 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Tarzan to Tolkien: Controlling the Language Proficiency Level of LLMs for Content Generation
Jun 05, 2024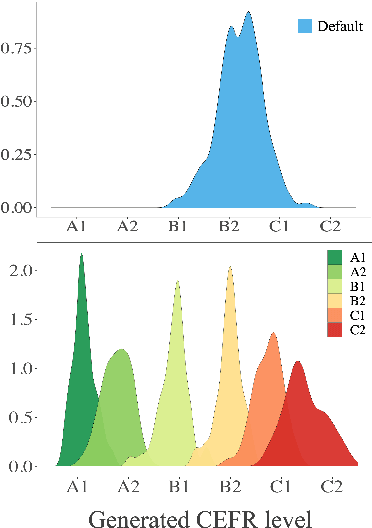
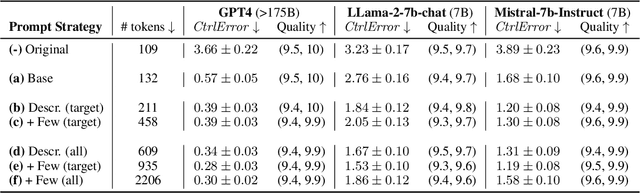
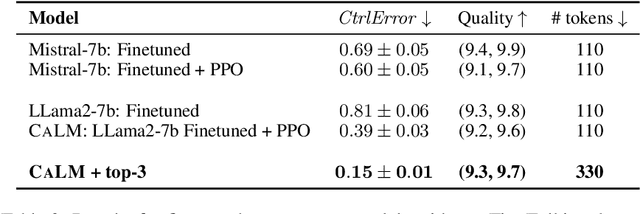
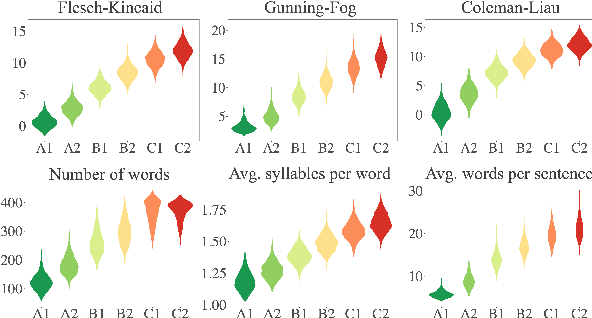
We study the problem of controlling the difficulty level of text generated by Large Language Models (LLMs) for contexts where end-users are not fully proficient, such as language learners. Using a novel framework, we evaluate the effectiveness of several key approaches for this task, including few-shot prompting, supervised finetuning, and reinforcement learning (RL), utilising both GPT-4 and open source alternatives like LLama2-7B and Mistral-7B. Our findings reveal a large performance gap between GPT-4 and the open source models when using prompt-based strategies. However, we show how to bridge this gap with a careful combination of finetuning and RL alignment. Our best model, CALM (CEFR-Aligned Language Model), surpasses the performance of GPT-4 and other strategies, at only a fraction of the cost. We further validate the quality of our results through a small-scale human study.
Lifting uniform learners via distributional decomposition
Mar 30, 2023

We show how any PAC learning algorithm that works under the uniform distribution can be transformed, in a blackbox fashion, into one that works under an arbitrary and unknown distribution $\mathcal{D}$. The efficiency of our transformation scales with the inherent complexity of $\mathcal{D}$, running in $\mathrm{poly}(n, (md)^d)$ time for distributions over $\{\pm 1\}^n$ whose pmfs are computed by depth-$d$ decision trees, where $m$ is the sample complexity of the original algorithm. For monotone distributions our transformation uses only samples from $\mathcal{D}$, and for general ones it uses subcube conditioning samples. A key technical ingredient is an algorithm which, given the aforementioned access to $\mathcal{D}$, produces an optimal decision tree decomposition of $\mathcal{D}$: an approximation of $\mathcal{D}$ as a mixture of uniform distributions over disjoint subcubes. With this decomposition in hand, we run the uniform-distribution learner on each subcube and combine the hypotheses using the decision tree. This algorithmic decomposition lemma also yields new algorithms for learning decision tree distributions with runtimes that exponentially improve on the prior state of the art -- results of independent interest in distribution learning.
