 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeValid Bootstraps for Networks with Applications to Network Visualisation
Oct 29, 2024



Quantifying uncertainty in networks is an important step in modelling relationships and interactions between entities. We consider the challenge of bootstrapping an inhomogeneous random graph when only a single observation of the network is made and the underlying data generating function is unknown. We utilise an exchangeable network test that can empirically validate bootstrap samples generated by any method, by testing if the observed and bootstrapped networks are statistically distinguishable. We find that existing methods fail this test. To address this, we propose a principled, novel, distribution-free network bootstrap using k-nearest neighbour smoothing, that can regularly pass this exchangeable network test in both synthetic and real-data scenarios. We demonstrate the utility of this work in combination with the popular data visualisation method t-SNE, where uncertainty estimates from bootstrapping are used to explain whether visible structures represent real statistically sound structures.
Forecasting the 2016-2017 Central Apennines Earthquake Sequence with a Neural Point Process
Jan 24, 2023Point processes have been dominant in modeling the evolution of seismicity for decades, with the Epidemic Type Aftershock Sequence (ETAS) model being most popular. Recent advances in machine learning have constructed highly flexible point process models using neural networks to improve upon existing parametric models. We investigate whether these flexible point process models can be applied to short-term seismicity forecasting by extending an existing temporal neural model to the magnitude domain and we show how this model can forecast earthquakes above a target magnitude threshold. We first demonstrate that the neural model can fit synthetic ETAS data, however, requiring less computational time because it is not dependent on the full history of the sequence. By artificially emulating short-term aftershock incompleteness in the synthetic dataset, we find that the neural model outperforms ETAS. Using a new enhanced catalog from the 2016-2017 Central Apennines earthquake sequence, we investigate the predictive skill of ETAS and the neural model with respect to the lowest input magnitude. Constructing multiple forecasting experiments using the Visso, Norcia and Campotosto earthquakes to partition training and testing data, we target M3+ events. We find both models perform similarly at previously explored thresholds (e.g., above M3), but lowering the threshold to M1.2 reduces the performance of ETAS unlike the neural model. We argue that some of these gains are due to the neural model's ability to handle incomplete data. The robustness to missing data and speed to train the neural model present it as an encouraging competitor in earthquake forecasting.
CLARITY -- Comparing heterogeneous data using dissimiLARITY
May 29, 2020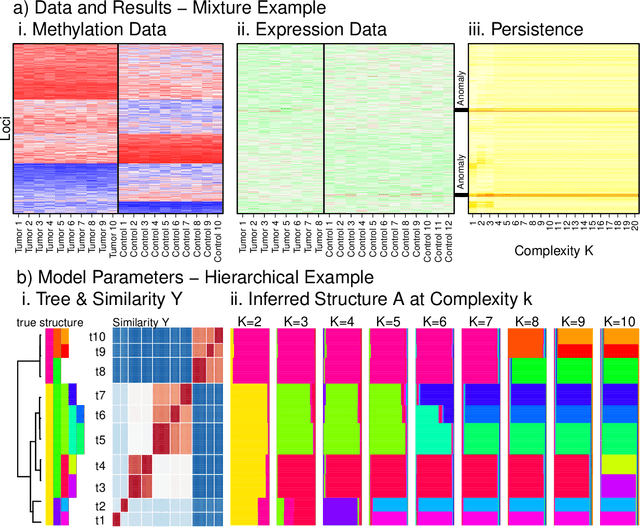
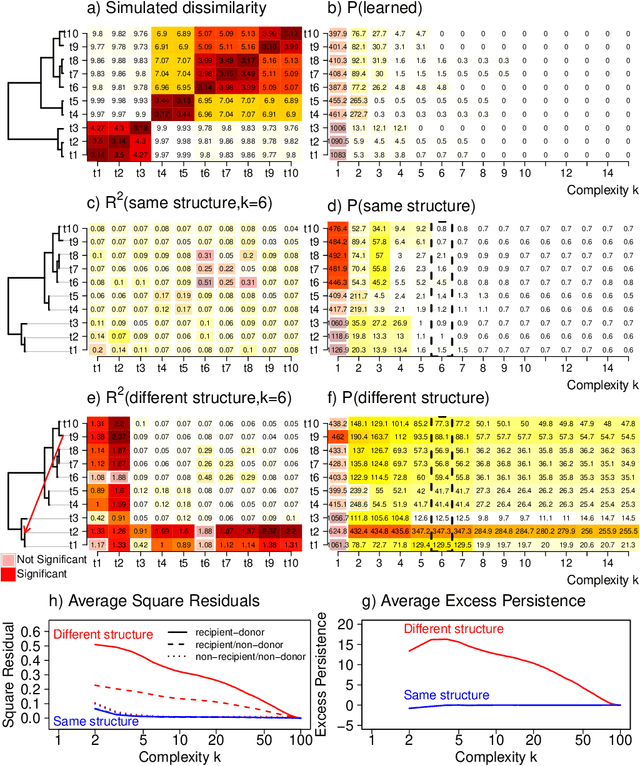
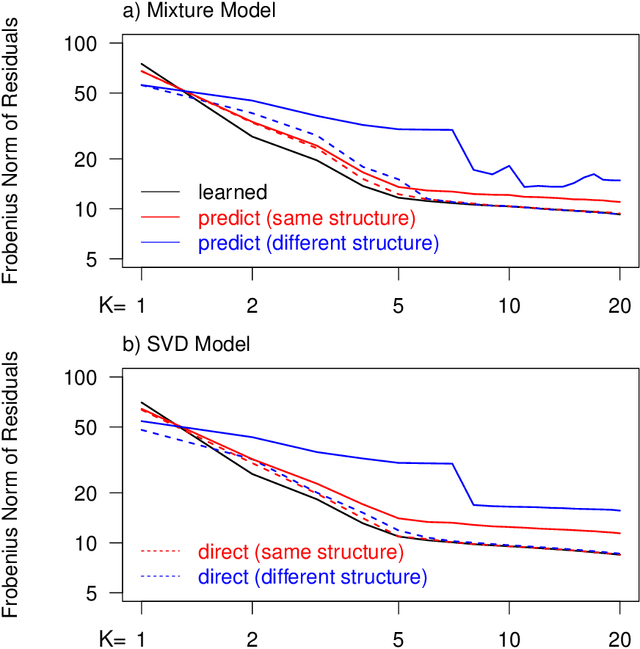

Integrating datasets from different disciplines is hard because the data are often qualitatively different in meaning, scale, and reliability. When two datasets describe the same entities, many scientific questions can be phrased around whether the similarities between entities are conserved. Our method, CLARITY, quantifies consistency across datasets, identifies where inconsistencies arise, and aids in their interpretation. We explore three diverse comparisons: Gene Methylation vs Gene Expression, evolution of language sounds vs word use, and country-level economic metrics vs cultural beliefs. The non-parametric approach is robust to noise and differences in scaling, and makes only weak assumptions about how the data were generated. It operates by decomposing similarities into two components: the `structural' component analogous to a clustering, and an underlying `relationship' between those structures. This allows a `structural comparison' between two similarity matrices using their predictability from `structure'. The software, CLARITY, is available as an R package from https://github.com/danjlawson/CLARITY.