 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMemory-Based Model Editing at Scale
Jun 13, 2022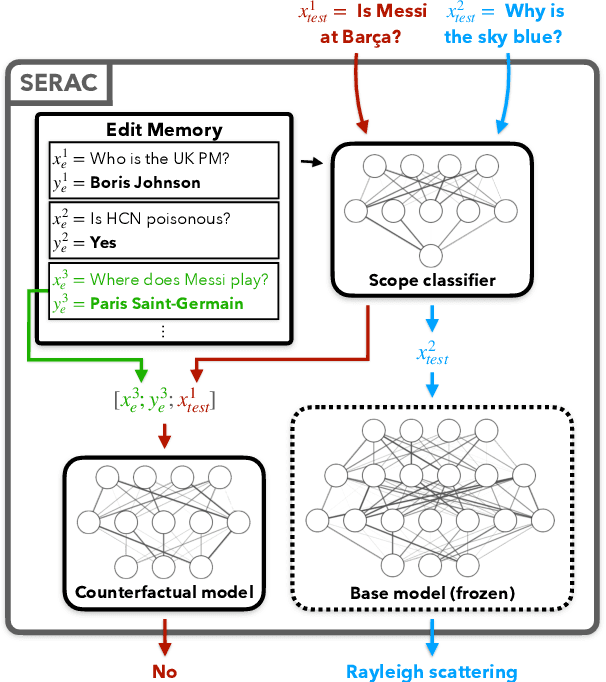



Even the largest neural networks make errors, and once-correct predictions can become invalid as the world changes. Model editors make local updates to the behavior of base (pre-trained) models to inject updated knowledge or correct undesirable behaviors. Existing model editors have shown promise, but also suffer from insufficient expressiveness: they struggle to accurately model an edit's intended scope (examples affected by the edit), leading to inaccurate predictions for test inputs loosely related to the edit, and they often fail altogether after many edits. As a higher-capacity alternative, we propose Semi-Parametric Editing with a Retrieval-Augmented Counterfactual Model (SERAC), which stores edits in an explicit memory and learns to reason over them to modulate the base model's predictions as needed. To enable more rigorous evaluation of model editors, we introduce three challenging language model editing problems based on question answering, fact-checking, and dialogue generation. We find that only SERAC achieves high performance on all three problems, consistently outperforming existing approaches to model editing by a significant margin. Code, data, and additional project information will be made available at https://sites.google.com/view/serac-editing.
Fast Model Editing at Scale
Oct 21, 2021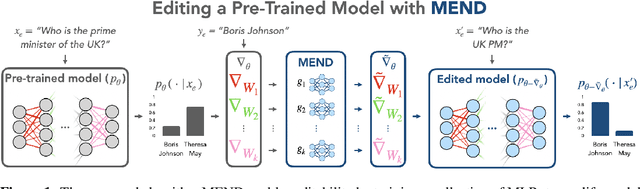

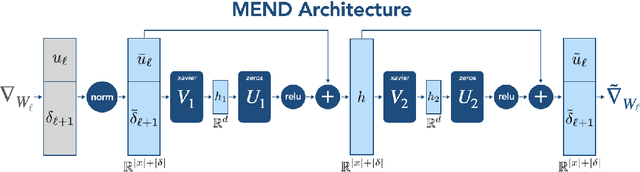

While large pre-trained models have enabled impressive results on a variety of downstream tasks, the largest existing models still make errors, and even accurate predictions may become outdated over time. Because detecting all such failures at training time is impossible, enabling both developers and end users of such models to correct inaccurate outputs while leaving the model otherwise intact is desirable. However, the distributed, black-box nature of the representations learned by large neural networks makes producing such targeted edits difficult. If presented with only a single problematic input and new desired output, fine-tuning approaches tend to overfit; other editing algorithms are either computationally infeasible or simply ineffective when applied to very large models. To enable easy post-hoc editing at scale, we propose Model Editor Networks with Gradient Decomposition (MEND), a collection of small auxiliary editing networks that use a single desired input-output pair to make fast, local edits to a pre-trained model. MEND learns to transform the gradient obtained by standard fine-tuning, using a low-rank decomposition of the gradient to make the parameterization of this transformation tractable. MEND can be trained on a single GPU in less than a day even for 10 billion+ parameter models; once trained MEND enables rapid application of new edits to the pre-trained model. Our experiments with T5, GPT, BERT, and BART models show that MEND is the only approach to model editing that produces effective edits for models with tens of millions to over 10 billion parameters. Implementation available at https://sites.google.com/view/mend-editing.
