 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDissecting Paraphrases: The Impact of Prompt Syntax and supplementary Information on Knowledge Retrieval from Pretrained Language Models
Apr 02, 2024



Pre-trained Language Models (PLMs) are known to contain various kinds of knowledge. One method to infer relational knowledge is through the use of cloze-style prompts, where a model is tasked to predict missing subjects or objects. Typically, designing these prompts is a tedious task because small differences in syntax or semantics can have a substantial impact on knowledge retrieval performance. Simultaneously, evaluating the impact of either prompt syntax or information is challenging due to their interdependence. We designed CONPARE-LAMA - a dedicated probe, consisting of 34 million distinct prompts that facilitate comparison across minimal paraphrases. These paraphrases follow a unified meta-template enabling the controlled variation of syntax and semantics across arbitrary relations. CONPARE-LAMA enables insights into the independent impact of either syntactical form or semantic information of paraphrases on the knowledge retrieval performance of PLMs. Extensive knowledge retrieval experiments using our probe reveal that prompts following clausal syntax have several desirable properties in comparison to appositive syntax: i) they are more useful when querying PLMs with a combination of supplementary information, ii) knowledge is more consistently recalled across different combinations of supplementary information, and iii) they decrease response uncertainty when retrieving known facts. In addition, range information can boost knowledge retrieval performance more than domain information, even though domain information is more reliably helpful across syntactic forms.
Large Language Models and Knowledge Graphs: Opportunities and Challenges
Aug 11, 2023Large Language Models (LLMs) have taken Knowledge Representation -- and the world -- by storm. This inflection point marks a shift from explicit knowledge representation to a renewed focus on the hybrid representation of both explicit knowledge and parametric knowledge. In this position paper, we will discuss some of the common debate points within the community on LLMs (parametric knowledge) and Knowledge Graphs (explicit knowledge) and speculate on opportunities and visions that the renewed focus brings, as well as related research topics and challenges.
The FAIRy Tale of Genetic Algorithms
Apr 29, 2023



Genetic Algorithm (GA) is a popular meta-heuristic evolutionary algorithm that uses stochastic operators to find optimal solution and has proved its effectiveness in solving many complex optimization problems (such as classification, optimization, and scheduling). However, despite its performance, popularity and simplicity, not much attention has been paid towards reproducibility and reusability of GA. In this paper, we have extended Findable, Accessible, Interoperable and Reusable (FAIR) data principles to enable the reproducibility and reusability of algorithms. We have chosen GA as a usecase to the demonstrate the applicability of the proposed principles. Also we have presented an overview of methodological developments and variants of GA that makes it challenging to reproduce or even find the right source. Additionally, to enable FAIR algorithms, we propose a vocabulary (i.e. $evo$) using light weight RDF format, facilitating the reproducibility. Given the stochastic nature of GAs, this work can be extended to numerous Optimization and machine learning algorithms/methods.
