 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Efficient End-to-End Approach to Noise Invariant Speech Features via Multi-Task Learning
Mar 13, 2024Self-supervised speech representation learning enables the extraction of meaningful features from raw waveforms. These features can then be efficiently used across multiple downstream tasks. However, two significant issues arise when considering the deployment of such methods ``in-the-wild": (i) Their large size, which can be prohibitive for edge applications; and (ii) their robustness to detrimental factors, such as noise and/or reverberation, that can heavily degrade the performance of such systems. In this work, we propose RobustDistiller, a novel knowledge distillation mechanism that tackles both problems jointly. Simultaneously to the distillation recipe, we apply a multi-task learning objective to encourage the network to learn noise-invariant representations by denoising the input. The proposed mechanism is evaluated on twelve different downstream tasks. It outperforms several benchmarks regardless of noise type, or noise and reverberation levels. Experimental results show that the new Student model with 23M parameters can achieve results comparable to the Teacher model with 95M parameters. Lastly, we show that the proposed recipe can be applied to other distillation methodologies, such as the recent DPWavLM. For reproducibility, code and model checkpoints will be made available at \mbox{\url{https://github.com/Hguimaraes/robustdistiller}}.
On the Impact of Quantization and Pruning of Self-Supervised Speech Models for Downstream Speech Recognition Tasks "In-the-Wild''
Sep 25, 2023Recent advances with self-supervised learning have allowed speech recognition systems to achieve state-of-the-art (SOTA) word error rates (WER) while requiring only a fraction of the labeled training data needed by its predecessors. Notwithstanding, while such models achieve SOTA performance in matched train/test conditions, their performance degrades substantially when tested in unseen conditions. To overcome this problem, strategies such as data augmentation and/or domain shift training have been explored. Available models, however, are still too large to be considered for edge speech applications on resource-constrained devices, thus model compression tools are needed. In this paper, we explore the effects that train/test mismatch conditions have on speech recognition accuracy based on compressed self-supervised speech models. In particular, we report on the effects that parameter quantization and model pruning have on speech recognition accuracy based on the so-called robust wav2vec 2.0 model under noisy, reverberant, and noise-plus-reverberation conditions.
Multimodal Audio-textual Architecture for Robust Spoken Language Understanding
Jun 13, 2023Recent voice assistants are usually based on the cascade spoken language understanding (SLU) solution, which consists of an automatic speech recognition (ASR) engine and a natural language understanding (NLU) system. Because such approach relies on the ASR output, it often suffers from the so-called ASR error propagation. In this work, we investigate impacts of this ASR error propagation on state-of-the-art NLU systems based on pre-trained language models (PLM), such as BERT and RoBERTa. Moreover, a multimodal language understanding (MLU) module is proposed to mitigate SLU performance degradation caused by errors present in the ASR transcript. The MLU benefits from self-supervised features learned from both audio and text modalities, specifically Wav2Vec for speech and Bert/RoBERTa for language. Our MLU combines an encoder network to embed the audio signal and a text encoder to process text transcripts followed by a late fusion layer to fuse audio and text logits. We found that the proposed MLU showed to be robust towards poor quality ASR transcripts, while the performance of BERT and RoBERTa are severely compromised. Our model is evaluated on five tasks from three SLU datasets and robustness is tested using ASR transcripts from three ASR engines. Results show that the proposed approach effectively mitigates the ASR error propagation problem, surpassing the PLM models' performance across all datasets for the academic ASR engine.
RobustDistiller: Compressing Universal Speech Representations for Enhanced Environment Robustness
Feb 23, 2023Self-supervised speech pre-training enables deep neural network models to capture meaningful and disentangled factors from raw waveform signals. The learned universal speech representations can then be used across numerous downstream tasks. These representations, however, are sensitive to distribution shifts caused by environmental factors, such as noise and/or room reverberation. Their large sizes, in turn, make them unfeasible for edge applications. In this work, we propose a knowledge distillation methodology termed RobustDistiller which compresses universal representations while making them more robust against environmental artifacts via a multi-task learning objective. The proposed layer-wise distillation recipe is evaluated on top of three well-established universal representations, as well as with three downstream tasks. Experimental results show the proposed methodology applied on top of the WavLM Base+ teacher model outperforming all other benchmarks across noise types and levels, as well as reverberation times. Oftentimes, the obtained results with the student model (24M parameters) achieved results inline with those of the teacher model (95M).
