 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDC-W2S: Dual-Consensus Weak-to-Strong Training for Reliable Process Reward Modeling in Biological Reasoning
Mar 09, 2026In scientific reasoning tasks, the veracity of the reasoning process is as critical as the final outcome. While Process Reward Models (PRMs) offer a solution to the coarse-grained supervision problems inherent in Outcome Reward Models (ORMs), their deployment is hindered by the prohibitive cost of obtaining expert-verified step-wise labels. This paper addresses the challenge of training reliable PRMs using abundant but noisy "weak" supervision. We argue that existing Weak-to-Strong Generalization (W2SG) theories lack prescriptive guidelines for selecting high-quality training signals from noisy data. To bridge this gap, we introduce the Dual-Consensus Weak-to-Strong (DC-W2S) framework. By intersecting Self-Consensus (SC) metrics among weak supervisors with Neighborhood-Consensus (NC) metrics in the embedding space, we stratify supervision signals into distinct reliability regimes. We then employ a curriculum of instance-level balanced sampling and label-level reliability-aware masking to guide the training process. We demonstrate that DC-W2S enables the training of robust PRMs for complex reasoning without exhaustive expert annotation, proving that strategic data curation is more effective than indiscriminate training on large-scale noisy datasets.
Curriculum Reinforcement Learning from Easy to Hard Tasks Improves LLM Reasoning
Jun 07, 2025We aim to improve the reasoning capabilities of language models via reinforcement learning (RL). Recent RL post-trained models like DeepSeek-R1 have demonstrated reasoning abilities on mathematical and coding tasks. However, prior studies suggest that using RL alone to improve reasoning on inherently difficult tasks is less effective. Here, we draw inspiration from curriculum learning and propose to schedule tasks from easy to hard (E2H), allowing LLMs to build reasoning skills gradually. Our method is termed E2H Reasoner. Empirically, we observe that, although easy tasks are important initially, fading them out through appropriate scheduling is essential in preventing overfitting. Theoretically, we establish convergence guarantees for E2H Reasoner within an approximate policy iteration framework. We derive finite-sample complexity bounds and show that when tasks are appropriately decomposed and conditioned, learning through curriculum stages requires fewer total samples than direct learning. Experiments across multiple domains show that E2H Reasoner significantly improves the reasoning ability of small LLMs (1.5B to 3B), which otherwise struggle when trained with vanilla RL alone, highlighting the effectiveness of our method.
