 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards an Autonomous Test Driver: High-Performance Driver Modeling via Reinforcement Learning
Dec 05, 2024



Success in racing requires a unique combination of vehicle setup, understanding of the racetrack, and human expertise. Since building and testing many different vehicle configurations in the real world is prohibitively expensive, high-fidelity simulation is a critical part of racecar development. However, testing different vehicle configurations still requires expert human input in order to evaluate their performance on different racetracks. In this work, we present the first steps towards an autonomous test driver, trained using deep reinforcement learning, capable of evaluating changes in vehicle setup on racing performance while driving at the level of the best human drivers. In addition, the autonomous driver model can be tuned to exhibit more human-like behavioral patterns by incorporating imitation learning into the RL training process. This extension permits the possibility of driver-specific vehicle setup optimization.
Model Predictive Optimized Path Integral Strategies
Mar 30, 2022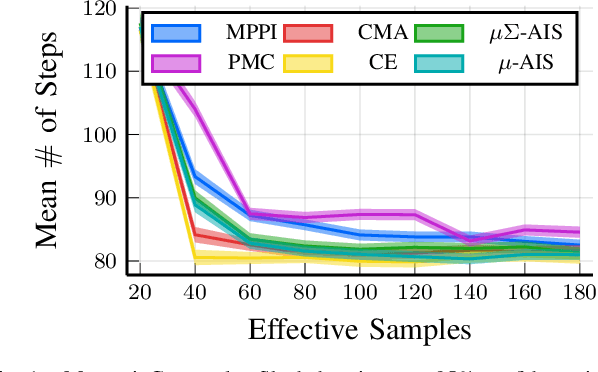
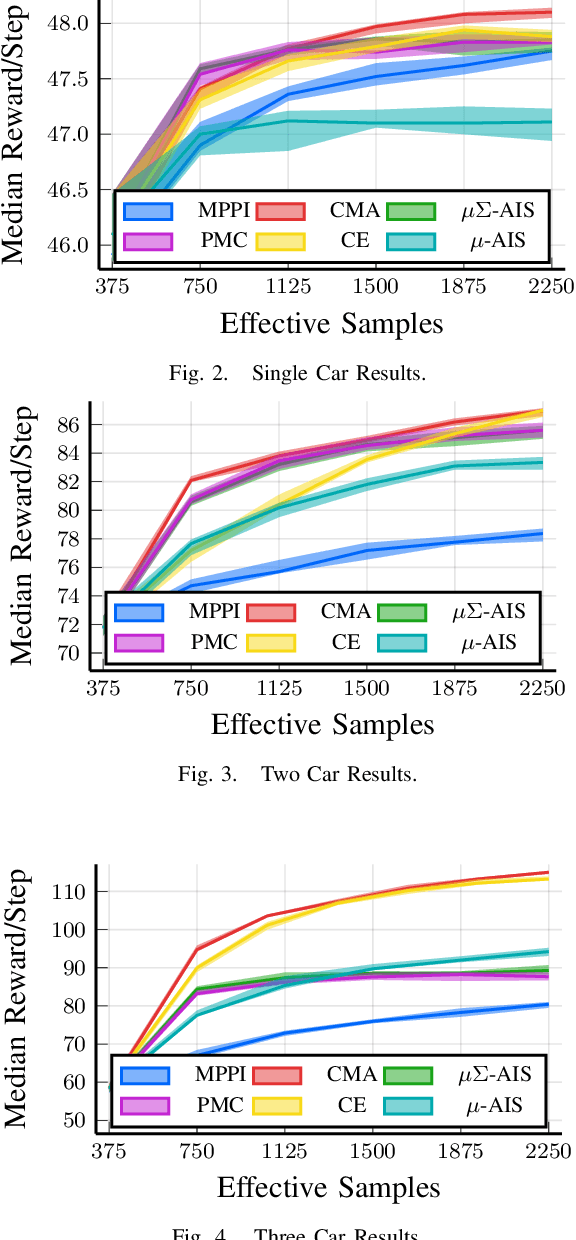
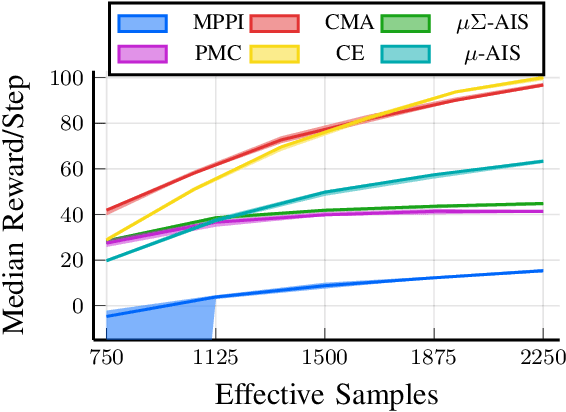
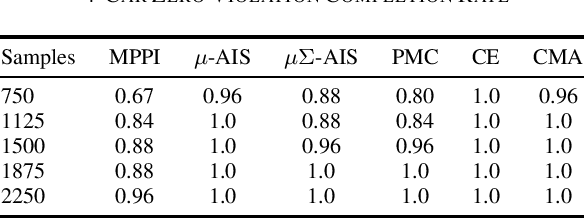
We generalize the derivation of model predictive path integral control (MPPI) to allow for a single joint distribution across controls in the control sequence. This reformation allows for the implementation of adaptive importance sampling (AIS) algorithms into the original importance sampling step while still maintaining the benefits of MPPI such as working with arbitrary system dynamics and cost functions. The benefit of optimizing the proposal distribution by integrating AIS at each control step is demonstrated in simulated environments including controlling multiple cars around a track. The new algorithm is more sample efficient than MPPI, achieving better performance with fewer samples. This performance disparity grows as the dimension of the action space increases. Results from simulations suggest the new algorithm can be used as an anytime algorithm, increasing the value of control at each iteration versus relying on a large set of samples.