Improving the Robustness of DistilHuBERT to Unseen Noisy Conditions via Data Augmentation, Curriculum Learning, and Multi-Task Enhancement
Nov 12, 2022Self-supervised speech representation learning aims to extract meaningful factors from the speech signal that can later be used across different downstream tasks, such as speech and/or emotion recognition. Existing models, such as HuBERT, however, can be fairly large thus may not be suitable for edge speech applications. Moreover, realistic applications typically involve speech corrupted by noise and room reverberation, hence models need to provide representations that are robust to such environmental factors. In this study, we build on the so-called DistilHuBERT model, which distils HuBERT to a fraction of its original size, with three modifications, namely: (i) augment the training data with noise and reverberation, while the student model needs to distill the clean representations from the teacher model; (ii) introduce a curriculum learning approach where increasing levels of noise are introduced as the model trains, thus helping with convergence and with the creation of more robust representations; and (iii) introduce a multi-task learning approach where the model also reconstructs the clean waveform jointly with the distillation task, thus also acting as an enhancement step to ensure additional environment robustness to the representation. Experiments on three SUPERB tasks show the advantages of the proposed method not only relative to the original DistilHuBERT, but also to the original HuBERT, thus showing the advantages of the proposed method for ``in the wild'' edge speech applications.
Low-bit Shift Network for End-to-End Spoken Language Understanding
Jul 15, 2022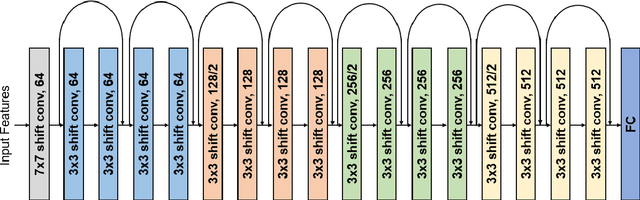
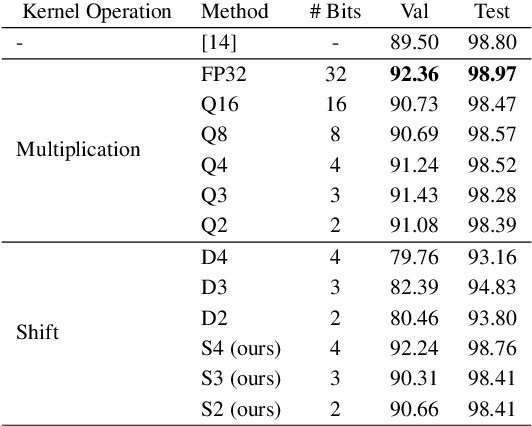
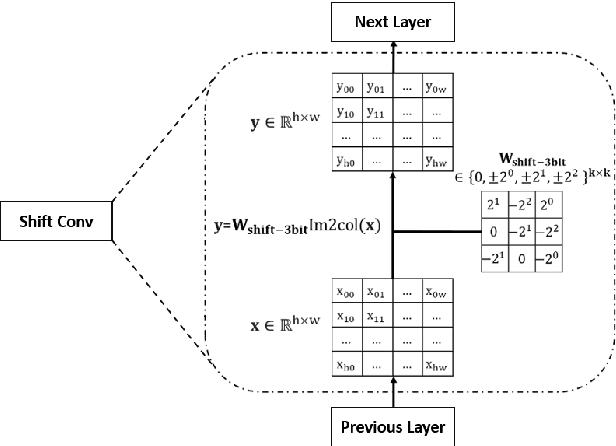
Deep neural networks (DNN) have achieved impressive success in multiple domains. Over the years, the accuracy of these models has increased with the proliferation of deeper and more complex architectures. Thus, state-of-the-art solutions are often computationally expensive, which makes them unfit to be deployed on edge computing platforms. In order to mitigate the high computation, memory, and power requirements of inferring convolutional neural networks (CNNs), we propose the use of power-of-two quantization, which quantizes continuous parameters into low-bit power-of-two values. This reduces computational complexity by removing expensive multiplication operations and with the use of low-bit weights. ResNet is adopted as the building block of our solution and the proposed model is evaluated on a spoken language understanding (SLU) task. Experimental results show improved performance for shift neural network architectures, with our low-bit quantization achieving 98.76 \% on the test set which is comparable performance to its full-precision counterpart and state-of-the-art solutions.
