 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSAiW: Source-Attributable Invisible Watermarking for Proactive Deepfake Defense
Mar 24, 2026Deepfakes generated by modern generative models pose a serious threat to information integrity, digital identity, and public trust. Existing detection methods are largely reactive, attempting to identify manipulations after they occur and often failing to generalize across evolving generation techniques. This motivates the need for proactive mechanisms that secure media authenticity at the time of creation. In this work, we introduce SAiW, a Source-Attributed Invisible watermarking Framework for proactive deepfake defense and media provenance verification. Unlike conventional watermarking methods that treat watermark payloads as generic signals, SAiW formulates watermark embedding as a source-conditioned representation learning problem, where watermark identity encodes the originating source and modulates the embedding process to produce discriminative and traceable signatures. The framework integrates feature-wise linear modulation to inject source identity into the embedding network, enabling scalable multi-source watermark generation. A perceptual guidance module derived from human visual system priors ensures that watermark perturbations remain visually imperceptible while maintaining robustness. In addition, a dual-purpose forensic decoder simultaneously reconstructs the embedded watermark and performs source attribution, providing both automated verification and interpretable forensic evidence. Extensive experiments across multiple deepfake datasets demonstrate that SAiW achieves high perceptual quality while maintaining strong robustness against compression, filtering, noise, geometric transformations, and adversarial perturbations. By binding digital media to its origin through invisible yet verifiable markers, SAiW enables reliable authentication and source attribution, providing a scalable foundation for proactive deepfake defense and trustworthy media provenance.
Deep Learning in Early Alzheimers diseases Detection: A Comprehensive Survey of Classification, Segmentation, and Feature Extraction Methods
Jan 25, 2025
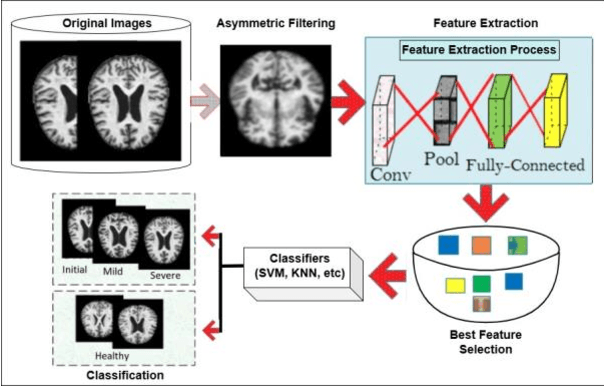


Alzheimers disease is a deadly neurological condition, impairing important memory and brain functions. Alzheimers disease promotes brain shrinkage, ultimately leading to dementia. Dementia diagnosis typically takes 2.8 to 4.4 years after the first clinical indication. Advancements in computing and information technology have led to many techniques of studying Alzheimers disease. Early identification and therapy are crucial for preventing Alzheimers disease, as early-onset dementia hits people before the age of 65, while late-onset dementia occurs after this age. According to the 2015 World Alzheimers disease Report, there are 46.8 million individuals worldwide suffering from dementia, with an anticipated 74.7 million more by 2030 and 131.5 million by 2050. Deep Learning has outperformed conventional Machine Learning techniques by identifying intricate structures in high-dimensional data. Convolutional Neural Network (CNN) and Recurrent Neural Network (RNN), have achieved an accuracy of up to 96.0% for Alzheimers disease classification, and 84.2% for mild cognitive impairment (MCI) conversion prediction. There have been few literature surveys available on applying ML to predict dementia, lacking in congenital observations. However, this survey has focused on a specific data channel for dementia detection. This study evaluated Deep Learning algorithms for early Alzheimers disease detection, using openly accessible datasets, feature segmentation, and classification methods. This article also has identified research gaps and limits in detecting Alzheimers disease, which can inform future research.
