 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Network Intrusion Detection Systems: A Multi-Layer Ensemble Approach to Mitigate Adversarial Attacks
Mar 11, 2026Adversarial examples can represent a serious threat to machine learning (ML) algorithms. If used to manipulate the behaviour of ML-based Network Intrusion Detection Systems (NIDS), they can jeopardize network security. In this work, we aim to mitigate such risks by increasing the robustness of NIDS towards adversarial attacks. To that end, we explore two adversarial methods for generating malicious network traffic. The first method is based on Generative Adversarial Networks (GAN) and the second one is the Fast Gradient Sign Method (FGSM). The adversarial examples generated by these methods are then used to evaluate a novel multilayer defense mechanism, specifically designed to mitigate the vulnerability of ML-based NIDS. Our solution consists of one layer of stacking classifiers and a second layer based on an autoencoder. If the incoming network data are classified as benign by the first layer, the second layer is activated to ensure that the decision made by the stacking classifier is correct. We also incorporated adversarial training to further improve the robustness of our solution. Experiments on two datasets, namely UNSW-NB15 and NSL-KDD, demonstrate that the proposed approach increases resilience to adversarial attacks.
BioME: A Resource-Efficient Bioacoustic Foundational Model for IoT Applications
Feb 10, 2026Passive acoustic monitoring has become a key strategy in biodiversity assessment, conservation, and behavioral ecology, especially as Internet-of-Things (IoT) devices enable continuous in situ audio collection at scale. While recent self-supervised learning (SSL)-based audio encoders, such as BEATs and AVES, have shown strong performance in bioacoustic tasks, their computational cost and limited robustness to unseen environments hinder deployment on resource-constrained platforms. In this work, we introduce BioME, a resource-efficient audio encoder designed for bioacoustic applications. BioME is trained via layer-to-layer distillation from a high-capacity teacher model, enabling strong representational transfer while reducing the parameter count by 75%. To further improve ecological generalization, the model is pretrained on multi-domain data spanning speech, environmental sounds, and animal vocalizations. A key contribution is the integration of modulation-aware acoustic features via FiLM conditioning, injecting a DSP-inspired inductive bias that enhances feature disentanglement in low-capacity regimes. Across multiple bioacoustic tasks, BioME matches or surpasses the performance of larger models, including its teacher, while being suitable for resource-constrained IoT deployments. For reproducibility, code and pretrained checkpoints are publicly available.
DiTSE: High-Fidelity Generative Speech Enhancement via Latent Diffusion Transformers
Apr 13, 2025Real-world speech recordings suffer from degradations such as background noise and reverberation. Speech enhancement aims to mitigate these issues by generating clean high-fidelity signals. While recent generative approaches for speech enhancement have shown promising results, they still face two major challenges: (1) content hallucination, where plausible phonemes generated differ from the original utterance; and (2) inconsistency, failing to preserve speaker's identity and paralinguistic features from the input speech. In this work, we introduce DiTSE (Diffusion Transformer for Speech Enhancement), which addresses quality issues of degraded speech in full bandwidth. Our approach employs a latent diffusion transformer model together with robust conditioning features, effectively addressing these challenges while remaining computationally efficient. Experimental results from both subjective and objective evaluations demonstrate that DiTSE achieves state-of-the-art audio quality that, for the first time, matches real studio-quality audio from the DAPS dataset. Furthermore, DiTSE significantly improves the preservation of speaker identity and content fidelity, reducing hallucinations across datasets compared to state-of-the-art enhancers. Audio samples are available at: http://hguimaraes.me/DiTSE
UrBAN: Urban Beehive Acoustics and PheNotyping Dataset
Jun 05, 2024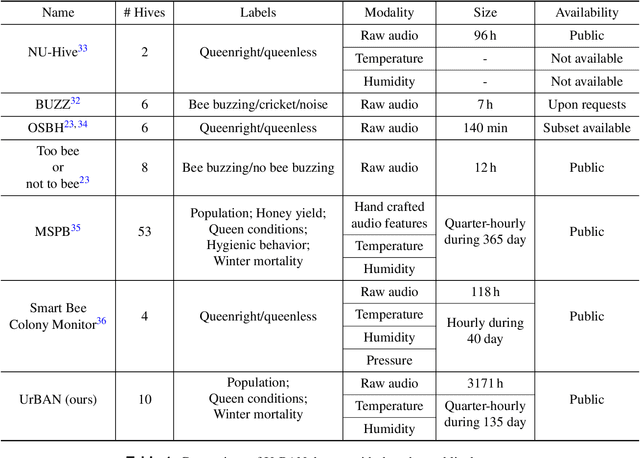

