 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding Syntactic Generalization in Structure-inducing Language Models
Aug 11, 2025Structure-inducing Language Models (SiLM) are trained on a self-supervised language modeling task, and induce a hierarchical sentence representation as a byproduct when processing an input. A wide variety of SiLMs have been proposed. However, these have typically been evaluated on a relatively small scale, and evaluation of these models has systematic gaps and lacks comparability. In this work, we study three different SiLM architectures using both natural language (English) corpora and synthetic bracketing expressions: Structformer (Shen et al., 2021), UDGN (Shen et al., 2022) and GPST (Hu et al., 2024). We compare them with respect to (i) properties of the induced syntactic representations (ii) performance on grammaticality judgment tasks, and (iii) training dynamics. We find that none of the three architectures dominates across all evaluation metrics. However, there are significant differences, in particular with respect to the induced syntactic representations. The Generative Pretrained Structured Transformer (GPST; Hu et al. 2024) performs most consistently across evaluation settings, and outperforms the other models on long-distance dependencies in bracketing expressions. Furthermore, our study shows that small models trained on large amounts of synthetic data provide a useful testbed for evaluating basic model properties.
Seeing Syntax: Uncovering Syntactic Learning Limitations in Vision-Language Models
Dec 11, 2024


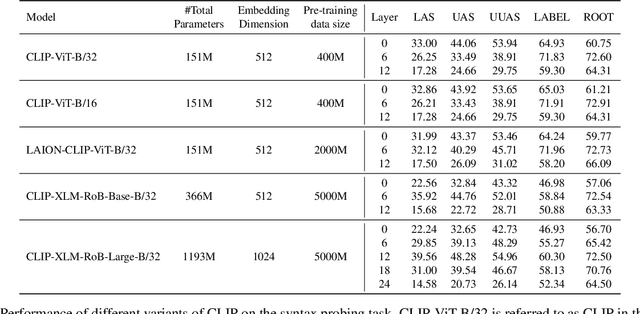
Vision-language models (VLMs), serve as foundation models for multi-modal applications such as image captioning and text-to-image generation. Recent studies have highlighted limitations in VLM text encoders, particularly in areas like compositionality and semantic understanding, though the underlying reasons for these limitations remain unclear. In this work, we aim to address this gap by analyzing the syntactic information, one of the fundamental linguistic properties, encoded by the text encoders of VLMs. We perform a thorough analysis comparing VLMs with different objective functions, parameter size and training data size, and with uni-modal language models (ULMs) in their ability to encode syntactic knowledge. Our findings suggest that ULM text encoders acquire syntactic information more effectively than those in VLMs. The syntactic information learned by VLM text encoders is shaped primarily by the pre-training objective, which plays a more crucial role than other factors such as model architecture, model size, or the volume of pre-training data. Models exhibit different layer-wise trends where CLIP performance dropped across layers while for other models, middle layers are rich in encoding syntactic knowledge.
Dissecting Paraphrases: The Impact of Prompt Syntax and supplementary Information on Knowledge Retrieval from Pretrained Language Models
Apr 02, 2024



Pre-trained Language Models (PLMs) are known to contain various kinds of knowledge. One method to infer relational knowledge is through the use of cloze-style prompts, where a model is tasked to predict missing subjects or objects. Typically, designing these prompts is a tedious task because small differences in syntax or semantics can have a substantial impact on knowledge retrieval performance. Simultaneously, evaluating the impact of either prompt syntax or information is challenging due to their interdependence. We designed CONPARE-LAMA - a dedicated probe, consisting of 34 million distinct prompts that facilitate comparison across minimal paraphrases. These paraphrases follow a unified meta-template enabling the controlled variation of syntax and semantics across arbitrary relations. CONPARE-LAMA enables insights into the independent impact of either syntactical form or semantic information of paraphrases on the knowledge retrieval performance of PLMs. Extensive knowledge retrieval experiments using our probe reveal that prompts following clausal syntax have several desirable properties in comparison to appositive syntax: i) they are more useful when querying PLMs with a combination of supplementary information, ii) knowledge is more consistently recalled across different combinations of supplementary information, and iii) they decrease response uncertainty when retrieving known facts. In addition, range information can boost knowledge retrieval performance more than domain information, even though domain information is more reliably helpful across syntactic forms.
Multilingual Nonce Dependency Treebanks: Understanding how LLMs represent and process syntactic structure
Nov 13, 2023
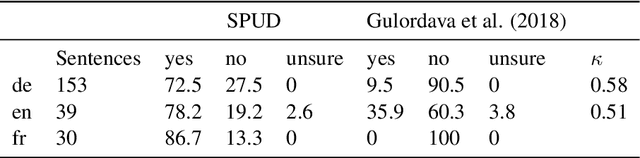