Popular decision tree algorithms are provably noise tolerant
Jun 17, 2022
Using the framework of boosting, we prove that all impurity-based decision tree learning algorithms, including the classic ID3, C4.5, and CART, are highly noise tolerant. Our guarantees hold under the strongest noise model of nasty noise, and we provide near-matching upper and lower bounds on the allowable noise rate. We further show that these algorithms, which are simple and have long been central to everyday machine learning, enjoy provable guarantees in the noisy setting that are unmatched by existing algorithms in the theoretical literature on decision tree learning. Taken together, our results add to an ongoing line of research that seeks to place the empirical success of these practical decision tree algorithms on firm theoretical footing.
On the power of adaptivity in statistical adversaries
Nov 19, 2021
We study a fundamental question concerning adversarial noise models in statistical problems where the algorithm receives i.i.d. draws from a distribution $\mathcal{D}$. The definitions of these adversaries specify the type of allowable corruptions (noise model) as well as when these corruptions can be made (adaptivity); the latter differentiates between oblivious adversaries that can only corrupt the distribution $\mathcal{D}$ and adaptive adversaries that can have their corruptions depend on the specific sample $S$ that is drawn from $\mathcal{D}$. In this work, we investigate whether oblivious adversaries are effectively equivalent to adaptive adversaries, across all noise models studied in the literature. Specifically, can the behavior of an algorithm $\mathcal{A}$ in the presence of oblivious adversaries always be well-approximated by that of an algorithm $\mathcal{A}'$ in the presence of adaptive adversaries? Our first result shows that this is indeed the case for the broad class of statistical query algorithms, under all reasonable noise models. We then show that in the specific case of additive noise, this equivalence holds for all algorithms. Finally, we map out an approach towards proving this statement in its fullest generality, for all algorithms and under all reasonable noise models.
On the Opportunities and Risks of Foundation Models
Aug 18, 2021



AI is undergoing a paradigm shift with the rise of models (e.g., BERT, DALL-E, GPT-3) that are trained on broad data at scale and are adaptable to a wide range of downstream tasks. We call these models foundation models to underscore their critically central yet incomplete character. This report provides a thorough account of the opportunities and risks of foundation models, ranging from their capabilities (e.g., language, vision, robotics, reasoning, human interaction) and technical principles(e.g., model architectures, training procedures, data, systems, security, evaluation, theory) to their applications (e.g., law, healthcare, education) and societal impact (e.g., inequity, misuse, economic and environmental impact, legal and ethical considerations). Though foundation models are based on standard deep learning and transfer learning, their scale results in new emergent capabilities,and their effectiveness across so many tasks incentivizes homogenization. Homogenization provides powerful leverage but demands caution, as the defects of the foundation model are inherited by all the adapted models downstream. Despite the impending widespread deployment of foundation models, we currently lack a clear understanding of how they work, when they fail, and what they are even capable of due to their emergent properties. To tackle these questions, we believe much of the critical research on foundation models will require deep interdisciplinary collaboration commensurate with their fundamentally sociotechnical nature.
