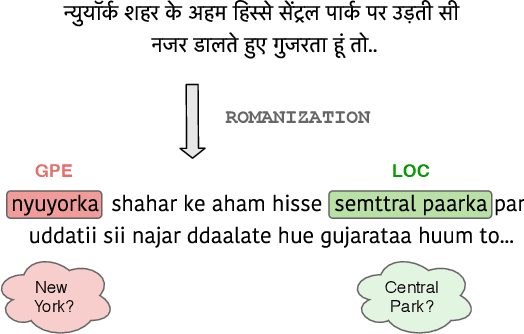
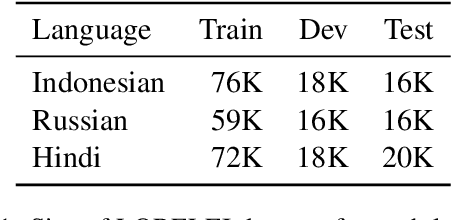
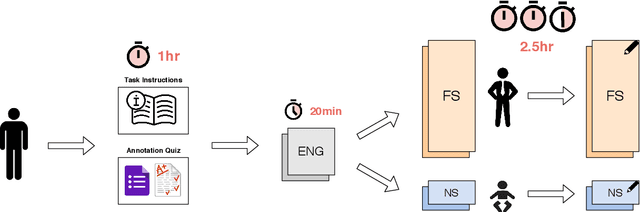
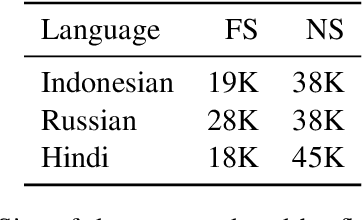
In low-resource natural language processing (NLP), the key problem is a lack of training data in the target language. Cross-lingual methods have had notable success in addressing this concern, but in certain common circumstances, such as insufficient pre-training corpora or languages far from the source language, their performance suffers. In this work we propose an alternative approach to building low-resource Named Entity Recognition (NER) models using "non-speaker" (NS) annotations, provided by annotators with no prior experience in the target language. We recruit 30 participants to annotate unfamiliar languages in a carefully controlled annotation experiment, using Indonesian, Russian, and Hindi as target languages. Our results show that use of non-speaker annotators produces results that approach or match performance of fluent speakers. NS results are also consistently on par or better than cross-lingual methods built on modern contextual representations, and have the potential to further outperform with additional effort. We conclude with observations of common annotation practices and recommendations for maximizing non-speaker annotator performance.