A Streaming End-to-End Framework For Spoken Language Understanding
Jun 08, 2021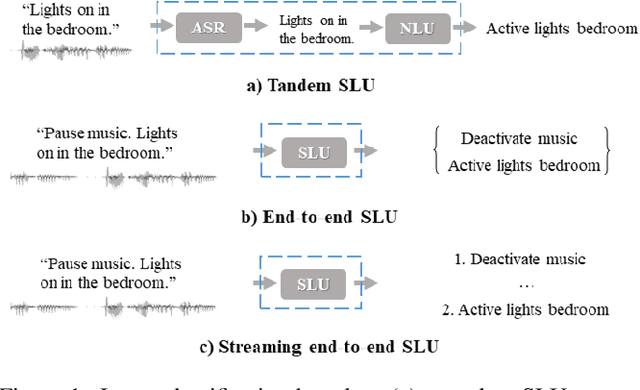
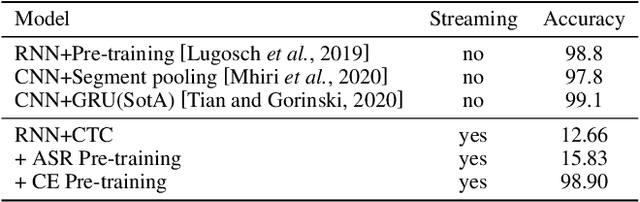
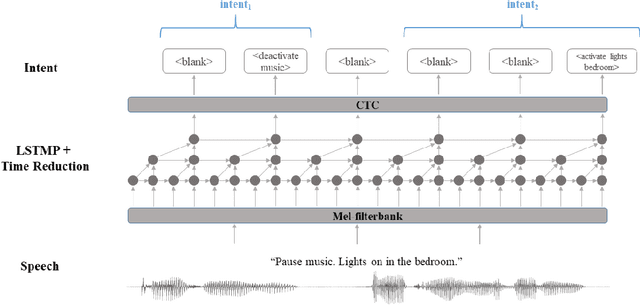

End-to-end spoken language understanding (SLU) has recently attracted increasing interest. Compared to the conventional tandem-based approach that combines speech recognition and language understanding as separate modules, the new approach extracts users' intentions directly from the speech signals, resulting in joint optimization and low latency. Such an approach, however, is typically designed to process one intention at a time, which leads users to take multiple rounds to fulfill their requirements while interacting with a dialogue system. In this paper, we propose a streaming end-to-end framework that can process multiple intentions in an online and incremental way. The backbone of our framework is a unidirectional RNN trained with the connectionist temporal classification (CTC) criterion. By this design, an intention can be identified when sufficient evidence has been accumulated, and multiple intentions can be identified sequentially. We evaluate our solution on the Fluent Speech Commands (FSC) dataset and the intent detection accuracy is about 97 % on all multi-intent settings. This result is comparable to the performance of the state-of-the-art non-streaming models, but is achieved in an online and incremental way. We also employ our model to a keyword spotting task using the Google Speech Commands dataset and the results are also highly promising.
Sequential End-to-End Intent and Slot Label Classification and Localization
Jun 08, 2021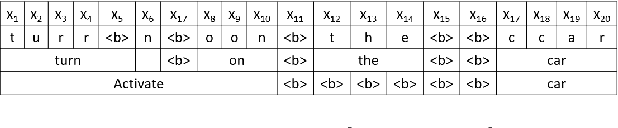

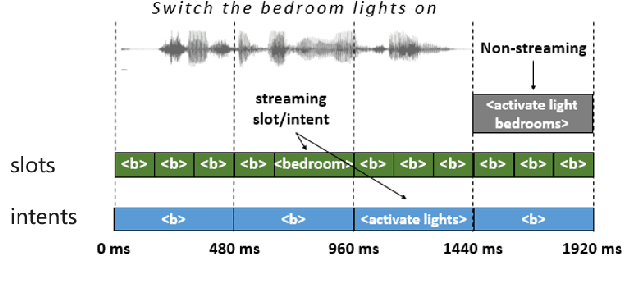
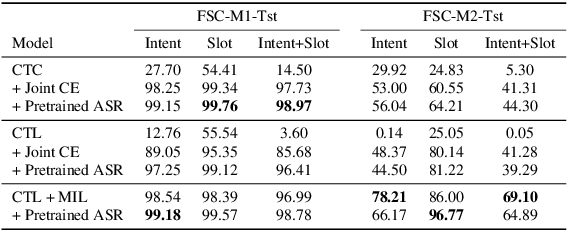
Human-computer interaction (HCI) is significantly impacted by delayed responses from a spoken dialogue system. Hence, end-to-end (e2e) spoken language understanding (SLU) solutions have recently been proposed to decrease latency. Such approaches allow for the extraction of semantic information directly from the speech signal, thus bypassing the need for a transcript from an automatic speech recognition (ASR) system. In this paper, we propose a compact e2e SLU architecture for streaming scenarios, where chunks of the speech signal are processed continuously to predict intent and slot values. Our model is based on a 3D convolutional neural network (3D-CNN) and a unidirectional long short-term memory (LSTM). We compare the performance of two alignment-free losses: the connectionist temporal classification (CTC) method and its adapted version, namely connectionist temporal localization (CTL). The latter performs not only the classification but also localization of sequential audio events. The proposed solution is evaluated on the Fluent Speech Command dataset and results show our model ability to process incoming speech signal, reaching accuracy as high as 98.97 % for CTC and 98.78 % for CTL on single-label classification, and as high as 95.69 % for CTC and 95.28 % for CTL on two-label prediction.