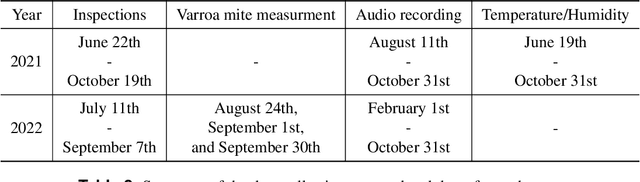
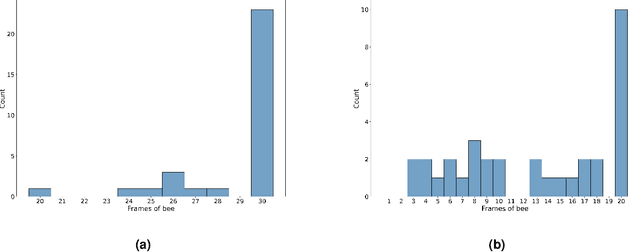
In this paper, we present a multimodal dataset obtained from a honey bee colony in Montr\'eal, Quebec, Canada, spanning the years of 2021 to 2022. This apiary comprised 10 beehives, with microphones recording more than 2000 hours of high quality raw audio, and also sensors capturing temperature, and humidity. Periodic hive inspections involved monitoring colony honey bee population changes, assessing queen-related conditions, and documenting overall hive health. Additionally, health metrics, such as Varroa mite infestation rates and winter mortality assessments were recorded, offering valuable insights into factors affecting hive health status and resilience. In this study, we first outline the data collection process, sensor data description, and dataset structure. Furthermore, we demonstrate a practical application of this dataset by extracting various features from the raw audio to predict colony population using the number of frames of bees as a proxy.
An Efficient End-to-End Approach to Noise Invariant Speech Features via Multi-Task Learning
Mar 13, 2024
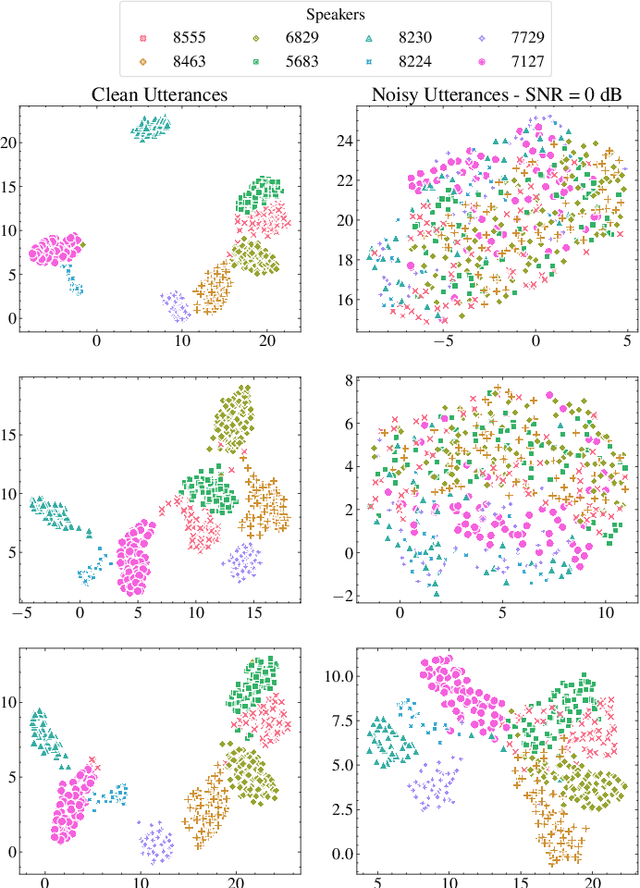


Self-supervised speech representation learning enables the extraction of meaningful features from raw waveforms. These features can then be efficiently used across multiple downstream tasks. However, two significant issues arise when considering the deployment of such methods ``in-the-wild": (i) Their large size, which can be prohibitive for edge applications; and (ii) their robustness to detrimental factors, such as noise and/or reverberation, that can heavily degrade the performance of such systems. In this work, we propose RobustDistiller, a novel knowledge distillation mechanism that tackles both problems jointly. Simultaneously to the distillation recipe, we apply a multi-task learning objective to encourage the network to learn noise-invariant representations by denoising the input. The proposed mechanism is evaluated on twelve different downstream tasks. It outperforms several benchmarks regardless of noise type, or noise and reverberation levels. Experimental results show that the new Student model with 23M parameters can achieve results comparable to the Teacher model with 95M parameters. Lastly, we show that the proposed recipe can be applied to other distillation methodologies, such as the recent DPWavLM. For reproducibility, code and model checkpoints will be made available at \mbox{\url{https://github.com/Hguimaraes/robustdistiller}}.
MSPB: a longitudinal multi-sensor dataset with phenotypic trait measurements from honey bees
Nov 17, 2023We present a longitudinal multi-sensor dataset collected from honey bee colonies (Apis mellifera) with rich phenotypic measurements. Data were continuously collected between May-2020 and April-2021 from 53 hives located at two apiaries in Qu\'ebec, Canada. The sensor data included audio features, temperature, and relative humidity. The phenotypic measurements contained beehive population, number of brood cells (eggs, larva and pupa), Varroa destructor infestation levels, defensive and hygienic behaviors, honey yield, and winter mortality. Our study is amongst the first to provide a wide variety of phenotypic trait measurements annotated by apicultural science experts, which facilitate a broader scope of analysis. We first summarize the data collection procedure, sensor data pre-processing steps, and data composition. We then provide an overview of the phenotypic data distribution as well as a visualization of the sensor data patterns. Lastly, we showcase several hive monitoring applications based on sensor data analysis and machine learning, such as winter mortality prediction, hive population estimation, and the presence of an active and laying queen.
On the Impact of Quantization and Pruning of Self-Supervised Speech Models for Downstream Speech Recognition Tasks "In-the-Wild''
Sep 25, 2023



