 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntegrating Virtual Reality and Large Language Models for Team-Based Non-Technical Skills Training and Evaluation in the Operating Room
Jan 19, 2026Although effective teamwork and communication are critical to surgical safety, structured training for non-technical skills (NTS) remains limited compared with technical simulation. The ACS/APDS Phase III Team-Based Skills Curriculum calls for scalable tools that both teach and objectively assess these competencies during laparoscopic emergencies. We introduce the Virtual Operating Room Team Experience (VORTeX), a multi-user virtual reality (VR) platform that integrates immersive team simulation with large language model (LLM) analytics to train and evaluate communication, decision-making, teamwork, and leadership. Team dialogue is analyzed using structured prompts derived from the Non-Technical Skills for Surgeons (NOTSS) framework, enabling automated classification of behaviors and generation of directed interaction graphs that quantify communication structure and hierarchy. Two laparoscopic emergency scenarios, pneumothorax and intra-abdominal bleeding, were implemented to elicit realistic stress and collaboration. Twelve surgical professionals completed pilot sessions at the 2024 SAGES conference, rating VORTeX as intuitive, immersive, and valuable for developing teamwork and communication. The LLM consistently produced interpretable communication networks reflecting expected operative hierarchies, with surgeons as central integrators, nurses as initiators, and anesthesiologists as balanced intermediaries. By integrating immersive VR with LLM-driven behavioral analytics, VORTeX provides a scalable, privacy-compliant framework for objective assessment and automated, data-informed debriefing across distributed training environments.
Social Skill Training with Large Language Models
Apr 05, 2024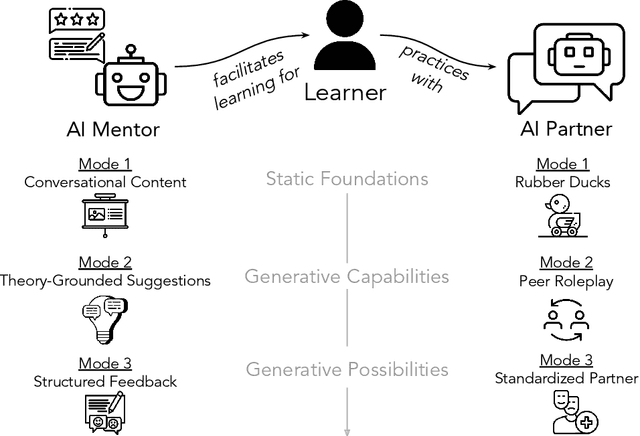
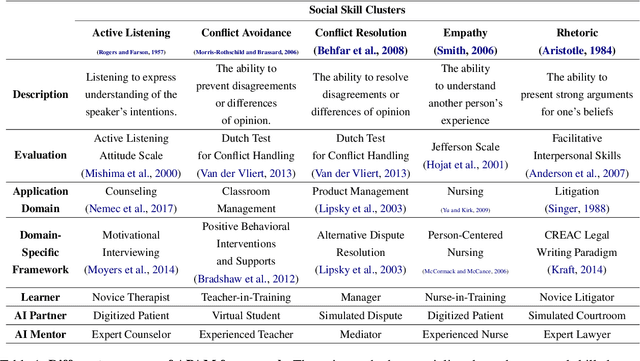
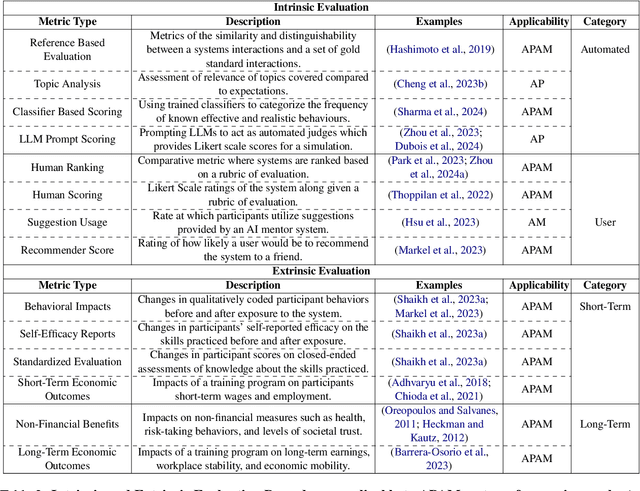
People rely on social skills like conflict resolution to communicate effectively and to thrive in both work and personal life. However, practice environments for social skills are typically out of reach for most people. How can we make social skill training more available, accessible, and inviting? Drawing upon interdisciplinary research from communication and psychology, this perspective paper identifies social skill barriers to enter specialized fields. Then we present a solution that leverages large language models for social skill training via a generic framework. Our AI Partner, AI Mentor framework merges experiential learning with realistic practice and tailored feedback. This work ultimately calls for cross-disciplinary innovation to address the broader implications for workforce development and social equality.
