 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrustLLM: Trustworthiness in Large Language Models
Paper and Code
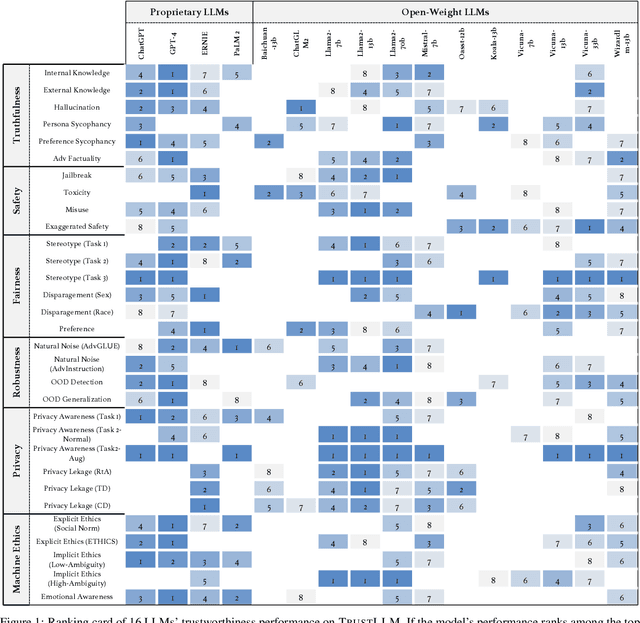


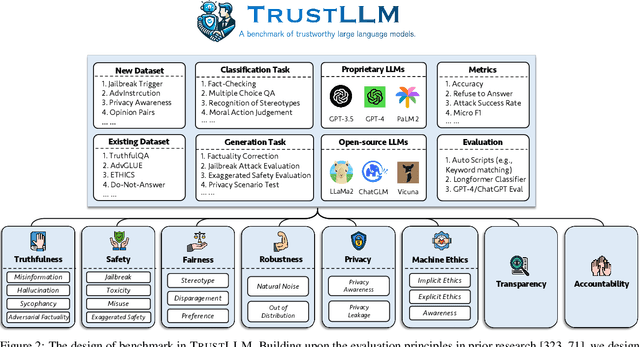
Large language models (LLMs), exemplified by ChatGPT, have gained considerable attention for their excellent natural language processing capabilities. Nonetheless, these LLMs present many challenges, particularly in the realm of trustworthiness. Therefore, ensuring the trustworthiness of LLMs emerges as an important topic. This paper introduces TrustLLM, a comprehensive study of trustworthiness in LLMs, including principles for different dimensions of trustworthiness, established benchmark, evaluation, and analysis of trustworthiness for mainstream LLMs, and discussion of open challenges and future directions. Specifically, we first propose a set of principles for trustworthy LLMs that span eight different dimensions. Based on these principles, we further establish a benchmark across six dimensions including truthfulness, safety, fairness, robustness, privacy, and machine ethics. We then present a study evaluating 16 mainstream LLMs in TrustLLM, consisting of over 30 datasets. Our findings firstly show that in general trustworthiness and utility (i.e., functional effectiveness) are positively related. Secondly, our observations reveal that proprietary LLMs generally outperform most open-source counterparts in terms of trustworthiness, raising concerns about the potential risks of widely accessible open-source LLMs. However, a few open-source LLMs come very close to proprietary ones. Thirdly, it is important to note that some LLMs may be overly calibrated towards exhibiting trustworthiness, to the extent that they compromise their utility by mistakenly treating benign prompts as harmful and consequently not responding. Finally, we emphasize the importance of ensuring transparency not only in the models themselves but also in the technologies that underpin trustworthiness. Knowing the specific trustworthy technologies that have been employed is crucial for analyzing their effectiveness.