 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredicting Document Coverage for Relation Extraction
Paper and Code

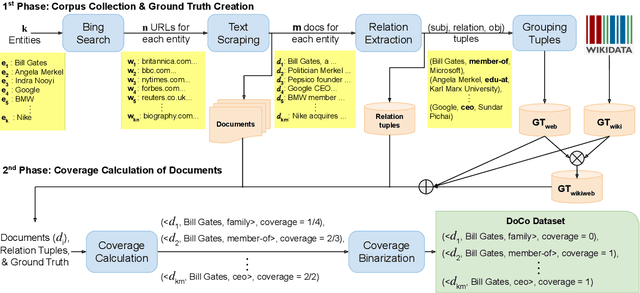
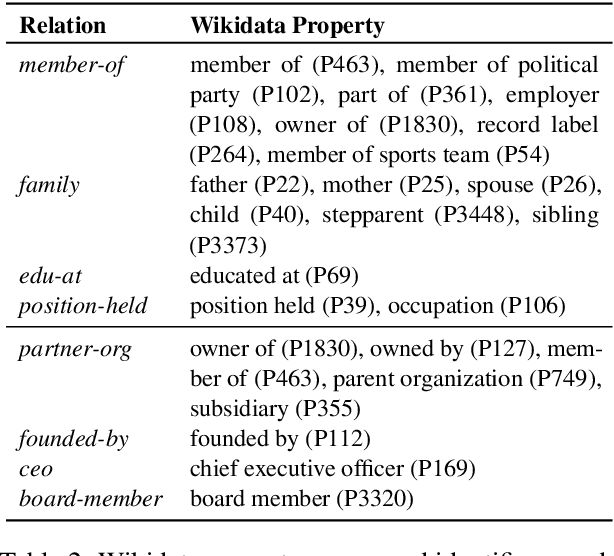
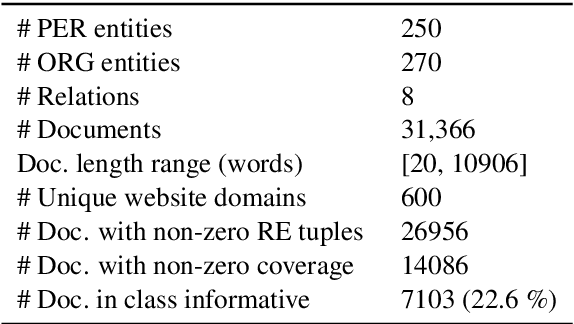
This paper presents a new task of predicting the coverage of a text document for relation extraction (RE): does the document contain many relational tuples for a given entity? Coverage predictions are useful in selecting the best documents for knowledge base construction with large input corpora. To study this problem, we present a dataset of 31,366 diverse documents for 520 entities. We analyze the correlation of document coverage with features like length, entity mention frequency, Alexa rank, language complexity and information retrieval scores. Each of these features has only moderate predictive power. We employ methods combining features with statistical models like TF-IDF and language models like BERT. The model combining features and BERT, HERB, achieves an F1 score of up to 46%. We demonstrate the utility of coverage predictions on two use cases: KB construction and claim refutation.