Dynamic Search for Inference-Time Alignment in Diffusion Models
Mar 03, 2025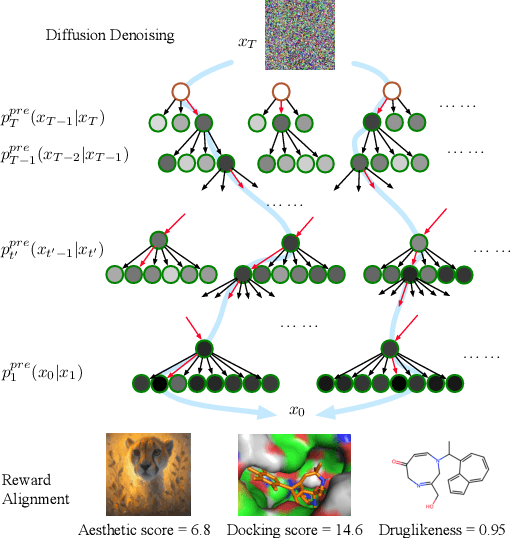
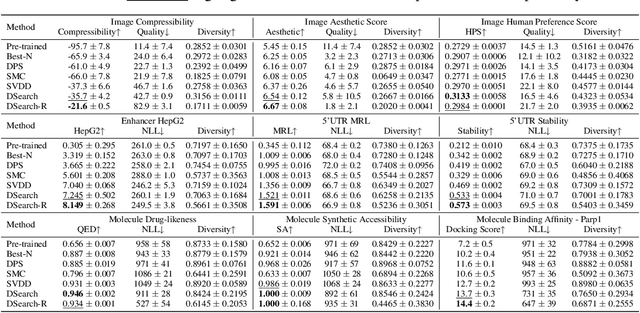
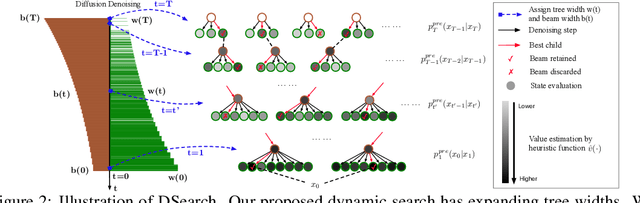

Diffusion models have shown promising generative capabilities across diverse domains, yet aligning their outputs with desired reward functions remains a challenge, particularly in cases where reward functions are non-differentiable. Some gradient-free guidance methods have been developed, but they often struggle to achieve optimal inference-time alignment. In this work, we newly frame inference-time alignment in diffusion as a search problem and propose Dynamic Search for Diffusion (DSearch), which subsamples from denoising processes and approximates intermediate node rewards. It also dynamically adjusts beam width and tree expansion to efficiently explore high-reward generations. To refine intermediate decisions, DSearch incorporates adaptive scheduling based on noise levels and a lookahead heuristic function. We validate DSearch across multiple domains, including biological sequence design, molecular optimization, and image generation, demonstrating superior reward optimization compared to existing approaches.
Reward-Guided Iterative Refinement in Diffusion Models at Test-Time with Applications to Protein and DNA Design
Feb 20, 2025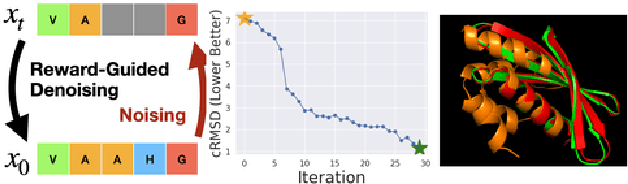
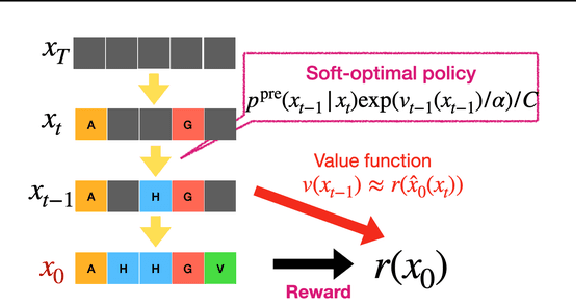
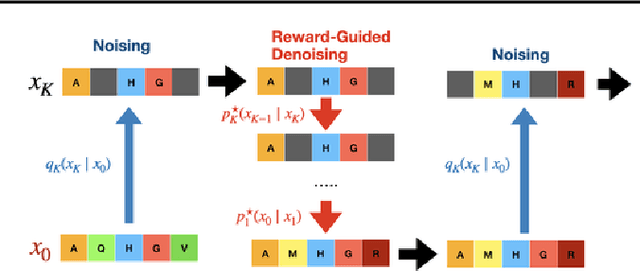
To fully leverage the capabilities of diffusion models, we are often interested in optimizing downstream reward functions during inference. While numerous algorithms for reward-guided generation have been recently proposed due to their significance, current approaches predominantly focus on single-shot generation, transitioning from fully noised to denoised states. We propose a novel framework for inference-time reward optimization with diffusion models inspired by evolutionary algorithms. Our approach employs an iterative refinement process consisting of two steps in each iteration: noising and reward-guided denoising. This sequential refinement allows for the gradual correction of errors introduced during reward optimization. Besides, we provide a theoretical guarantee for our framework. Finally, we demonstrate its superior empirical performance in protein and cell-type-specific regulatory DNA design. The code is available at \href{https://github.com/masa-ue/ProDifEvo-Refinement}{https://github.com/masa-ue/ProDifEvo-Refinement}.