We introduce SPUD (Semantically Perturbed Universal Dependencies), a framework for creating nonce treebanks for the multilingual Universal Dependencies (UD) corpora. SPUD data satisfies syntactic argument structure, provides syntactic annotations, and ensures grammaticality via language-specific rules. We create nonce data in Arabic, English, French, German, and Russian, and demonstrate two use cases of SPUD treebanks. First, we investigate the effect of nonce data on word co-occurrence statistics, as measured by perplexity scores of autoregressive (ALM) and masked language models (MLM). We find that ALM scores are significantly more affected by nonce data than MLM scores. Second, we show how nonce data affects the performance of syntactic dependency probes. We replicate the findings of M\"uller-Eberstein et al. (2022) on nonce test data and show that the performance declines on both MLMs and ALMs wrt. original test data. However, a majority of the performance is kept, suggesting that the probe indeed learns syntax independently from semantics.
Increasing The Performance of Cognitively Inspired Data-Efficient Language Models via Implicit Structure Building
Oct 31, 2023
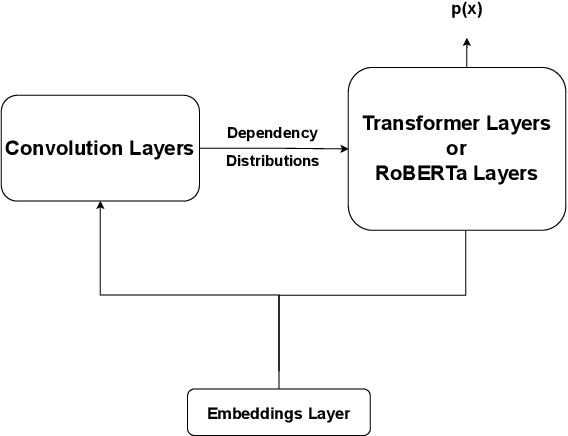
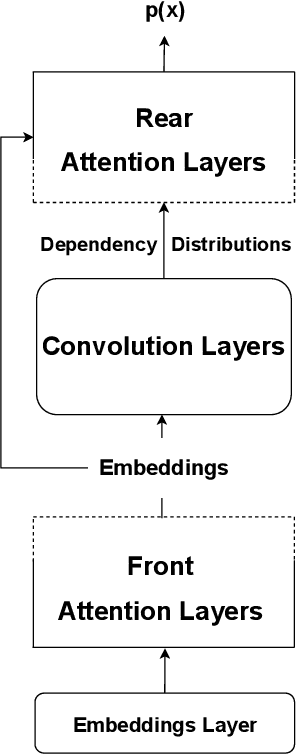

