 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSequential End-to-End Intent and Slot Label Classification and Localization
Paper and Code
Jun 08, 2021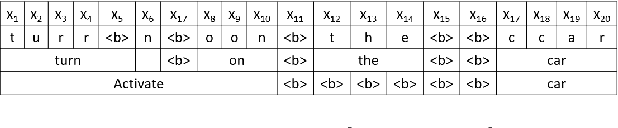

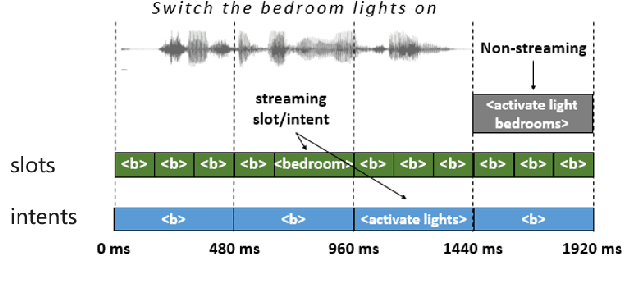
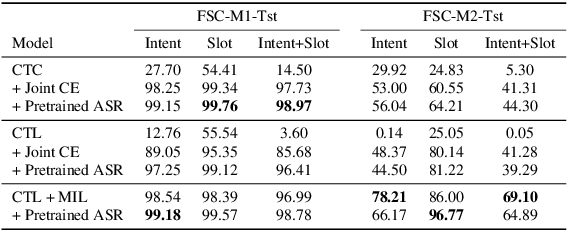
Human-computer interaction (HCI) is significantly impacted by delayed responses from a spoken dialogue system. Hence, end-to-end (e2e) spoken language understanding (SLU) solutions have recently been proposed to decrease latency. Such approaches allow for the extraction of semantic information directly from the speech signal, thus bypassing the need for a transcript from an automatic speech recognition (ASR) system. In this paper, we propose a compact e2e SLU architecture for streaming scenarios, where chunks of the speech signal are processed continuously to predict intent and slot values. Our model is based on a 3D convolutional neural network (3D-CNN) and a unidirectional long short-term memory (LSTM). We compare the performance of two alignment-free losses: the connectionist temporal classification (CTC) method and its adapted version, namely connectionist temporal localization (CTL). The latter performs not only the classification but also localization of sequential audio events. The proposed solution is evaluated on the Fluent Speech Command dataset and results show our model ability to process incoming speech signal, reaching accuracy as high as 98.97 % for CTC and 98.78 % for CTL on single-label classification, and as high as 95.69 % for CTC and 95.28 % for CTL on two-label prediction.