Discovering Physics Laws of Dynamical Systems via Invariant Function Learning
Feb 06, 2025



We consider learning underlying laws of dynamical systems governed by ordinary differential equations (ODE). A key challenge is how to discover intrinsic dynamics across multiple environments while circumventing environment-specific mechanisms. Unlike prior work, we tackle more complex environments where changes extend beyond function coefficients to entirely different function forms. For example, we demonstrate the discovery of ideal pendulum's natural motion $\alpha^2 \sin{\theta_t}$ by observing pendulum dynamics in different environments, such as the damped environment $\alpha^2 \sin(\theta_t) - \rho \omega_t$ and powered environment $\alpha^2 \sin(\theta_t) + \rho \frac{\omega_t}{\left|\omega_t\right|}$. Here, we formulate this problem as an \emph{invariant function learning} task and propose a new method, known as \textbf{D}isentanglement of \textbf{I}nvariant \textbf{F}unctions (DIF), that is grounded in causal analysis. We propose a causal graph and design an encoder-decoder hypernetwork that explicitly disentangles invariant functions from environment-specific dynamics. The discovery of invariant functions is guaranteed by our information-based principle that enforces the independence between extracted invariant functions and environments. Quantitative comparisons with meta-learning and invariant learning baselines on three ODE systems demonstrate the effectiveness and efficiency of our method. Furthermore, symbolic regression explanation results highlight the ability of our framework to uncover intrinsic laws.
Reward-Guided Controlled Generation for Inference-Time Alignment in Diffusion Models: Tutorial and Review
Jan 16, 2025



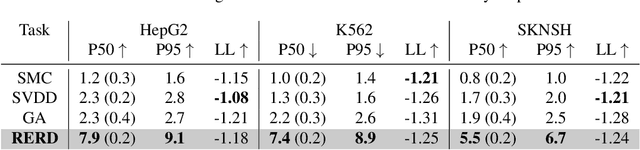
This tutorial provides an in-depth guide on inference-time guidance and alignment methods for optimizing downstream reward functions in diffusion models. While diffusion models are renowned for their generative modeling capabilities, practical applications in fields such as biology often require sample generation that maximizes specific metrics (e.g., stability, affinity in proteins, closeness to target structures). In these scenarios, diffusion models can be adapted not only to generate realistic samples but also to explicitly maximize desired measures at inference time without fine-tuning. This tutorial explores the foundational aspects of such inference-time algorithms. We review these methods from a unified perspective, demonstrating that current techniques -- such as Sequential Monte Carlo (SMC)-based guidance, value-based sampling, and classifier guidance -- aim to approximate soft optimal denoising processes (a.k.a. policies in RL) that combine pre-trained denoising processes with value functions serving as look-ahead functions that predict from intermediate states to terminal rewards. Within this framework, we present several novel algorithms not yet covered in the literature. Furthermore, we discuss (1) fine-tuning methods combined with inference-time techniques, (2) inference-time algorithms based on search algorithms such as Monte Carlo tree search, which have received limited attention in current research, and (3) connections between inference-time algorithms in language models and diffusion models. The code of this tutorial on protein design is available at https://github.com/masa-ue/AlignInversePro
A Hierarchical Language Model For Interpretable Graph Reasoning
Oct 29, 2024Large language models (LLMs) are being increasingly explored for graph tasks. Despite their remarkable success in text-based tasks, LLMs' capabilities in understanding explicit graph structures remain limited, particularly with large graphs. In this work, we introduce Hierarchical Language Model for Graph (HLM-G), which employs a two-block architecture to capture node-centric local information and interaction-centric global structure, effectively enhancing graph structure understanding abilities. The proposed scheme allows LLMs to address various graph queries with high efficacy, efficiency, and robustness, while reducing computational costs on large-scale graph tasks. Furthermore, we demonstrate the interpretability of our model using intrinsic attention weights and established explainers. Comprehensive evaluations across diverse graph reasoning and real-world tasks of node, link, and graph-levels highlight the superiority of our method, marking a significant advancement in the application of LLMs to graph understanding.