In this paper, we describe our submission to the BabyLM Challenge 2023 shared task on data-efficient language model (LM) pretraining (Warstadt et al., 2023). We train transformer-based masked language models that incorporate unsupervised predictions about hierarchical sentence structure into the model architecture. Concretely, we use the Structformer architecture (Shen et al., 2021) and variants thereof. StructFormer models have been shown to perform well on unsupervised syntactic induction based on limited pretraining data, and to yield performance improvements over a vanilla transformer architecture (Shen et al., 2021). Evaluation of our models on 39 tasks provided by the BabyLM challenge shows promising improvements of models that integrate a hierarchical bias into the architecture at some particular tasks, even though they fail to consistently outperform the RoBERTa baseline model provided by the shared task organizers on all tasks.
DEPLAIN: A German Parallel Corpus with Intralingual Translations into Plain Language for Sentence and Document Simplification
May 30, 2023Text simplification is an intralingual translation task in which documents, or sentences of a complex source text are simplified for a target audience. The success of automatic text simplification systems is highly dependent on the quality of parallel data used for training and evaluation. To advance sentence simplification and document simplification in German, this paper presents DEplain, a new dataset of parallel, professionally written and manually aligned simplifications in plain German ("plain DE" or in German: "Einfache Sprache"). DEplain consists of a news domain (approx. 500 document pairs, approx. 13k sentence pairs) and a web-domain corpus (approx. 150 aligned documents, approx. 2k aligned sentence pairs). In addition, we are building a web harvester and experimenting with automatic alignment methods to facilitate the integration of non-aligned and to be published parallel documents. Using this approach, we are dynamically increasing the web domain corpus, so it is currently extended to approx. 750 document pairs and approx. 3.5k aligned sentence pairs. We show that using DEplain to train a transformer-based seq2seq text simplification model can achieve promising results. We make available the corpus, the adapted alignment methods for German, the web harvester and the trained models here: https://github.com/rstodden/DEPlain.
Probing for Constituency Structure in Neural Language Models
Apr 13, 2022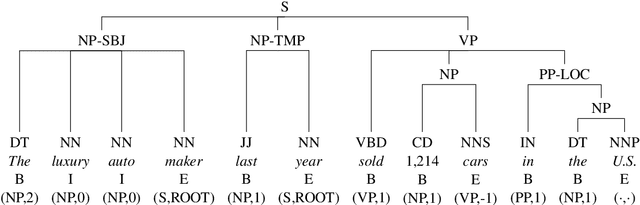

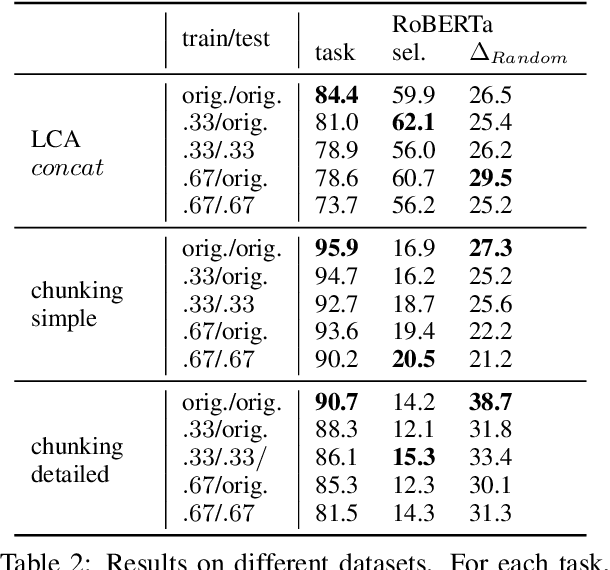
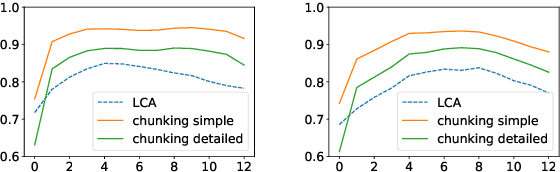
In this paper, we investigate to which extent contextual neural language models (LMs) implicitly learn syntactic structure. More concretely, we focus on constituent structure as represented in the Penn Treebank (PTB). Using standard probing techniques based on diagnostic classifiers, we assess the accuracy of representing constituents of different categories within the neuron activations of a LM such as RoBERTa. In order to make sure that our probe focuses on syntactic knowledge and not on implicit semantic generalizations, we also experiment on a PTB version that is obtained by randomly replacing constituents with each other while keeping syntactic structure, i.e., a semantically ill-formed but syntactically well-formed version of the PTB. We find that 4 pretrained transfomer LMs obtain high performance on our probing tasks even on manipulated data, suggesting that semantic and syntactic knowledge in their representations can be separated and that constituency information is in fact learned by the LM. Moreover, we show that a complete constituency tree can be linearly separated from LM representations.
Object-oriented lexical encoding of multiword expressions: Short and sweet
Oct 23, 2018
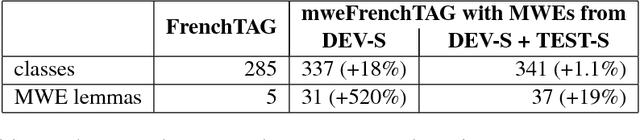