A Multi-Scale Feature Extraction and Fusion Deep Learning Method for Classification of Wheat Diseases
Jan 17, 2025
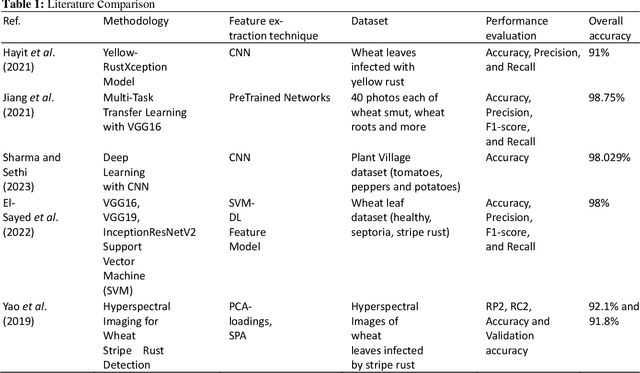
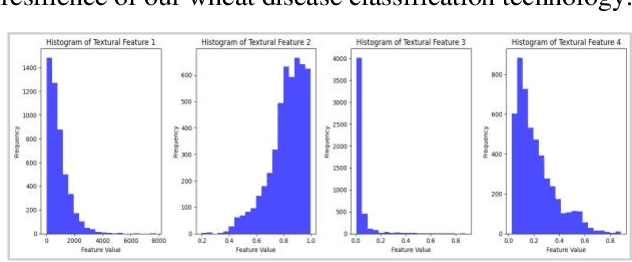
Wheat is an important source of dietary fiber and protein that is negatively impacted by a number of risks to its growth. The difficulty of identifying and classifying wheat diseases is discussed with an emphasis on wheat loose smut, leaf rust, and crown and root rot. Addressing conditions like crown and root rot, this study introduces an innovative approach that integrates multi-scale feature extraction with advanced image segmentation techniques to enhance classification accuracy. The proposed method uses neural network models Xception, Inception V3, and ResNet 50 to train on a large wheat disease classification dataset 2020 in conjunction with an ensemble of machine vision classifiers, including voting and stacking. The study shows that the suggested methodology has a superior accuracy of 99.75% in the classification of wheat diseases when compared to current state-of-the-art approaches. A deep learning ensemble model Xception showed the highest accuracy.
Towards Inclusive Face Recognition Through Synthetic Ethnicity Alteration
May 02, 2024



Numerous studies have shown that existing Face Recognition Systems (FRS), including commercial ones, often exhibit biases toward certain ethnicities due to under-represented data. In this work, we explore ethnicity alteration and skin tone modification using synthetic face image generation methods to increase the diversity of datasets. We conduct a detailed analysis by first constructing a balanced face image dataset representing three ethnicities: Asian, Black, and Indian. We then make use of existing Generative Adversarial Network-based (GAN) image-to-image translation and manifold learning models to alter the ethnicity from one to another. A systematic analysis is further conducted to assess the suitability of such datasets for FRS by studying the realistic skin-tone representation using Individual Typology Angle (ITA). Further, we also analyze the quality characteristics using existing Face image quality assessment (FIQA) approaches. We then provide a holistic FRS performance analysis using four different systems. Our findings pave the way for future research works in (i) developing both specific ethnicity and general (any to any) ethnicity alteration models, (ii) expanding such approaches to create databases with diverse skin tones, (iii) creating datasets representing various ethnicities which further can help in mitigating bias while addressing privacy concerns.
* 8 Pages
Deepfake Video Detection Using Generative Convolutional Vision Transformer
Jul 13, 2023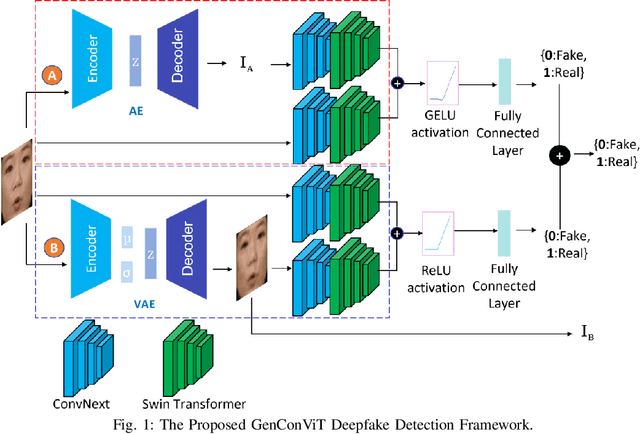

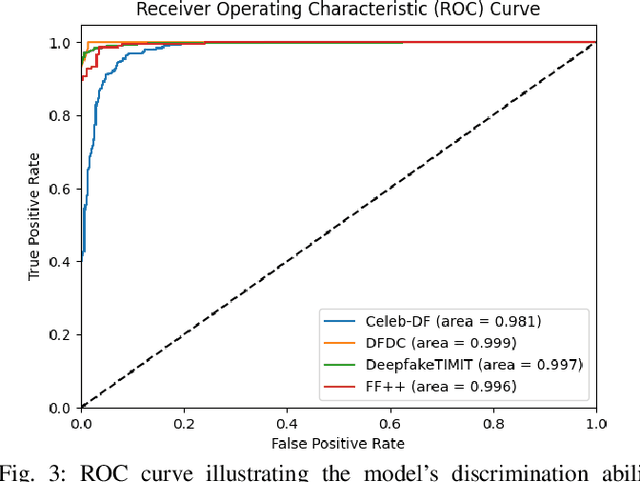