LASER: Learning a Latent Action Space for Efficient Reinforcement Learning
Mar 30, 2021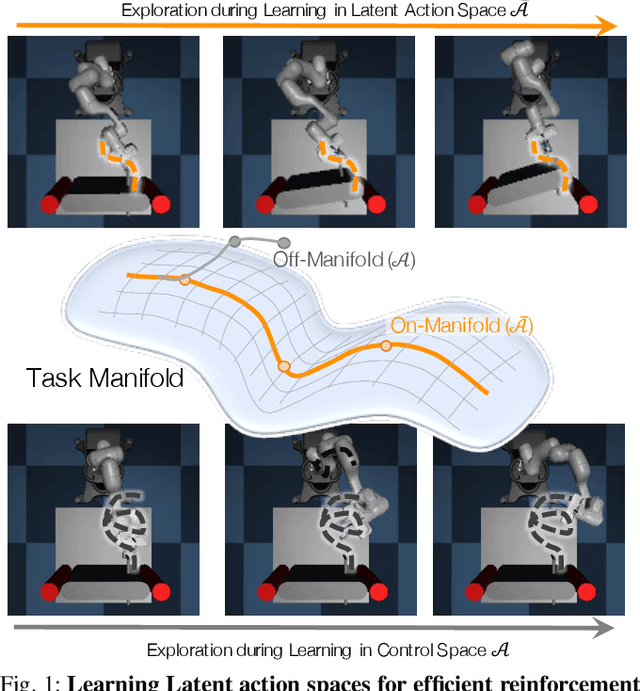
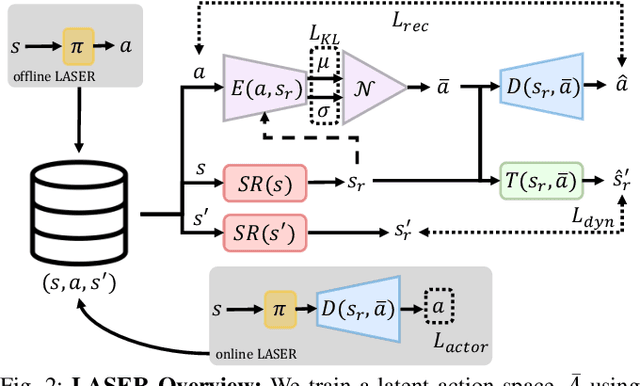

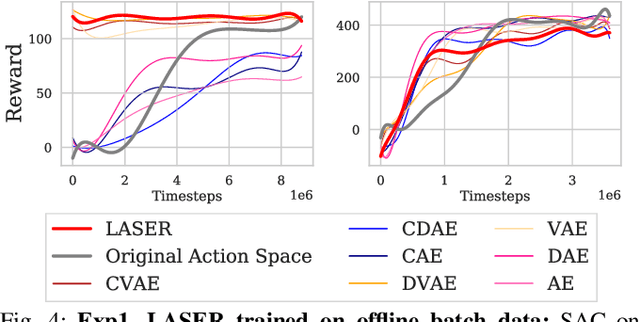
The process of learning a manipulation task depends strongly on the action space used for exploration: posed in the incorrect action space, solving a task with reinforcement learning can be drastically inefficient. Additionally, similar tasks or instances of the same task family impose latent manifold constraints on the most effective action space: the task family can be best solved with actions in a manifold of the entire action space of the robot. Combining these insights we present LASER, a method to learn latent action spaces for efficient reinforcement learning. LASER factorizes the learning problem into two sub-problems, namely action space learning and policy learning in the new action space. It leverages data from similar manipulation task instances, either from an offline expert or online during policy learning, and learns from these trajectories a mapping from the original to a latent action space. LASER is trained as a variational encoder-decoder model to map raw actions into a disentangled latent action space while maintaining action reconstruction and latent space dynamic consistency. We evaluate LASER on two contact-rich robotic tasks in simulation, and analyze the benefit of policy learning