DPAdapter: Improving Differentially Private Deep Learning through Noise Tolerance Pre-training
Mar 05, 2024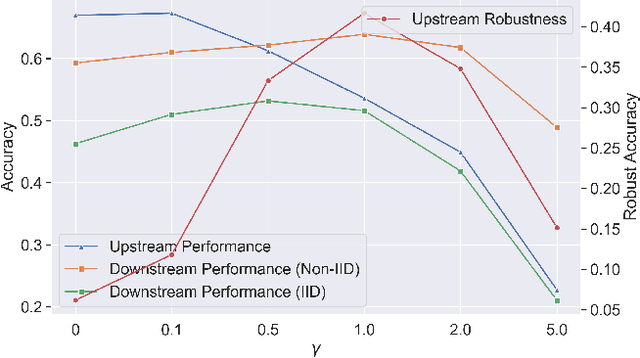
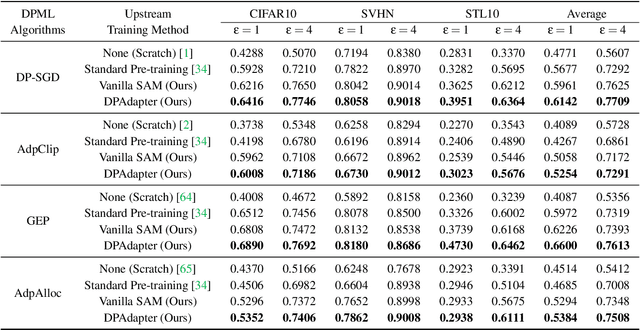
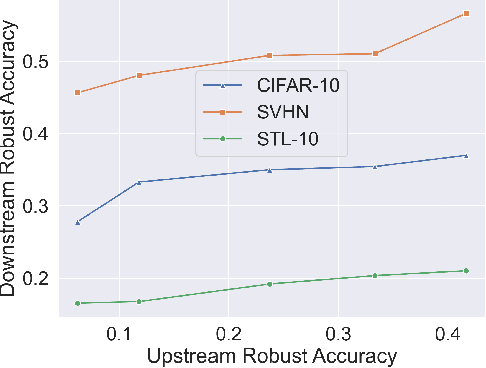
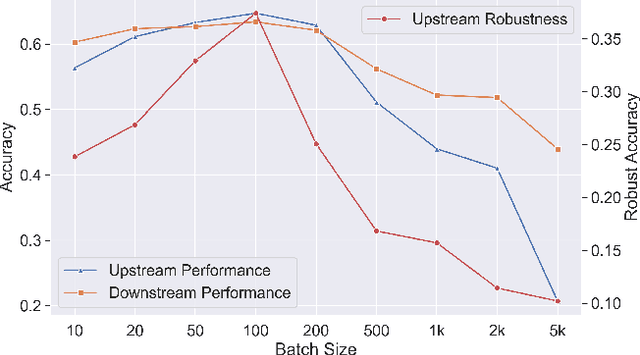
Recent developments have underscored the critical role of \textit{differential privacy} (DP) in safeguarding individual data for training machine learning models. However, integrating DP oftentimes incurs significant model performance degradation due to the perturbation introduced into the training process, presenting a formidable challenge in the {differentially private machine learning} (DPML) field. To this end, several mitigative efforts have been proposed, typically revolving around formulating new DPML algorithms or relaxing DP definitions to harmonize with distinct contexts. In spite of these initiatives, the diminishment induced by DP on models, particularly large-scale models, remains substantial and thus, necessitates an innovative solution that adeptly circumnavigates the consequential impairment of model utility. In response, we introduce DPAdapter, a pioneering technique designed to amplify the model performance of DPML algorithms by enhancing parameter robustness. The fundamental intuition behind this strategy is that models with robust parameters are inherently more resistant to the noise introduced by DP, thereby retaining better performance despite the perturbations. DPAdapter modifies and enhances the sharpness-aware minimization (SAM) technique, utilizing a two-batch strategy to provide a more accurate perturbation estimate and an efficient gradient descent, thereby improving parameter robustness against noise. Notably, DPAdapter can act as a plug-and-play component and be combined with existing DPML algorithms to further improve their performance. Our experiments show that DPAdapter vastly enhances state-of-the-art DPML algorithms, increasing average accuracy from 72.92\% to 77.09\% with a privacy budget of $\epsilon=4$.