Deepfakes have raised significant concerns due to their potential to spread false information and compromise digital media integrity. In this work, we propose a Generative Convolutional Vision Transformer (GenConViT) for deepfake video detection. Our model combines ConvNeXt and Swin Transformer models for feature extraction, and it utilizes Autoencoder and Variational Autoencoder to learn from the latent data distribution. By learning from the visual artifacts and latent data distribution, GenConViT achieves improved performance in detecting a wide range of deepfake videos. The model is trained and evaluated on DFDC, FF++, DeepfakeTIMIT, and Celeb-DF v2 datasets, achieving high classification accuracy, F1 scores, and AUC values. The proposed GenConViT model demonstrates robust performance in deepfake video detection, with an average accuracy of 95.8% and an AUC value of 99.3% across the tested datasets. Our proposed model addresses the challenge of generalizability in deepfake detection by leveraging visual and latent features and providing an effective solution for identifying a wide range of fake videos while preserving media integrity. The code for GenConViT is available at https://github.com/erprogs/GenConViT.
Longitudinal Analysis of Mask and No-Mask on Child Face Recognition
Nov 19, 2021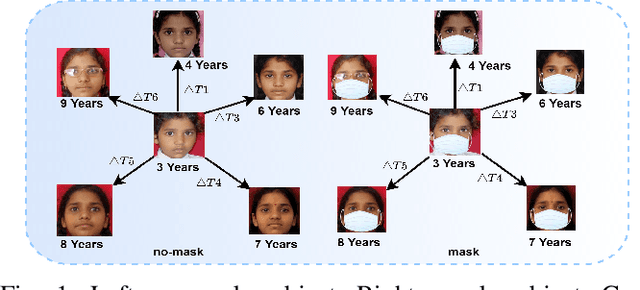
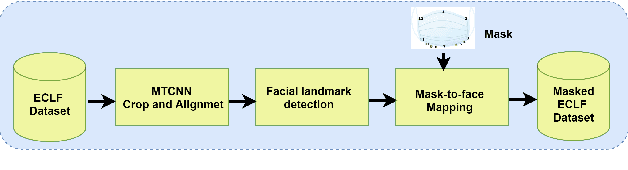
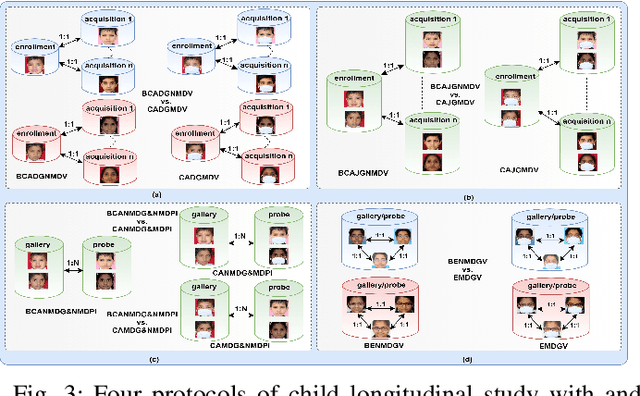
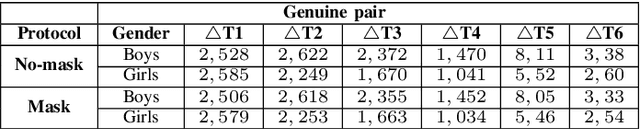
Face is one of the most widely employed traits for person recognition, even in many large-scale applications. Despite technological advancements in face recognition systems, they still face obstacles caused by pose, expression, occlusion, and aging variations. Owing to the COVID-19 pandemic, contactless identity verification has become exceedingly vital. To constrain the pandemic, people have started using face mask. Recently, few studies have been conducted on the effect of face mask on adult face recognition systems. However, the impact of aging with face mask on child subject recognition has not been adequately explored. Thus, the main objective of this study is analyzing the child longitudinal impact together with face mask and other covariates on face recognition systems. Specifically, we performed a comparative investigation of three top performing publicly available face matchers and a post-COVID-19 commercial-off-the-shelf (COTS) system under child cross-age verification and identification settings using our generated synthetic mask and no-mask samples. Furthermore, we investigated the longitudinal consequence of eyeglasses with mask and no-mask. The study exploited no-mask longitudinal child face dataset (i.e., extended Indian Child Longitudinal Face Dataset) that contains $26,258$ face images of $7,473$ subjects in the age group of $[2, 18]$ over an average time span of $3.35$ years. Due to the combined effects of face mask and face aging, the FaceNet, PFE, ArcFace, and COTS face verification system accuracies decrease approximately $25\%$, $22\%$, $18\%$, $12\%$, respectively.