Multiword expressions (MWEs) exhibit both regular and idiosyncratic properties. Their idiosyncrasy requires lexical encoding in parallel with their component words. Their (at times intricate) regularity, on the other hand, calls for means of flexible factorization to avoid redundant descriptions of shared properties. However, so far, non-redundant general-purpose lexical encoding of MWEs has not received a satisfactory solution. We offer a proof of concept that this challenge might be effectively addressed within eXtensible MetaGrammar (XMG), an object-oriented metagrammar framework. We first make an existing metagrammatical resource, the FrenchTAG grammar, MWE-aware. We then evaluate the factorization gain during incremental implementation with XMG on a dataset extracted from an MWE-annotated reference corpus.
Sketching Word Vectors Through Hashing
Aug 30, 2018
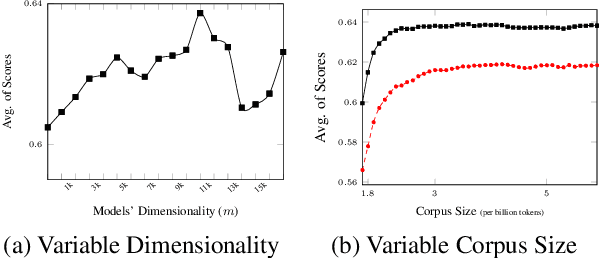


We propose a new fast word embedding technique using hash functions. The method is a derandomization of a new type of random projections: By disregarding the classic constraint used in designing random projections (i.e., preserving pairwise distances in a particular normed space), our solution exploits extremely sparse non-negative random projections. Our experiments show that the proposed method can achieve competitive results, comparable to neural embedding learning techniques, however, with only a fraction of the computational complexity of these methods. While the proposed derandomization enhances the computational and space complexity of our method, the possibility of applying weighting methods such as positive pointwise mutual information (PPMI) to our models after their construction (and at a reduced dimensionality) imparts a high discriminatory power to the resulting embeddings. Obviously, this method comes with other known benefits of random projection-based techniques such as ease of update.
TuLiPA: Towards a Multi-Formalism Parsing Environment for Grammar Engineering
Jul 23, 2008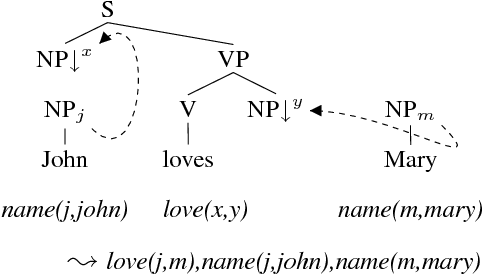
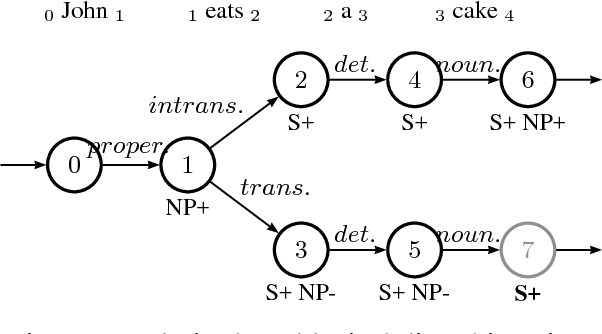
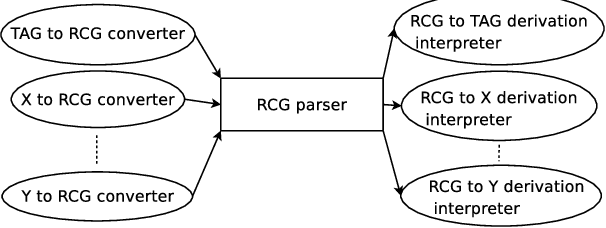

In this paper, we present an open-source parsing environment (Tuebingen Linguistic Parsing Architecture, TuLiPA) which uses Range Concatenation Grammar (RCG) as a pivot formalism, thus opening the way to the parsing of several mildly context-sensitive formalisms. This environment currently supports tree-based grammars (namely Tree-Adjoining Grammars, TAG) and Multi-Component Tree-Adjoining Grammars with Tree Tuples (TT-MCTAG)) and allows computation not only of syntactic structures, but also of the corresponding semantic representations. It is used for the development of a tree-based grammar for German.