 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA mechanistically interpretable neural network for regulatory genomics
Oct 08, 2024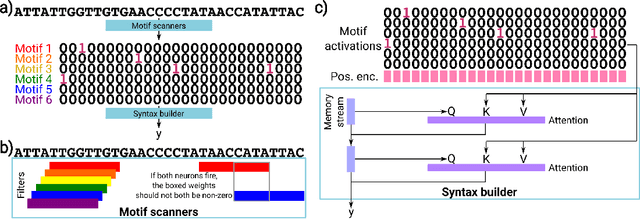
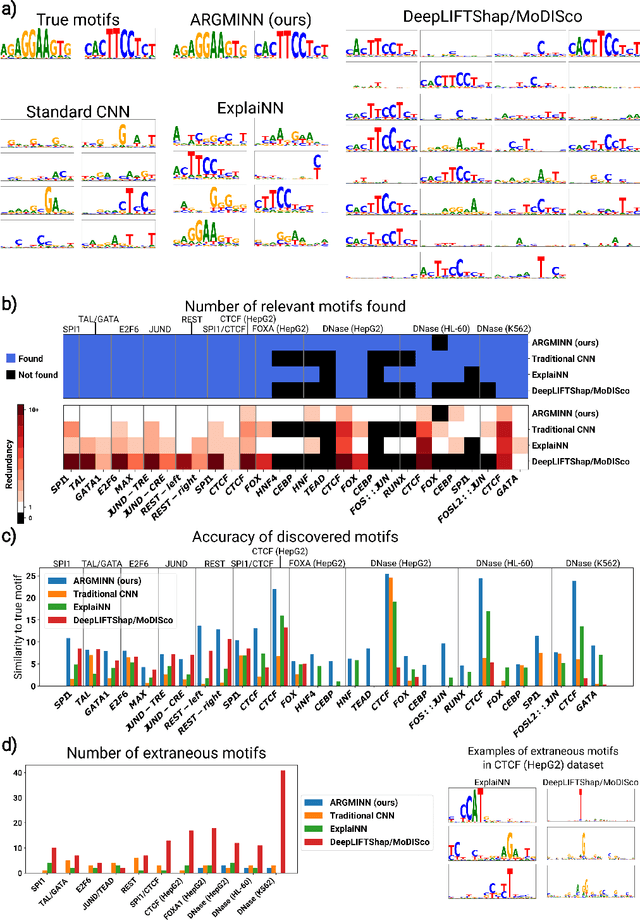

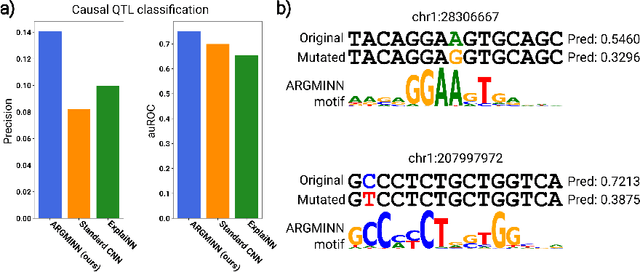
Deep neural networks excel in mapping genomic DNA sequences to associated readouts (e.g., protein-DNA binding). Beyond prediction, the goal of these networks is to reveal to scientists the underlying motifs (and their syntax) which drive genome regulation. Traditional methods that extract motifs from convolutional filters suffer from the uninterpretable dispersion of information across filters and layers. Other methods which rely on importance scores can be unstable and unreliable. Instead, we designed a novel mechanistically interpretable architecture for regulatory genomics, where motifs and their syntax are directly encoded and readable from the learned weights and activations. We provide theoretical and empirical evidence of our architecture's full expressivity, while still being highly interpretable. Through several experiments, we show that our architecture excels in de novo motif discovery and motif instance calling, is robust to variable sequence contexts, and enables fully interpretable generation of novel functional sequences.
Derivative-Free Guidance in Continuous and Discrete Diffusion Models with Soft Value-Based Decoding
Aug 15, 2024



Diffusion models excel at capturing the natural design spaces of images, molecules, DNA, RNA, and protein sequences. However, rather than merely generating designs that are natural, we often aim to optimize downstream reward functions while preserving the naturalness of these design spaces. Existing methods for achieving this goal often require ``differentiable'' proxy models (\textit{e.g.}, classifier guidance or DPS) or involve computationally expensive fine-tuning of diffusion models (\textit{e.g.}, classifier-free guidance, RL-based fine-tuning). In our work, we propose a new method to address these challenges. Our algorithm is an iterative sampling method that integrates soft value functions, which looks ahead to how intermediate noisy states lead to high rewards in the future, into the standard inference procedure of pre-trained diffusion models. Notably, our approach avoids fine-tuning generative models and eliminates the need to construct differentiable models. This enables us to (1) directly utilize non-differentiable features/reward feedback, commonly used in many scientific domains, and (2) apply our method to recent discrete diffusion models in a principled way. Finally, we demonstrate the effectiveness of our algorithm across several domains, including image generation, molecule generation, and DNA/RNA sequence generation. The code is available at \href{https://github.com/masa-ue/SVDD}{https://github.com/masa-ue/SVDD}.