 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCLARITY -- Comparing heterogeneous data using dissimiLARITY
May 29, 2020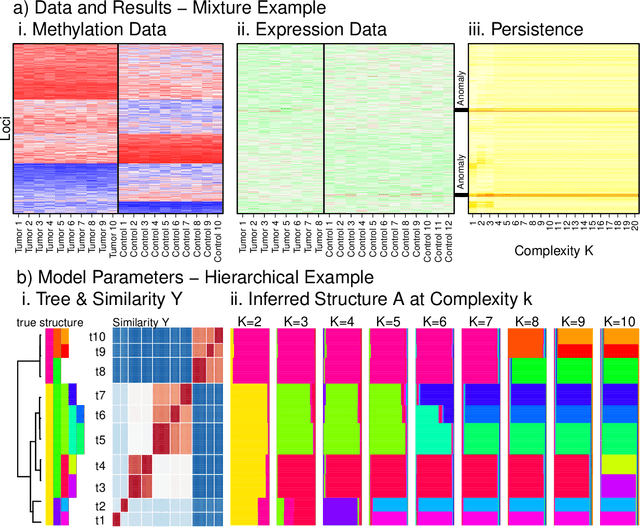
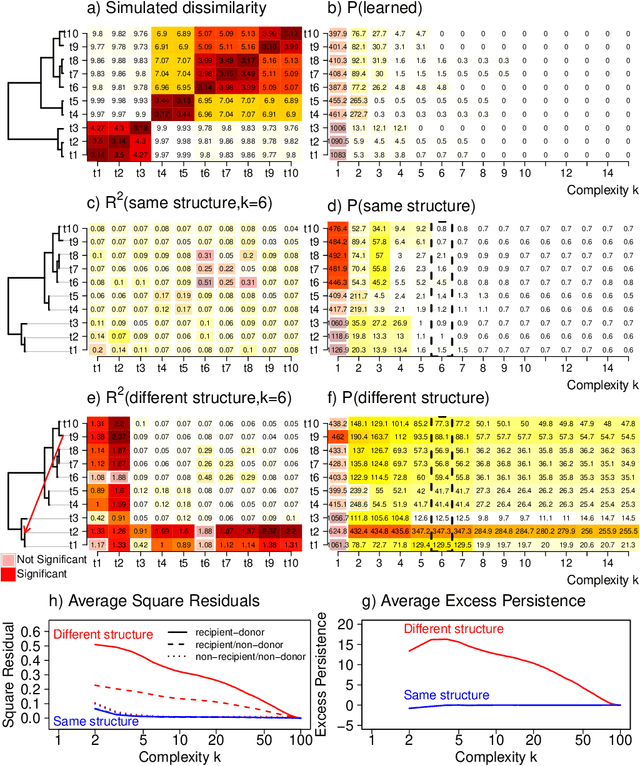
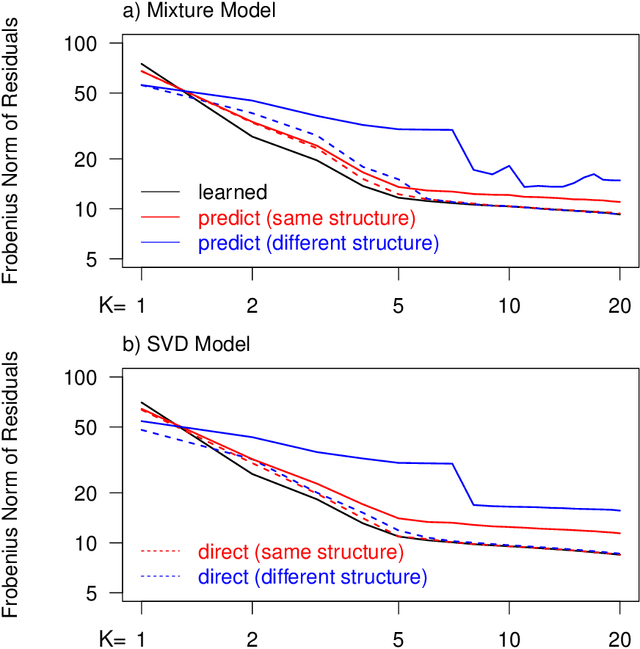

Integrating datasets from different disciplines is hard because the data are often qualitatively different in meaning, scale, and reliability. When two datasets describe the same entities, many scientific questions can be phrased around whether the similarities between entities are conserved. Our method, CLARITY, quantifies consistency across datasets, identifies where inconsistencies arise, and aids in their interpretation. We explore three diverse comparisons: Gene Methylation vs Gene Expression, evolution of language sounds vs word use, and country-level economic metrics vs cultural beliefs. The non-parametric approach is robust to noise and differences in scaling, and makes only weak assumptions about how the data were generated. It operates by decomposing similarities into two components: the `structural' component analogous to a clustering, and an underlying `relationship' between those structures. This allows a `structural comparison' between two similarity matrices using their predictability from `structure'. The software, CLARITY, is available as an R package from https://github.com/danjlawson/CLARITY.