TrustLLM: Trustworthiness in Large Language Models
Jan 25, 2024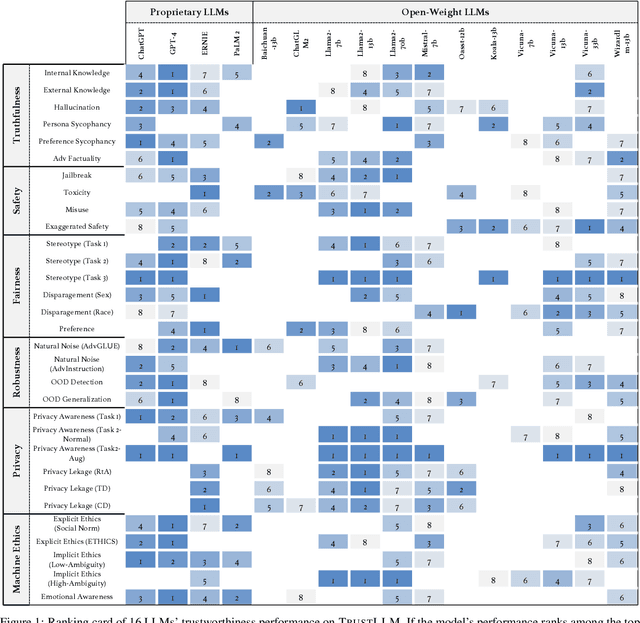


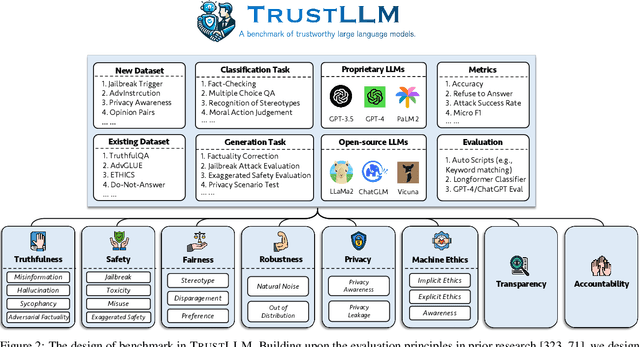
Large language models (LLMs), exemplified by ChatGPT, have gained considerable attention for their excellent natural language processing capabilities. Nonetheless, these LLMs present many challenges, particularly in the realm of trustworthiness. Therefore, ensuring the trustworthiness of LLMs emerges as an important topic. This paper introduces TrustLLM, a comprehensive study of trustworthiness in LLMs, including principles for different dimensions of trustworthiness, established benchmark, evaluation, and analysis of trustworthiness for mainstream LLMs, and discussion of open challenges and future directions. Specifically, we first propose a set of principles for trustworthy LLMs that span eight different dimensions. Based on these principles, we further establish a benchmark across six dimensions including truthfulness, safety, fairness, robustness, privacy, and machine ethics. We then present a study evaluating 16 mainstream LLMs in TrustLLM, consisting of over 30 datasets. Our findings firstly show that in general trustworthiness and utility (i.e., functional effectiveness) are positively related. Secondly, our observations reveal that proprietary LLMs generally outperform most open-source counterparts in terms of trustworthiness, raising concerns about the potential risks of widely accessible open-source LLMs. However, a few open-source LLMs come very close to proprietary ones. Thirdly, it is important to note that some LLMs may be overly calibrated towards exhibiting trustworthiness, to the extent that they compromise their utility by mistakenly treating benign prompts as harmful and consequently not responding. Finally, we emphasize the importance of ensuring transparency not only in the models themselves but also in the technologies that underpin trustworthiness. Knowing the specific trustworthy technologies that have been employed is crucial for analyzing their effectiveness.
