 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWavRx: a Disease-Agnostic, Generalizable, and Privacy-Preserving Speech Health Diagnostic Model
Jun 26, 2024Speech is known to carry health-related attributes, which has emerged as a novel venue for remote and long-term health monitoring. However, existing models are usually tailored for a specific type of disease, and have been shown to lack generalizability across datasets. Furthermore, concerns have been raised recently towards the leakage of speaker identity from health embeddings. To mitigate these limitations, we propose WavRx, a speech health diagnostics model that captures the respiration and articulation related dynamics from a universal speech representation. Our in-domain and cross-domain experiments on six pathological speech datasets demonstrate WavRx as a new state-of-the-art health diagnostic model. Furthermore, we show that the amount of speaker identity entailed in the WavRx health embeddings is significantly reduced without extra guidance during training. An in-depth analysis of the model was performed, thus providing physiological interpretation of its improved generalizability and privacy-preserving ability.
On the Transferability of Whisper-based Representations for "In-the-Wild" Cross-Task Downstream Speech Applications
May 23, 2023Large self-supervised pre-trained speech models have achieved remarkable success across various speech-processing tasks. The self-supervised training of these models leads to universal speech representations that can be used for different downstream tasks, ranging from automatic speech recognition (ASR) to speaker identification. Recently, Whisper, a transformer-based model was proposed and trained on large amount of weakly supervised data for ASR; it outperformed several state-of-the-art self-supervised models. Given the superiority of Whisper for ASR, in this paper we explore the transferability of the representation for four other speech tasks in SUPERB benchmark. Moreover, we explore the robustness of Whisper representation for ``in the wild'' tasks where speech is corrupted by environment noise and room reverberation. Experimental results show Whisper achieves promising results across tasks and environmental conditions, thus showing potential for cross-task real-world deployment.
An end-to-end approach for the verification problem: learning the right distance
Feb 21, 2020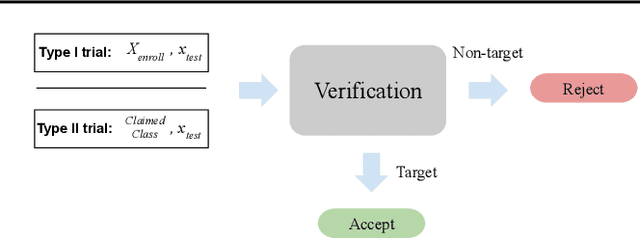
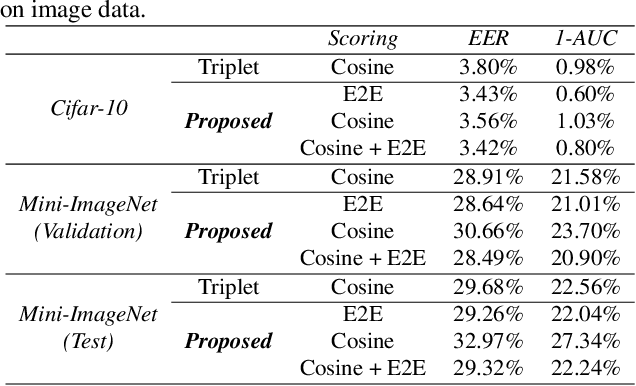
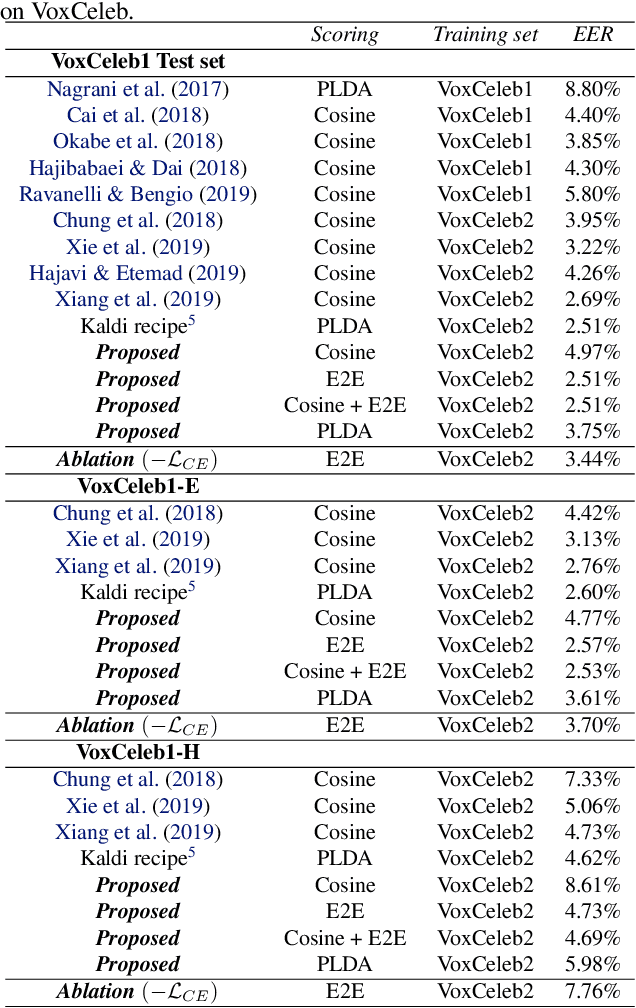
In this contribution, we augment the metric learning setting by introducing a parametric pseudo-distance, trained jointly with the encoder. Several interpretations are thus drawn for the learned distance-like model's output. We first show it approximates a likelihood ratio which can be used for hypothesis tests, and that it further induces a large divergence across the joint distributions of pairs of examples from the same and from different classes. Evaluation is performed under the verification setting consisting of determining whether sets of examples belong to the same class, even if such classes are novel and were never presented to the model during training. Empirical evaluation shows such method defines an end-to-end approach for the verification problem, able to attain better performance than simple scorers such as those based on cosine similarity and further outperforming widely used downstream classifiers. We further observe training is much simplified under the proposed approach compared to metric learning with actual distances, requiring no complex scheme to harvest pairs of examples.
Multi-objective training of Generative Adversarial Networks with multiple discriminators
Jan 24, 2019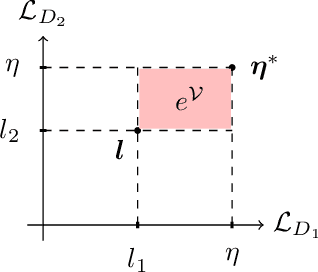

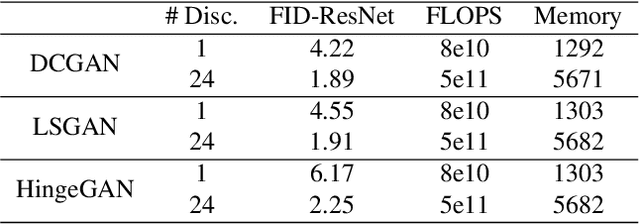
Recent literature has demonstrated promising results for training Generative Adversarial Networks by employing a set of discriminators, in contrast to the traditional game involving one generator against a single adversary. Such methods perform single-objective optimization on some simple consolidation of the losses, e.g. an arithmetic average. In this work, we revisit the multiple-discriminator setting by framing the simultaneous minimization of losses provided by different models as a multi-objective optimization problem. Specifically, we evaluate the performance of multiple gradient descent and the hypervolume maximization algorithm on a number of different datasets. Moreover, we argue that the previously proposed methods and hypervolume maximization can all be seen as variations of multiple gradient descent in which the update direction can be computed efficiently. Our results indicate that hypervolume maximization presents a better compromise between sample quality and computational cost than previous methods.