 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Learning in Early Alzheimers diseases Detection: A Comprehensive Survey of Classification, Segmentation, and Feature Extraction Methods
Jan 25, 2025
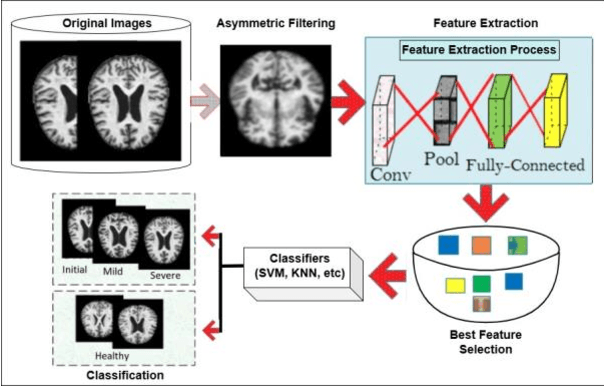


Alzheimers disease is a deadly neurological condition, impairing important memory and brain functions. Alzheimers disease promotes brain shrinkage, ultimately leading to dementia. Dementia diagnosis typically takes 2.8 to 4.4 years after the first clinical indication. Advancements in computing and information technology have led to many techniques of studying Alzheimers disease. Early identification and therapy are crucial for preventing Alzheimers disease, as early-onset dementia hits people before the age of 65, while late-onset dementia occurs after this age. According to the 2015 World Alzheimers disease Report, there are 46.8 million individuals worldwide suffering from dementia, with an anticipated 74.7 million more by 2030 and 131.5 million by 2050. Deep Learning has outperformed conventional Machine Learning techniques by identifying intricate structures in high-dimensional data. Convolutional Neural Network (CNN) and Recurrent Neural Network (RNN), have achieved an accuracy of up to 96.0% for Alzheimers disease classification, and 84.2% for mild cognitive impairment (MCI) conversion prediction. There have been few literature surveys available on applying ML to predict dementia, lacking in congenital observations. However, this survey has focused on a specific data channel for dementia detection. This study evaluated Deep Learning algorithms for early Alzheimers disease detection, using openly accessible datasets, feature segmentation, and classification methods. This article also has identified research gaps and limits in detecting Alzheimers disease, which can inform future research.
The FAIRy Tale of Genetic Algorithms
Apr 29, 2023



Genetic Algorithm (GA) is a popular meta-heuristic evolutionary algorithm that uses stochastic operators to find optimal solution and has proved its effectiveness in solving many complex optimization problems (such as classification, optimization, and scheduling). However, despite its performance, popularity and simplicity, not much attention has been paid towards reproducibility and reusability of GA. In this paper, we have extended Findable, Accessible, Interoperable and Reusable (FAIR) data principles to enable the reproducibility and reusability of algorithms. We have chosen GA as a usecase to the demonstrate the applicability of the proposed principles. Also we have presented an overview of methodological developments and variants of GA that makes it challenging to reproduce or even find the right source. Additionally, to enable FAIR algorithms, we propose a vocabulary (i.e. $evo$) using light weight RDF format, facilitating the reproducibility. Given the stochastic nature of GAs, this work can be extended to numerous Optimization and machine learning algorithms/methods.