Calibrated Model-Based Deep Reinforcement Learning
Jun 19, 2019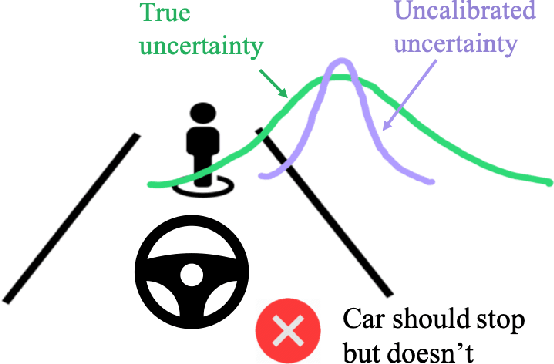
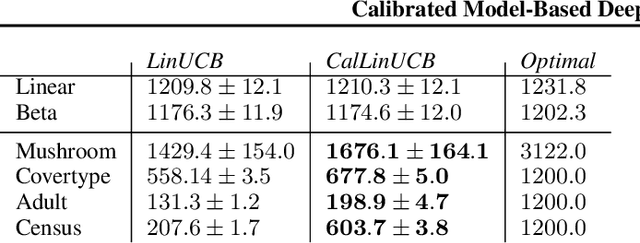
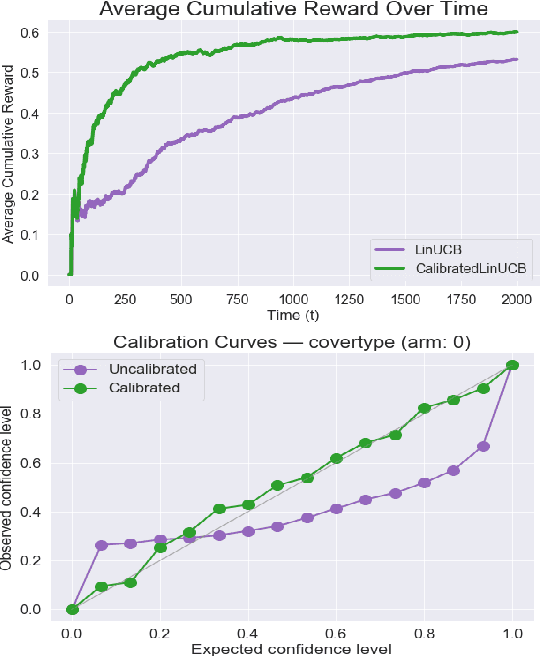
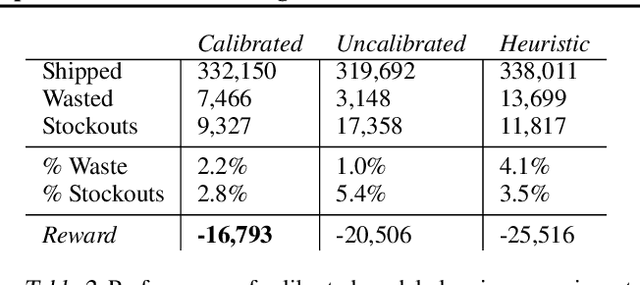
Estimates of predictive uncertainty are important for accurate model-based planning and reinforcement learning. However, predictive uncertainties---especially ones derived from modern deep learning systems---can be inaccurate and impose a bottleneck on performance. This paper explores which uncertainties are needed for model-based reinforcement learning and argues that good uncertainties must be calibrated, i.e. their probabilities should match empirical frequencies of predicted events. We describe a simple way to augment any model-based reinforcement learning agent with a calibrated model and show that doing so consistently improves planning, sample complexity, and exploration. On the \textsc{HalfCheetah} MuJoCo task, our system achieves state-of-the-art performance using 50\% fewer samples than the current leading approach. Our findings suggest that calibration can improve the performance of model-based reinforcement learning with minimal computational and implementation overhead.