Exploring Probabilistic Soft Logic as a framework for integrating top-down and bottom-up processing of language in a task context
Apr 15, 2020
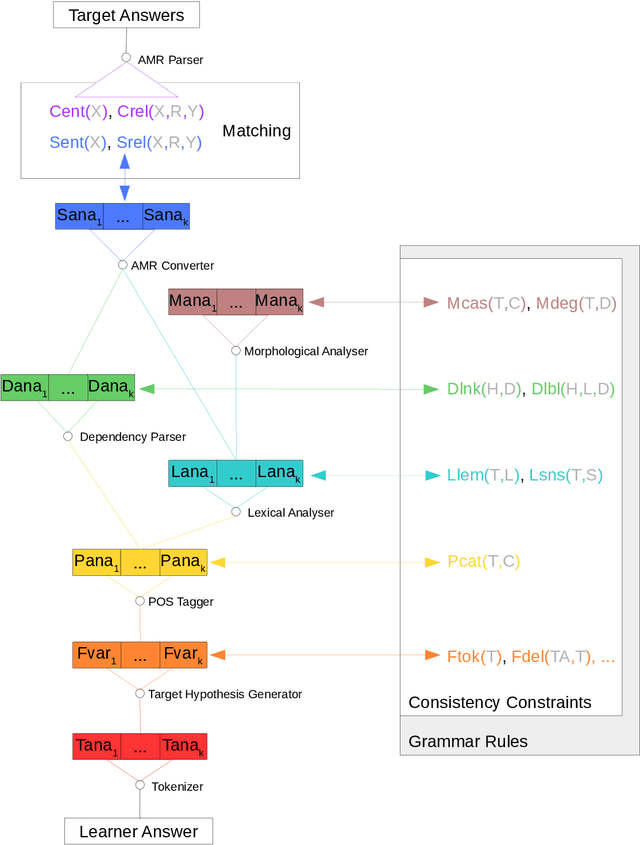
This technical report describes a new prototype architecture designed to integrate top-down and bottom-up analysis of non-standard linguistic input, where a semantic model of the context of an utterance is used to guide the analysis of the non-standard surface forms, including their automated normalization in context. While the architecture is generally applicable, as a concrete use case of the architecture we target the generation of semantically-informed target hypotheses for answers written by German learners in response to reading comprehension questions, where the reading context and possible target answers are given. The architecture integrates existing NLP components to produce candidate analyses on eight levels of linguistic modeling, all of which are broken down into atomic statements and connected into a large graphical model using Probabilistic Soft Logic (PSL) as a framework. Maximum a posteriori inference on the resulting graphical model then assigns a belief distribution to candidate target hypotheses. The current version of the architecture builds on Universal Dependencies (UD) as its representation formalism on the form level and on Abstract Meaning Representations (AMRs) to represent semantic analyses of learner answers and the context information provided by the target answers. These general choices will make it comparatively straightforward to apply the architecture to other tasks and other languages.
TuLiPA: Towards a Multi-Formalism Parsing Environment for Grammar Engineering
Jul 23, 2008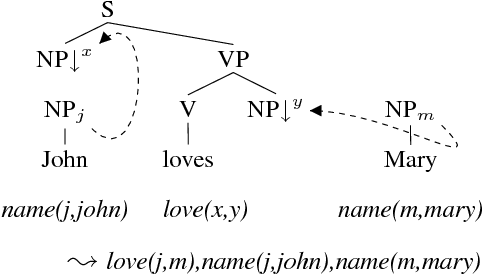
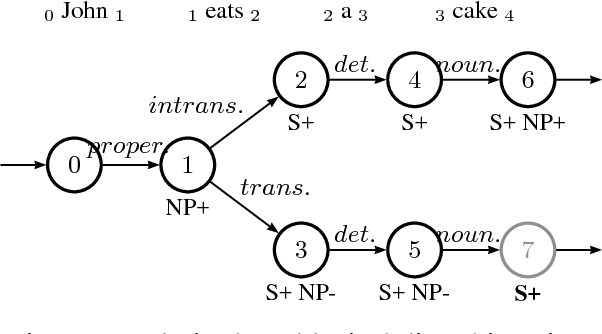
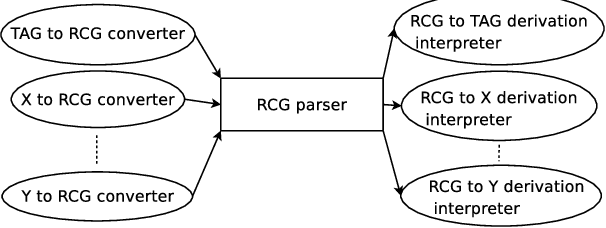

In this paper, we present an open-source parsing environment (Tuebingen Linguistic Parsing Architecture, TuLiPA) which uses Range Concatenation Grammar (RCG) as a pivot formalism, thus opening the way to the parsing of several mildly context-sensitive formalisms. This environment currently supports tree-based grammars (namely Tree-Adjoining Grammars, TAG) and Multi-Component Tree-Adjoining Grammars with Tree Tuples (TT-MCTAG)) and allows computation not only of syntactic structures, but also of the corresponding semantic representations. It is used for the development of a tree-based grammar for German.