Determining Sequence of Image Processing Technique (IPT) to Detect Adversarial Attacks
Jul 07, 2020



Developing secure machine learning models from adversarial examples is challenging as various methods are continually being developed to generate adversarial attacks. In this work, we propose an evolutionary approach to automatically determine Image Processing Techniques Sequence (IPTS) for detecting malicious inputs. Accordingly, we first used a diverse set of attack methods including adaptive attack methods (on our defense) to generate adversarial samples from the clean dataset. A detection framework based on a genetic algorithm (GA) is developed to find the optimal IPTS, where the optimality is estimated by different fitness measures such as Euclidean distance, entropy loss, average histogram, local binary pattern and loss functions. The "image difference" between the original and processed images is used to extract the features, which are then fed to a classification scheme in order to determine whether the input sample is adversarial or clean. This paper described our methodology and performed experiments using multiple data-sets tested with several adversarial attacks. For each attack-type and dataset, it generates unique IPTS. A set of IPTS selected dynamically in testing time which works as a filter for the adversarial attack. Our empirical experiments exhibited promising results indicating the approach can efficiently be used as processing for any AI model.
Generalizable Adversarial Examples Detection Based on Bi-model Decision Mismatch
Mar 06, 2018


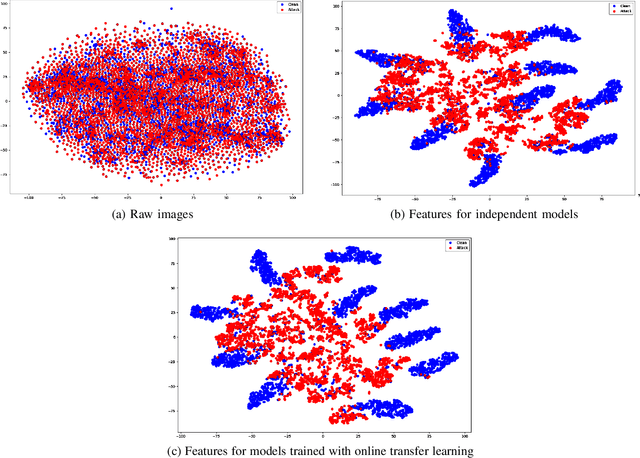
Deep neural networks (DNNs) have shown phenomenal success in a wide range of applications. However, recent studies have discovered that they are vulnerable to Adversarial Examples, i.e., original samples with added subtle perturbations. Such perturbations are often too small and imperceptible to humans, yet they can easily fool the neural networks. Few defense techniques against adversarial examples have been proposed, but they require modifying the target model or prior knowledge of adversarial examples generation methods. Likewise, their performance remarkably drops upon encountering adversarial example types not used during the training stage. In this paper, we propose a new framework that can be used to enhance DNNs' robustness by detecting adversarial examples. In particular, we employ the decision layer of independently trained models as features for posterior detection. The proposed framework doesn't require any prior knowledge of adversarial examples generation techniques, and can be directly augmented with unmodified off-the-shelf models. Experiments on the standard MNIST and CIFAR10 datasets show that it generalizes well across not only different adversarial examples generation methods but also various additive perturbations. Specifically, distinct binary classifiers trained on top of our proposed features can achieve a high detection rate (>90%) in a set of white-box attacks and maintain this performance when tested against unseen attacks.