The Stanford Acuity Test: A Probabilistic Approach for Precise Visual Acuity Testing
Jun 05, 2019
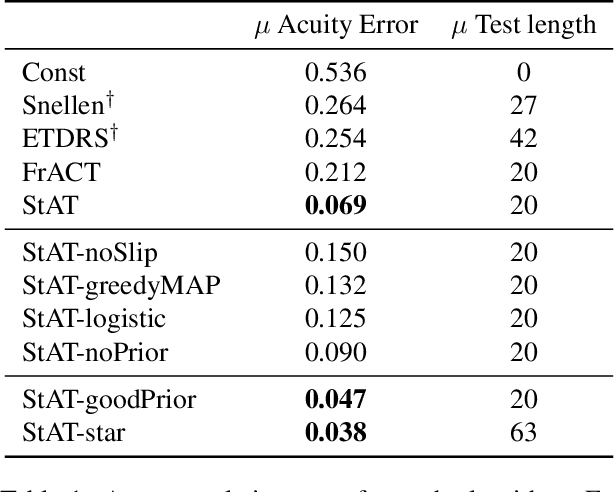
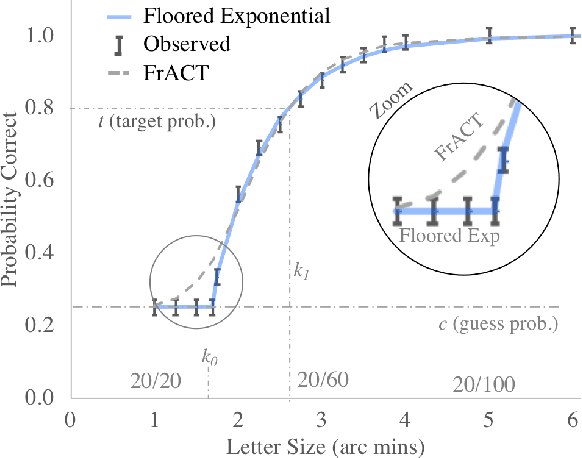
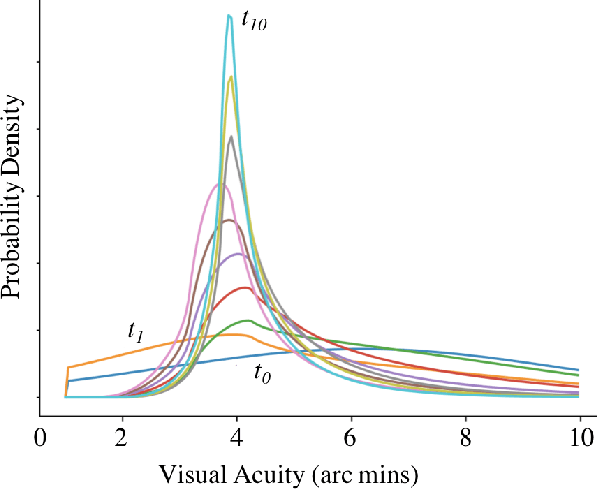
Chart-based visual acuity measurements are used by billions of people to diagnose and guide treatment of vision impairment. However, the ubiquitous eye exam has no mechanism for reasoning about uncertainty and as such, suffers from a well-documented reproducibility problem. In this paper we uncover a new parametric probabilistic model of visual acuity response based on measurements of patients with eye disease. We present a state of the art eye exam which (1) reduces acuity exam error by 75\% without increasing exam length, (2) knows how confident it should be, (3) can trace predictions over time and incorporate prior beliefs and (4) provides insight for educational Item Response Theory. For patients with more serious eye disease, the novel ability to finely measure acuity from home could be a crucial part in early diagnosis. We provide a web implementation of our algorithm for anyone in the world to use.