The KEEN Universe: An Ecosystem for Knowledge Graph Embeddings with a Focus on Reproducibility and Transferability
Jan 28, 2020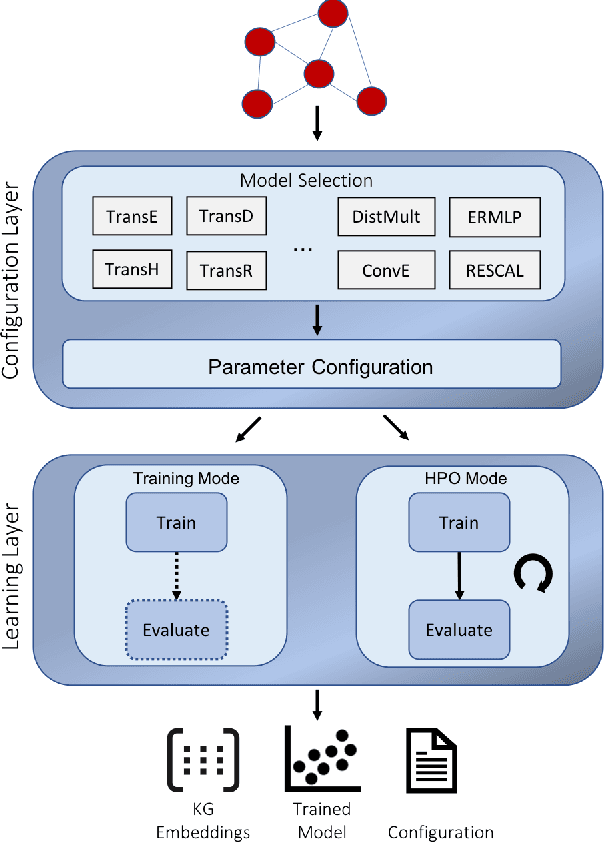
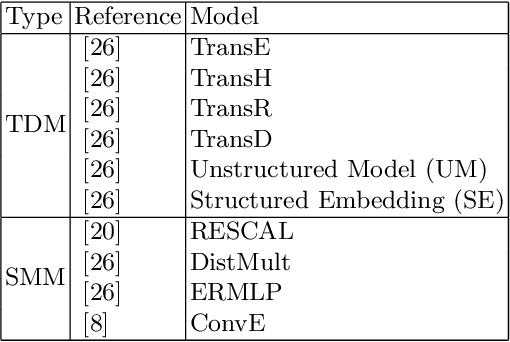
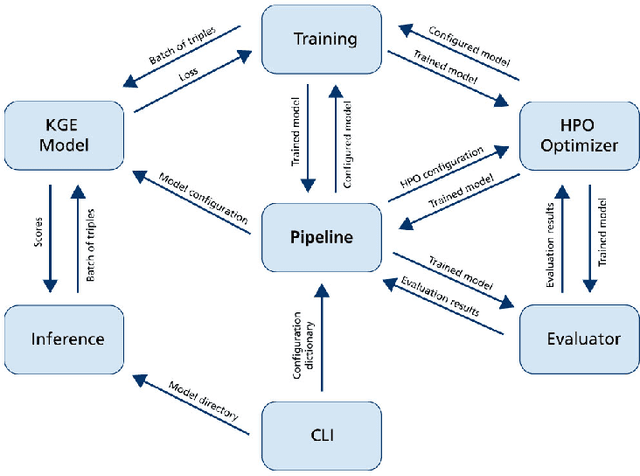
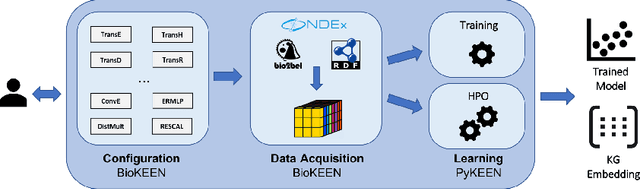
There is an emerging trend of embedding knowledge graphs (KGs) in continuous vector spaces in order to use those for machine learning tasks. Recently, many knowledge graph embedding (KGE) models have been proposed that learn low dimensional representations while trying to maintain the structural properties of the KGs such as the similarity of nodes depending on their edges to other nodes. KGEs can be used to address tasks within KGs such as the prediction of novel links and the disambiguation of entities. They can also be used for downstream tasks like question answering and fact-checking. Overall, these tasks are relevant for the semantic web community. Despite their popularity, the reproducibility of KGE experiments and the transferability of proposed KGE models to research fields outside the machine learning community can be a major challenge. Therefore, we present the KEEN Universe, an ecosystem for knowledge graph embeddings that we have developed with a strong focus on reproducibility and transferability. The KEEN Universe currently consists of the Python packages PyKEEN (Python KnowlEdge EmbeddiNgs), BioKEEN (Biological KnowlEdge EmbeddiNgs), and the KEEN Model Zoo for sharing trained KGE models with the community.