in the generated latent action space. We show improved sample efficiency compared to the original action space from better alignment of the action space to the task space, as we observe with visualizations of the learned action space manifold. Additional details: https://www.pair.toronto.edu/laser
The Stanford Acuity Test: A Probabilistic Approach for Precise Visual Acuity Testing
Jun 05, 2019
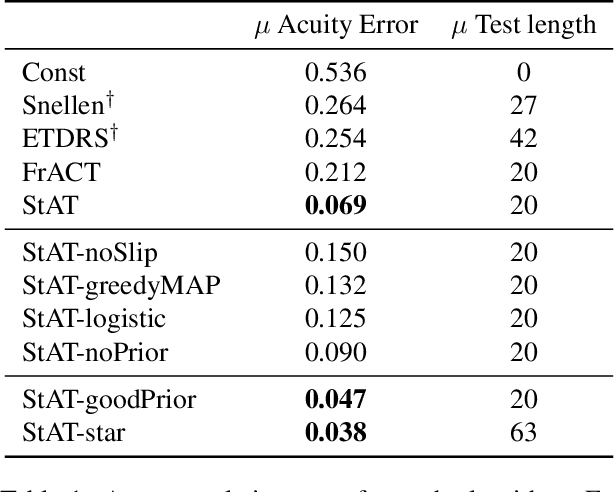
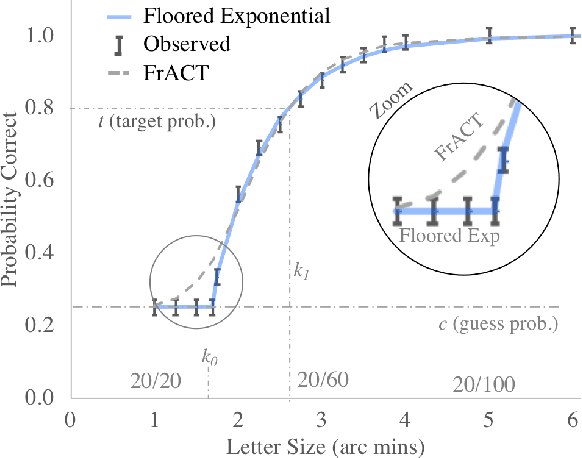
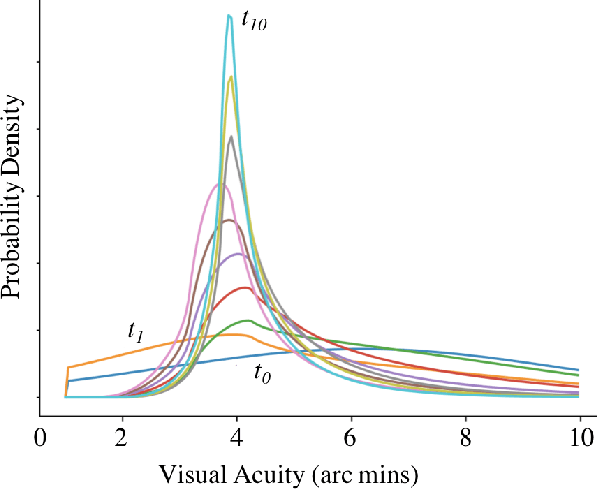
Chart-based visual acuity measurements are used by billions of people to diagnose and guide treatment of vision impairment. However, the ubiquitous eye exam has no mechanism for reasoning about uncertainty and as such, suffers from a well-documented reproducibility problem. In this paper we uncover a new parametric probabilistic model of visual acuity response based on measurements of patients with eye disease. We present a state of the art eye exam which (1) reduces acuity exam error by 75\% without increasing exam length, (2) knows how confident it should be, (3) can trace predictions over time and incorporate prior beliefs and (4) provides insight for educational Item Response Theory. For patients with more serious eye disease, the novel ability to finely measure acuity from home could be a crucial part in early diagnosis. We provide a web implementation of our algorithm for anyone in the world to use.