Using Latent Variable Models to Observe Academic Pathways
May 31, 2019

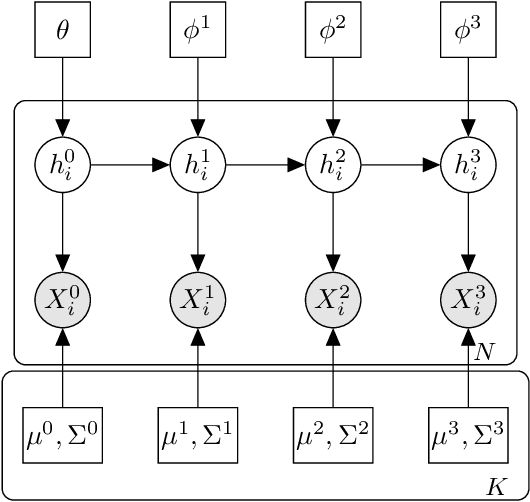

Understanding large-scale patterns in student course enrollment is a problem of great interest to university administrators and educational researchers. Yet important decisions are often made without a good quantitative framework of the process underlying student choices. We propose a probabilistic approach to modelling course enrollment decisions, drawing inspiration from multilabel classification and mixture models. We use ten years of anonymized student transcripts from a large university to construct a Gaussian latent variable model that learns the joint distribution over course enrollments. The models allow for a diverse set of inference queries and robustness to data sparsity. We demonstrate the efficacy of this approach in comparison to others, including deep learning architectures, and demonstrate its ability to infer the underlying student interests that guide enrollment decisions.
Generative Grading: Neural Approximate Parsing for Automated Student Feedback
May 23, 2019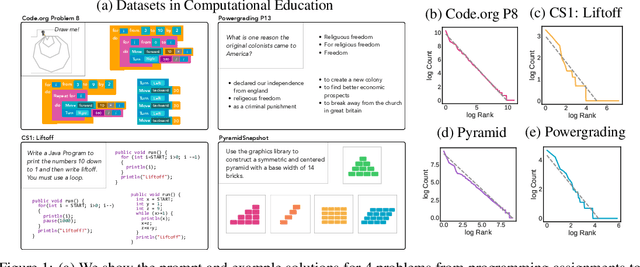

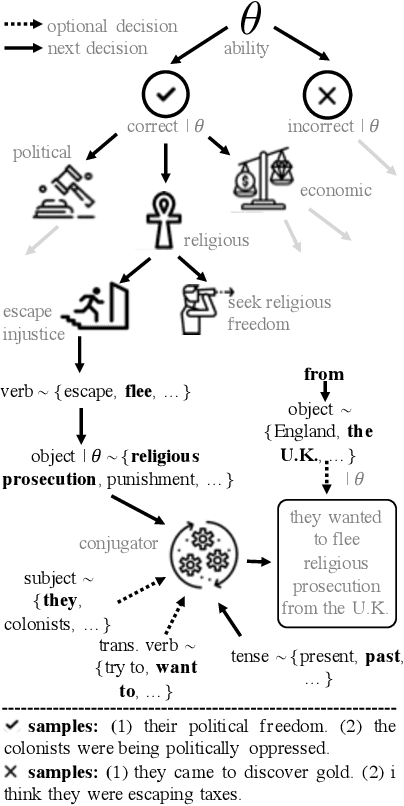
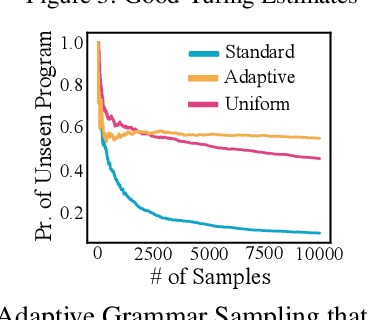
Open access to high-quality education is limited by the difficulty of providing student feedback. In this paper, we present Generative Grading with Neural Approximate Parsing (GG-NAP): a novel approach for providing feedback at scale that is capable of both accurately grading student work while also providing verifiability--a property where the model is able to substantiate its claims with a provable certificate. Our approach uses generative descriptions of student cognition, written as probabilistic programs, to synthesise millions of labelled example solutions to a problem; it then trains inference networks to approximately parse real student solutions according to these generative models. We achieve feedback prediction accuracy comparable to professional human experts in a variety of settings: short-answer questions, programs with graphical output, block-based programming, and short Java programs. In a real classroom, we ran an experiment where humans used GG-NAP to grade, yielding doubled grading accuracy while halving grading time.