 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Impact of Ideological Discourses in RAG: A Case Study with COVID-19 Treatments
Mar 16, 2026This paper studies the impact of retrieved ideological texts on the outputs of large language models (LLMs). While interest in understanding ideology in LLMs has recently increased, little attention has been given to this issue in the context of Retrieval-Augmented Generation (RAG). To fill this gap, we design an external knowledge source based on ideological loaded texts about COVID-19 treatments. Our corpus is based on 1,117 academic articles representing discourses about controversial and endorsed treatments for the disease. We propose a corpus linguistics framework, based on Lexical Multidimensional Analysis (LMDA), to identify the ideologies within the corpus. LLMs are tasked to answer questions derived from three identified ideological dimensions, and two types of contextual prompts are adopted: the first comprises the user question and ideological texts; and the second contains the question, ideological texts, and LMDA descriptions. Ideological alignment between reference ideological texts and LLMs' responses is assessed using cosine similarity for lexical and semantic representations. Results demonstrate that LLMs' responses based on ideological retrieved texts are more aligned with the ideology encountered in the external knowledge, with the enhanced prompt further influencing LLMs' outputs. Our findings highlight the importance of identifying ideological discourses within the RAG framework in order to mitigate not just unintended ideological bias, but also the risks of malicious manipulation of such models.
TempCharBERT: Keystroke Dynamics for Continuous Access Control Based on Pre-trained Language Models
Nov 11, 2024

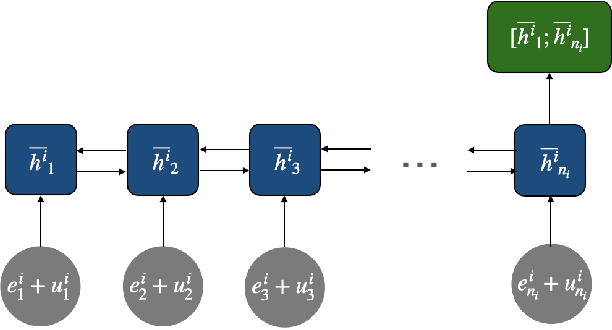

With the widespread of digital environments, reliable authentication and continuous access control has become crucial. It can minimize cyber attacks and prevent frauds, specially those associated with identity theft. A particular interest lies on keystroke dynamics (KD), which refers to the task of recognizing individuals' identity based on their unique typing style. In this work, we propose the use of pre-trained language models (PLMs) to recognize such patterns. Although PLMs have shown high performance on multiple NLP benchmarks, the use of these models on specific tasks requires customization. BERT and RoBERTa, for instance, rely on subword tokenization, and they cannot be directly applied to KD, which requires temporal-character information to recognize users. Recent character-aware PLMs are able to process both subwords and character-level information and can be an alternative solution. Notwithstanding, they are still not suitable to be directly fine-tuned for KD as they are not optimized to account for user's temporal typing information (e.g., hold time and flight time). To overcome this limitation, we propose TempCharBERT, an architecture that incorporates temporal-character information in the embedding layer of CharBERT. This allows modeling keystroke dynamics for the purpose of user identification and authentication. Our results show a significant improvement with this customization. We also showed the feasibility of training TempCharBERT on a federated learning settings in order to foster data privacy.
Automatic Structured Pruning for Efficient Architecture in Federated Learning
Nov 04, 2024In Federated Learning (FL), training is conducted on client devices, typically with limited computational resources and storage capacity. To address these constraints, we propose an automatic pruning scheme tailored for FL systems. Our solution improves computation efficiency on client devices, while minimizing communication costs. One of the challenges of tuning pruning hyper-parameters in FL systems is the restricted access to local data. Thus, we introduce an automatic pruning paradigm that dynamically determines pruning boundaries. Additionally, we utilized a structured pruning algorithm optimized for mobile devices that lack hardware support for sparse computations. Experimental results demonstrate the effectiveness of our approach, achieving accuracy comparable to existing methods. Our method notably reduces the number of parameters by 89% and FLOPS by 90%, with minimal impact on the accuracy of the FEMNIST and CelebFaces datasets. Furthermore, our pruning method decreases communication overhead by up to 5x and halves inference time when deployed on Android devices.
VIC-KD: Variance-Invariance-Covariance Knowledge Distillation to Make Keyword Spotting More Robust Against Adversarial Attacks
Sep 22, 2023



Keyword spotting (KWS) refers to the task of identifying a set of predefined words in audio streams. With the advances seen recently with deep neural networks, it has become a popular technology to activate and control small devices, such as voice assistants. Relying on such models for edge devices, however, can be challenging due to hardware constraints. Moreover, as adversarial attacks have increased against voice-based technologies, developing solutions robust to such attacks has become crucial. In this work, we propose VIC-KD, a robust distillation recipe for model compression and adversarial robustness. Using self-supervised speech representations, we show that imposing geometric priors to the latent representations of both Teacher and Student models leads to more robust target models. Experiments on the Google Speech Commands datasets show that the proposed methodology improves upon current state-of-the-art robust distillation methods, such as ARD and RSLAD, by 12% and 8% in robust accuracy, respectively.
On the Transferability of Whisper-based Representations for "In-the-Wild" Cross-Task Downstream Speech Applications
May 23, 2023Large self-supervised pre-trained speech models have achieved remarkable success across various speech-processing tasks. The self-supervised training of these models leads to universal speech representations that can be used for different downstream tasks, ranging from automatic speech recognition (ASR) to speaker identification. Recently, Whisper, a transformer-based model was proposed and trained on large amount of weakly supervised data for ASR; it outperformed several state-of-the-art self-supervised models. Given the superiority of Whisper for ASR, in this paper we explore the transferability of the representation for four other speech tasks in SUPERB benchmark. Moreover, we explore the robustness of Whisper representation for ``in the wild'' tasks where speech is corrupted by environment noise and room reverberation. Experimental results show Whisper achieves promising results across tasks and environmental conditions, thus showing potential for cross-task real-world deployment.
An Exploration into the Performance of Unsupervised Cross-Task Speech Representations for "In the Wild'' Edge Applications
May 09, 2023
Unsupervised speech models are becoming ubiquitous in the speech and machine learning communities. Upstream models are responsible for learning meaningful representations from raw audio. Later, these representations serve as input to downstream models to solve a number of tasks, such as keyword spotting or emotion recognition. As edge speech applications start to emerge, it is important to gauge how robust these cross-task representations are on edge devices with limited resources and different noise levels. To this end, in this study we evaluate the robustness of four different versions of HuBERT, namely: base, large, and extra-large versions, as well as a recent version termed Robust-HuBERT. Tests are conducted under different additive and convolutive noise conditions for three downstream tasks: keyword spotting, intent classification, and emotion recognition. Our results show that while larger models can provide some important robustness to environmental factors, they may not be applicable to edge applications. Smaller models, on the other hand, showed substantial accuracy drops in noisy conditions, especially in the presence of room reverberation. These findings suggest that cross-task speech representations are not yet ready for edge applications and innovations are still needed.