 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNamed Entity Recognition with Partially Annotated Training Data
Sep 20, 2019
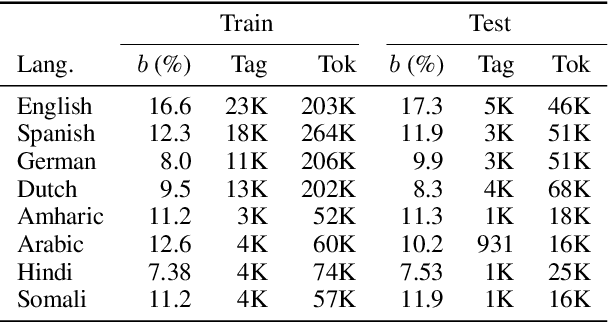

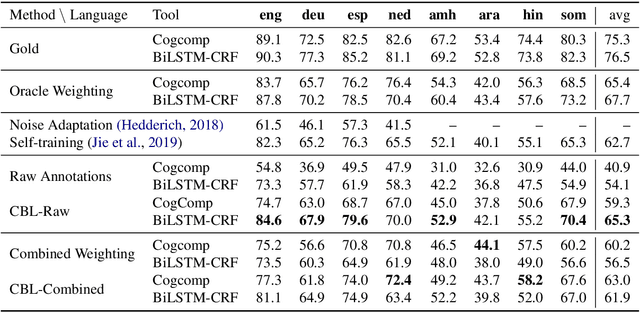
Supervised machine learning assumes the availability of fully-labeled data, but in many cases, such as low-resource languages, the only data available is partially annotated. We study the problem of Named Entity Recognition (NER) with partially annotated training data in which a fraction of the named entities are labeled, and all other tokens, entities or otherwise, are labeled as non-entity by default. In order to train on this noisy dataset, we need to distinguish between the true and false negatives. To this end, we introduce a constraint-driven iterative algorithm that learns to detect false negatives in the noisy set and downweigh them, resulting in a weighted training set. With this set, we train a weighted NER model. We evaluate our algorithm with weighted variants of neural and non-neural NER models on data in 8 languages from several language and script families, showing strong ability to learn from partial data. Finally, to show real-world efficacy, we evaluate on a Bengali NER corpus annotated by non-speakers, outperforming the prior state-of-the-art by over 5 points F1.
Zero-Shot Open Entity Typing as Type-Compatible Grounding
Jul 07, 2019
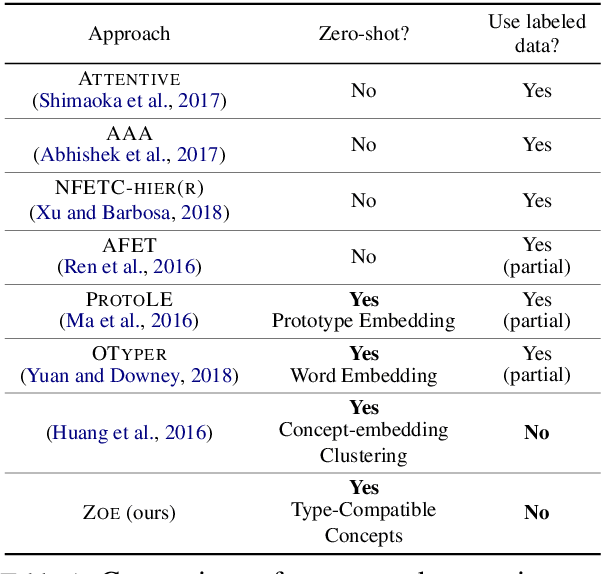
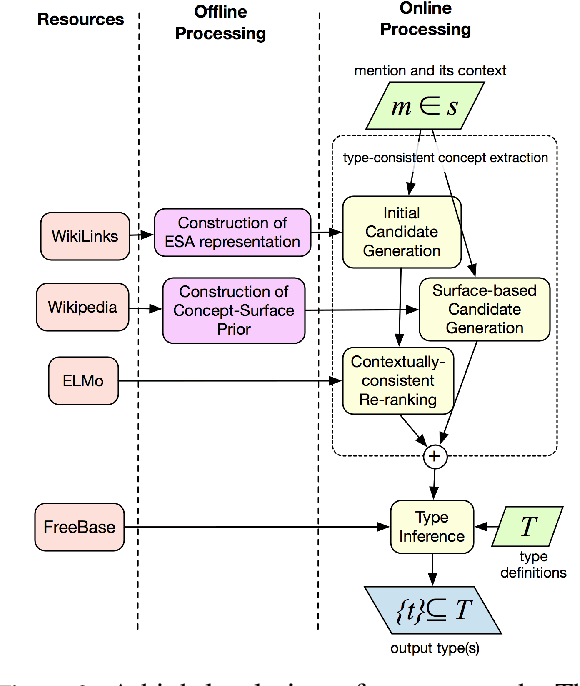
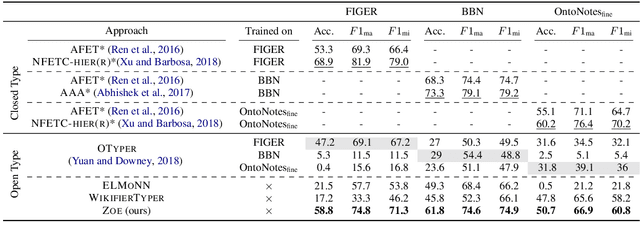
The problem of entity-typing has been studied predominantly in supervised learning fashion, mostly with task-specific annotations (for coarse types) and sometimes with distant supervision (for fine types). While such approaches have strong performance within datasets, they often lack the flexibility to transfer across text genres and to generalize to new type taxonomies. In this work we propose a zero-shot entity typing approach that requires no annotated data and can flexibly identify newly defined types. Given a type taxonomy defined as Boolean functions of FREEBASE "types", we ground a given mention to a set of type-compatible Wikipedia entries and then infer the target mention's types using an inference algorithm that makes use of the types of these entries. We evaluate our system on a broad range of datasets, including standard fine-grained and coarse-grained entity typing datasets, and also a dataset in the biological domain. Our system is shown to be competitive with state-of-the-art supervised NER systems and outperforms them on out-of-domain datasets. We also show that our system significantly outperforms other zero-shot fine typing systems.