Identifying and Mitigating the Security Risks of Generative AI
Aug 28, 2023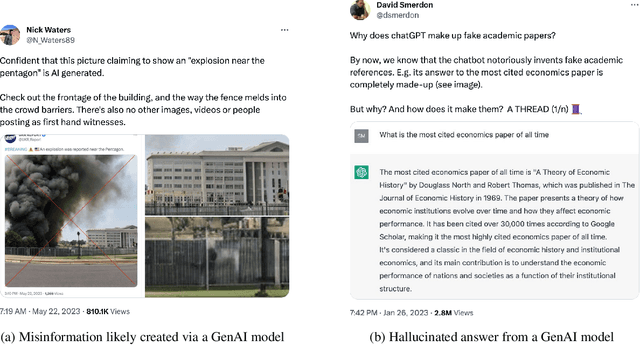
Every major technical invention resurfaces the dual-use dilemma -- the new technology has the potential to be used for good as well as for harm. Generative AI (GenAI) techniques, such as large language models (LLMs) and diffusion models, have shown remarkable capabilities (e.g., in-context learning, code-completion, and text-to-image generation and editing). However, GenAI can be used just as well by attackers to generate new attacks and increase the velocity and efficacy of existing attacks. This paper reports the findings of a workshop held at Google (co-organized by Stanford University and the University of Wisconsin-Madison) on the dual-use dilemma posed by GenAI. This paper is not meant to be comprehensive, but is rather an attempt to synthesize some of the interesting findings from the workshop. We discuss short-term and long-term goals for the community on this topic. We hope this paper provides both a launching point for a discussion on this important topic as well as interesting problems that the research community can work to address.
Generative Grading: Neural Approximate Parsing for Automated Student Feedback
May 23, 2019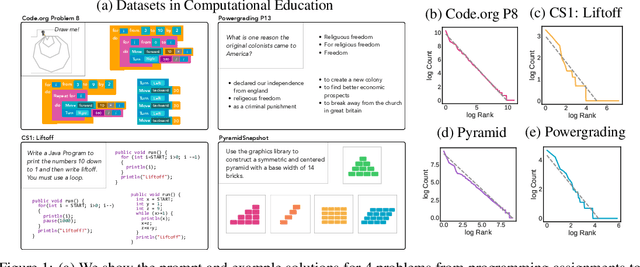

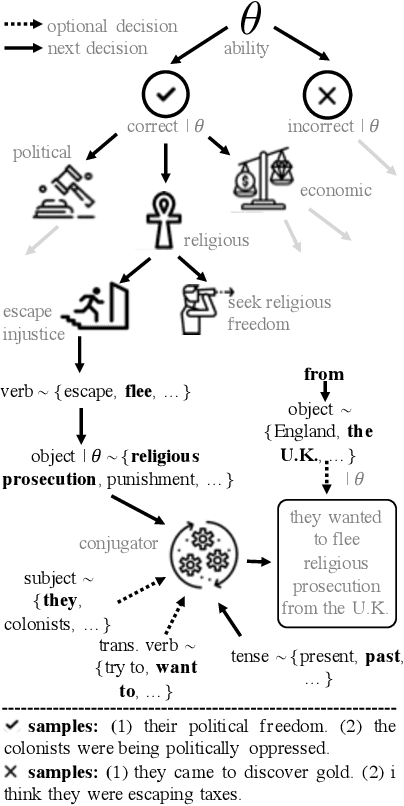
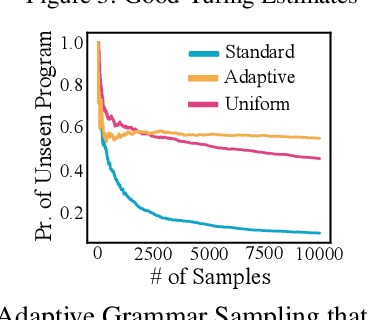
Open access to high-quality education is limited by the difficulty of providing student feedback. In this paper, we present Generative Grading with Neural Approximate Parsing (GG-NAP): a novel approach for providing feedback at scale that is capable of both accurately grading student work while also providing verifiability--a property where the model is able to substantiate its claims with a provable certificate. Our approach uses generative descriptions of student cognition, written as probabilistic programs, to synthesise millions of labelled example solutions to a problem; it then trains inference networks to approximately parse real student solutions according to these generative models. We achieve feedback prediction accuracy comparable to professional human experts in a variety of settings: short-answer questions, programs with graphical output, block-based programming, and short Java programs. In a real classroom, we ran an experiment where humans used GG-NAP to grade, yielding doubled grading accuracy while halving grading time.