 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA mechanistically interpretable neural network for regulatory genomics
Paper and Code
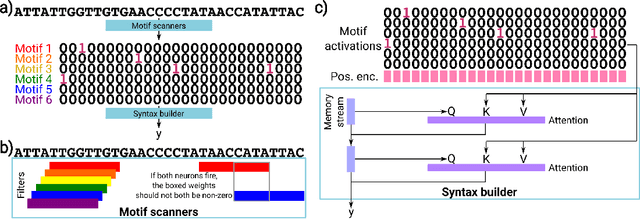
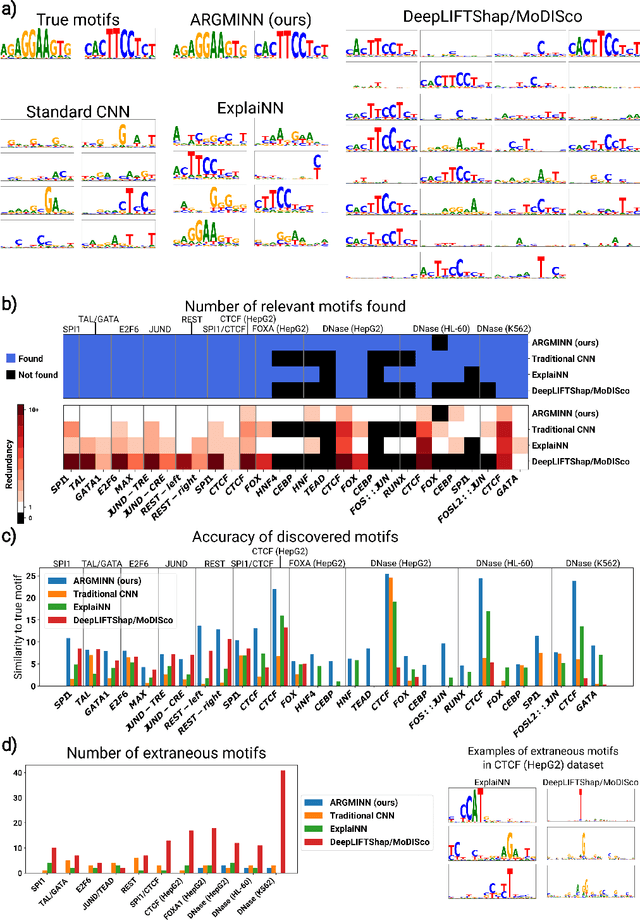

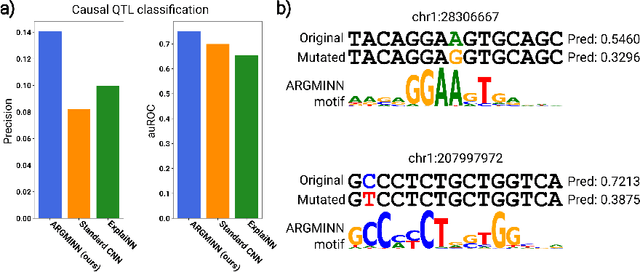
Deep neural networks excel in mapping genomic DNA sequences to associated readouts (e.g., protein-DNA binding). Beyond prediction, the goal of these networks is to reveal to scientists the underlying motifs (and their syntax) which drive genome regulation. Traditional methods that extract motifs from convolutional filters suffer from the uninterpretable dispersion of information across filters and layers. Other methods which rely on importance scores can be unstable and unreliable. Instead, we designed a novel mechanistically interpretable architecture for regulatory genomics, where motifs and their syntax are directly encoded and readable from the learned weights and activations. We provide theoretical and empirical evidence of our architecture's full expressivity, while still being highly interpretable. Through several experiments, we show that our architecture excels in de novo motif discovery and motif instance calling, is robust to variable sequence contexts, and enables fully interpretable generation of novel functional sequences.