Recent advances with self-supervised learning have allowed speech recognition systems to achieve state-of-the-art (SOTA) word error rates (WER) while requiring only a fraction of the labeled training data needed by its predecessors. Notwithstanding, while such models achieve SOTA performance in matched train/test conditions, their performance degrades substantially when tested in unseen conditions. To overcome this problem, strategies such as data augmentation and/or domain shift training have been explored. Available models, however, are still too large to be considered for edge speech applications on resource-constrained devices, thus model compression tools are needed. In this paper, we explore the effects that train/test mismatch conditions have on speech recognition accuracy based on compressed self-supervised speech models. In particular, we report on the effects that parameter quantization and model pruning have on speech recognition accuracy based on the so-called robust wav2vec 2.0 model under noisy, reverberant, and noise-plus-reverberation conditions.
VIC-KD: Variance-Invariance-Covariance Knowledge Distillation to Make Keyword Spotting More Robust Against Adversarial Attacks
Sep 22, 2023



Keyword spotting (KWS) refers to the task of identifying a set of predefined words in audio streams. With the advances seen recently with deep neural networks, it has become a popular technology to activate and control small devices, such as voice assistants. Relying on such models for edge devices, however, can be challenging due to hardware constraints. Moreover, as adversarial attacks have increased against voice-based technologies, developing solutions robust to such attacks has become crucial. In this work, we propose VIC-KD, a robust distillation recipe for model compression and adversarial robustness. Using self-supervised speech representations, we show that imposing geometric priors to the latent representations of both Teacher and Student models leads to more robust target models. Experiments on the Google Speech Commands datasets show that the proposed methodology improves upon current state-of-the-art robust distillation methods, such as ARD and RSLAD, by 12% and 8% in robust accuracy, respectively.
Characterizing the temporal dynamics of universal speech representations for generalizable deepfake detection
Sep 15, 2023



Existing deepfake speech detection systems lack generalizability to unseen attacks (i.e., samples generated by generative algorithms not seen during training). Recent studies have explored the use of universal speech representations to tackle this issue and have obtained inspiring results. These works, however, have focused on innovating downstream classifiers while leaving the representation itself untouched. In this study, we argue that characterizing the long-term temporal dynamics of these representations is crucial for generalizability and propose a new method to assess representation dynamics. Indeed, we show that different generative models generate similar representation dynamics patterns with our proposed method. Experiments on the ASVspoof 2019 and 2021 datasets validate the benefits of the proposed method to detect deepfakes from methods unseen during training, significantly improving on several benchmark methods.
An Exploration into the Performance of Unsupervised Cross-Task Speech Representations for "In the Wild'' Edge Applications
May 09, 2023
Unsupervised speech models are becoming ubiquitous in the speech and machine learning communities. Upstream models are responsible for learning meaningful representations from raw audio. Later, these representations serve as input to downstream models to solve a number of tasks, such as keyword spotting or emotion recognition. As edge speech applications start to emerge, it is important to gauge how robust these cross-task representations are on edge devices with limited resources and different noise levels. To this end, in this study we evaluate the robustness of four different versions of HuBERT, namely: base, large, and extra-large versions, as well as a recent version termed Robust-HuBERT. Tests are conducted under different additive and convolutive noise conditions for three downstream tasks: keyword spotting, intent classification, and emotion recognition. Our results show that while larger models can provide some important robustness to environmental factors, they may not be applicable to edge applications. Smaller models, on the other hand, showed substantial accuracy drops in noisy conditions, especially in the presence of room reverberation. These findings suggest that cross-task speech representations are not yet ready for edge applications and innovations are still needed.