LASER: Learning a Latent Action Space for Efficient Reinforcement Learning
Mar 30, 2021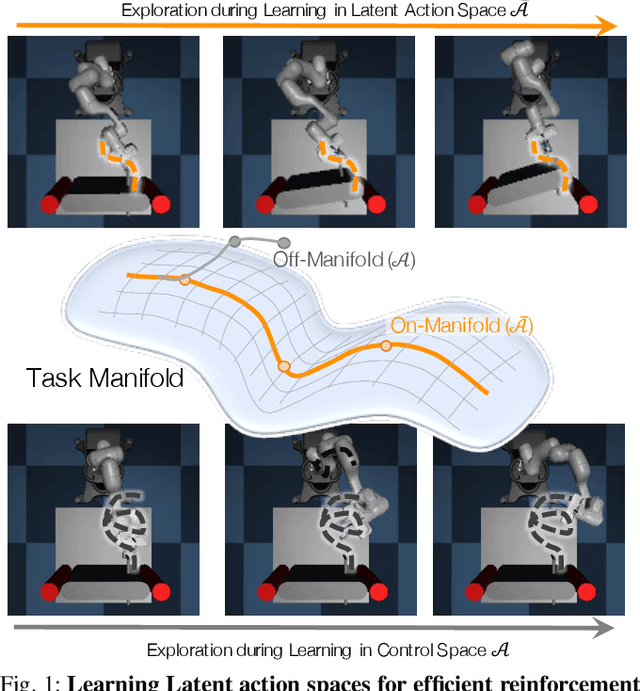
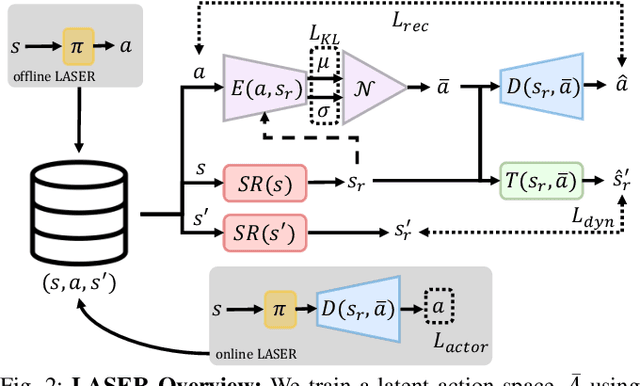

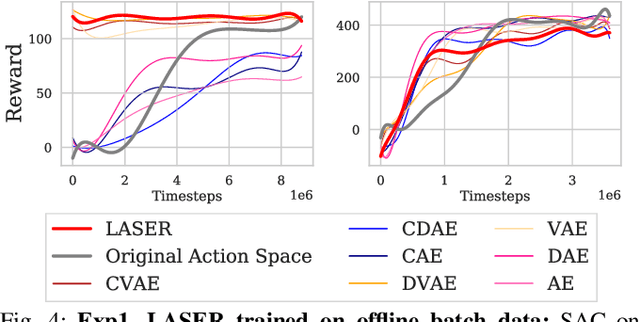
The process of learning a manipulation task depends strongly on the action space used for exploration: posed in the incorrect action space, solving a task with reinforcement learning can be drastically inefficient. Additionally, similar tasks or instances of the same task family impose latent manifold constraints on the most effective action space: the task family can be best solved with actions in a manifold of the entire action space of the robot. Combining these insights we present LASER, a method to learn latent action spaces for efficient reinforcement learning. LASER factorizes the learning problem into two sub-problems, namely action space learning and policy learning in the new action space. It leverages data from similar manipulation task instances, either from an offline expert or online during policy learning, and learns from these trajectories a mapping from the original to a latent action space. LASER is trained as a variational encoder-decoder model to map raw actions into a disentangled latent action space while maintaining action reconstruction and latent space dynamic consistency. We evaluate LASER on two contact-rich robotic tasks in simulation, and analyze the benefit of policy learning in the generated latent action space. We show improved sample efficiency compared to the original action space from better alignment of the action space to the task space, as we observe with visualizations of the learned action space manifold. Additional details: https://www.pair.toronto.edu/laser