Geometry Informed Tokenization of Molecules for Language Model Generation
Aug 19, 2024We consider molecule generation in 3D space using language models (LMs), which requires discrete tokenization of 3D molecular geometries. Although tokenization of molecular graphs exists, that for 3D geometries is largely unexplored. Here, we attempt to bridge this gap by proposing the Geo2Seq, which converts molecular geometries into $SE(3)$-invariant 1D discrete sequences. Geo2Seq consists of canonical labeling and invariant spherical representation steps, which together maintain geometric and atomic fidelity in a format conducive to LMs. Our experiments show that, when coupled with Geo2Seq, various LMs excel in molecular geometry generation, especially in controlled generation tasks.
Derivative-Free Guidance in Continuous and Discrete Diffusion Models with Soft Value-Based Decoding
Aug 15, 2024



Diffusion models excel at capturing the natural design spaces of images, molecules, DNA, RNA, and protein sequences. However, rather than merely generating designs that are natural, we often aim to optimize downstream reward functions while preserving the naturalness of these design spaces. Existing methods for achieving this goal often require ``differentiable'' proxy models (\textit{e.g.}, classifier guidance or DPS) or involve computationally expensive fine-tuning of diffusion models (\textit{e.g.}, classifier-free guidance, RL-based fine-tuning). In our work, we propose a new method to address these challenges. Our algorithm is an iterative sampling method that integrates soft value functions, which looks ahead to how intermediate noisy states lead to high rewards in the future, into the standard inference procedure of pre-trained diffusion models. Notably, our approach avoids fine-tuning generative models and eliminates the need to construct differentiable models. This enables us to (1) directly utilize non-differentiable features/reward feedback, commonly used in many scientific domains, and (2) apply our method to recent discrete diffusion models in a principled way. Finally, we demonstrate the effectiveness of our algorithm across several domains, including image generation, molecule generation, and DNA/RNA sequence generation. The code is available at \href{https://github.com/masa-ue/SVDD}{https://github.com/masa-ue/SVDD}.
Eliminating Position Bias of Language Models: A Mechanistic Approach
Jul 01, 2024
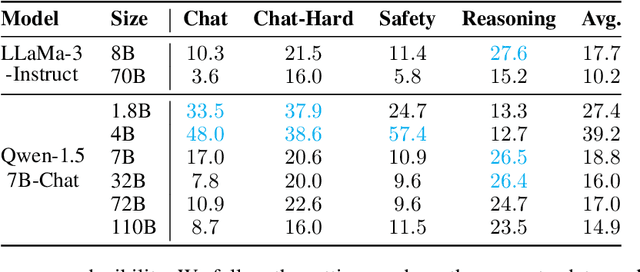


Position bias has proven to be a prevalent issue of modern language models (LMs), where the models prioritize content based on its position within the given context. This bias often leads to unexpected model failures and hurts performance, robustness, and reliability across various applications. Our mechanistic analysis attributes the position bias to two components employed in nearly all state-of-the-art LMs: causal attention and relative positional encodings. Specifically, we find that causal attention generally causes models to favor distant content, while relative positional encodings like RoPE prefer nearby ones based on the analysis of retrieval-augmented question answering (QA). Further, our empirical study on object detection reveals that position bias is also present in vision-language models (VLMs). Based on the above analyses, we propose to ELIMINATE position bias caused by different input segment orders (e.g., options in LM-as-a-judge, retrieved documents in QA) in a TRAINING-FREE ZERO-SHOT manner. Our method changes the causal attention to bidirectional attention between segments and utilizes model attention values to decide the relative orders of segments instead of using the order provided in input prompts, therefore enabling Position-INvariant inferencE (PINE) at the segment level. By eliminating position bias, models achieve better performance and reliability in downstream tasks where position bias widely exists, such as LM-as-a-judge and retrieval-augmented QA. Notably, PINE is especially useful when adapting LMs for evaluating reasoning pairs: it consistently provides 8 to 10 percentage points performance gains in most cases, and makes Llama-3-70B-Instruct perform even better than GPT-4-0125-preview on the RewardBench reasoning subset.