 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeon: News Entity-Interaction Extraction for Enhanced Question Answering
Nov 20, 2024



Capturing fresh information in near real-time and using it to augment existing large language models (LLMs) is essential to generate up-to-date, grounded, and reliable output. This problem becomes particularly challenging when LLMs are used for informational tasks in rapidly evolving fields, such as Web search related to recent or unfolding events involving entities, where generating temporally relevant responses requires access to up-to-the-hour news sources. However, the information modeled by the parametric memory of LLMs is often outdated, and Web results from prototypical retrieval systems may fail to capture the latest relevant information and struggle to handle conflicting reports in evolving news. To address this challenge, we present the NEON framework, designed to extract emerging entity interactions -- such as events or activities -- as described in news articles. NEON constructs an entity-centric timestamped knowledge graph that captures such interactions, thereby facilitating enhanced QA capabilities related to news events. Our framework innovates by integrating open Information Extraction (openIE) style tuples into LLMs to enable in-context retrieval-augmented generation. This integration demonstrates substantial improvements in QA performance when tackling temporal, entity-centric search queries. Through NEON, LLMs can deliver more accurate, reliable, and up-to-date responses.
Recall Them All: Retrieval-Augmented Language Models for Long Object List Extraction from Long Documents
May 04, 2024



Methods for relation extraction from text mostly focus on high precision, at the cost of limited recall. High recall is crucial, though, to populate long lists of object entities that stand in a specific relation with a given subject. Cues for relevant objects can be spread across many passages in long texts. This poses the challenge of extracting long lists from long texts. We present the L3X method which tackles the problem in two stages: (1) recall-oriented generation using a large language model (LLM) with judicious techniques for retrieval augmentation, and (2) precision-oriented scrutinization to validate or prune candidates. Our L3X method outperforms LLM-only generations by a substantial margin.
Large Language Models and Knowledge Graphs: Opportunities and Challenges
Aug 11, 2023Large Language Models (LLMs) have taken Knowledge Representation -- and the world -- by storm. This inflection point marks a shift from explicit knowledge representation to a renewed focus on the hybrid representation of both explicit knowledge and parametric knowledge. In this position paper, we will discuss some of the common debate points within the community on LLMs (parametric knowledge) and Knowledge Graphs (explicit knowledge) and speculate on opportunities and visions that the renewed focus brings, as well as related research topics and challenges.
Extracting Multi-valued Relations from Language Models
Jul 07, 2023



The widespread usage of latent language representations via pre-trained language models (LMs) suggests that they are a promising source of structured knowledge. However, existing methods focus only on a single object per subject-relation pair, even though often multiple objects are correct. To overcome this limitation, we analyze these representations for their potential to yield materialized multi-object relational knowledge. We formulate the problem as a rank-then-select task. For ranking candidate objects, we evaluate existing prompting techniques and propose new ones incorporating domain knowledge. Among the selection methods, we find that choosing objects with a likelihood above a learned relation-specific threshold gives a 49.5% F1 score. Our results highlight the difficulty of employing LMs for the multi-valued slot-filling task and pave the way for further research on extracting relational knowledge from latent language representations.
3HAN: A Deep Neural Network for Fake News Detection
Jun 21, 2023The rapid spread of fake news is a serious problem calling for AI solutions. We employ a deep learning based automated detector through a three level hierarchical attention network (3HAN) for fast, accurate detection of fake news. 3HAN has three levels, one each for words, sentences, and the headline, and constructs a news vector: an effective representation of an input news article, by processing an article in an hierarchical bottom-up manner. The headline is known to be a distinguishing feature of fake news, and furthermore, relatively few words and sentences in an article are more important than the rest. 3HAN gives a differential importance to parts of an article, on account of its three layers of attention. By experiments on a large real-world data set, we observe the effectiveness of 3HAN with an accuracy of 96.77%. Unlike some other deep learning models, 3HAN provides an understandable output through the attention weights given to different parts of an article, which can be visualized through a heatmap to enable further manual fact checking.
Evaluating Language Models for Knowledge Base Completion
Mar 20, 2023



Structured knowledge bases (KBs) are a foundation of many intelligent applications, yet are notoriously incomplete. Language models (LMs) have recently been proposed for unsupervised knowledge base completion (KBC), yet, despite encouraging initial results, questions regarding their suitability remain open. Existing evaluations often fall short because they only evaluate on popular subjects, or sample already existing facts from KBs. In this work, we introduce a novel, more challenging benchmark dataset, and a methodology tailored for a realistic assessment of the KBC potential of LMs. For automated assessment, we curate a dataset called WD-KNOWN, which provides an unbiased random sample of Wikidata, containing over 3.9 million facts. In a second step, we perform a human evaluation on predictions that are not yet in the KB, as only this provides real insights into the added value over existing KBs. Our key finding is that biases in dataset conception of previous benchmarks lead to a systematic overestimate of LM performance for KBC. However, our results also reveal strong areas of LMs. We could, for example, perform a significant completion of Wikidata on the relations nativeLanguage, by a factor of ~21 (from 260k to 5.8M) at 82% precision, usedLanguage, by a factor of ~2.1 (from 2.1M to 6.6M) at 82% precision, and citizenOf by a factor of ~0.3 (from 4.2M to 5.3M) at 90% precision. Moreover, we find that LMs possess surprisingly strong generalization capabilities: even on relations where most facts were not directly observed in LM training, prediction quality can be high.
* Data and code available at https://github.com/bveseli/LMsForKBC
Predicting Document Coverage for Relation Extraction
Nov 26, 2021
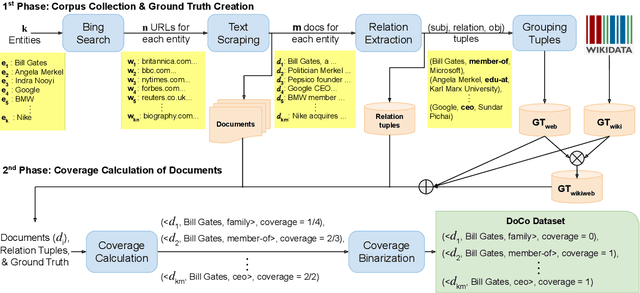
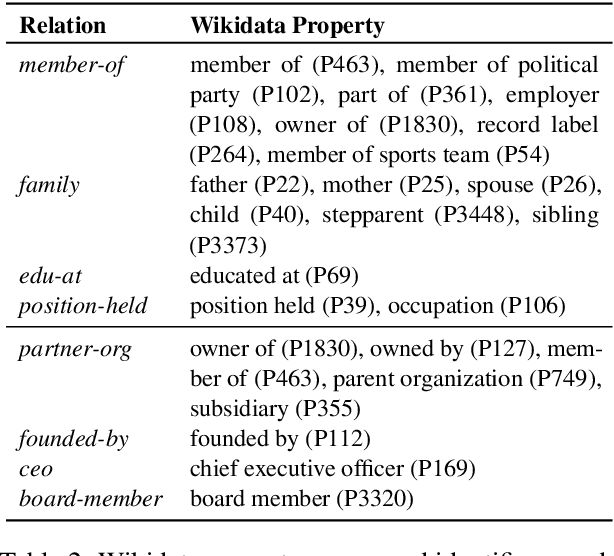
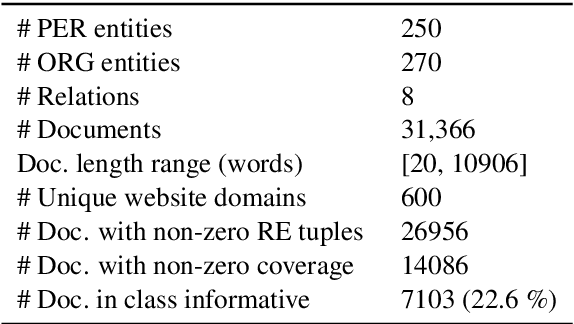
This paper presents a new task of predicting the coverage of a text document for relation extraction (RE): does the document contain many relational tuples for a given entity? Coverage predictions are useful in selecting the best documents for knowledge base construction with large input corpora. To study this problem, we present a dataset of 31,366 diverse documents for 520 entities. We analyze the correlation of document coverage with features like length, entity mention frequency, Alexa rank, language complexity and information retrieval scores. Each of these features has only moderate predictive power. We employ methods combining features with statistical models like TF-IDF and language models like BERT. The model combining features and BERT, HERB, achieves an F1 score of up to 46%. We demonstrate the utility of coverage predictions on two use cases: KB construction and claim refutation.