 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCLARITY -- Comparing heterogeneous data using dissimiLARITY
Paper and Code
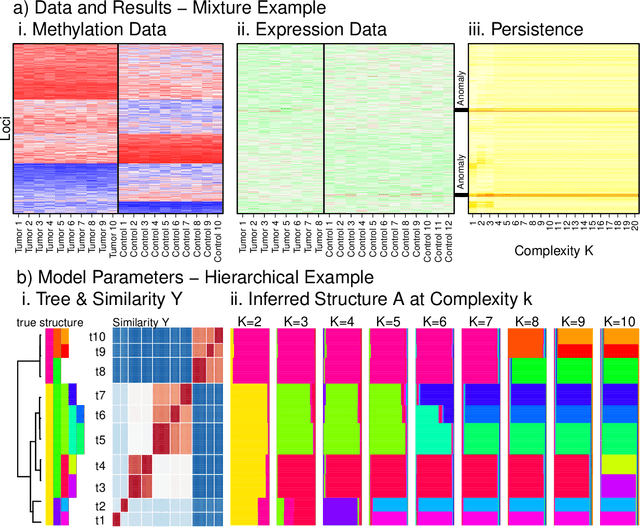
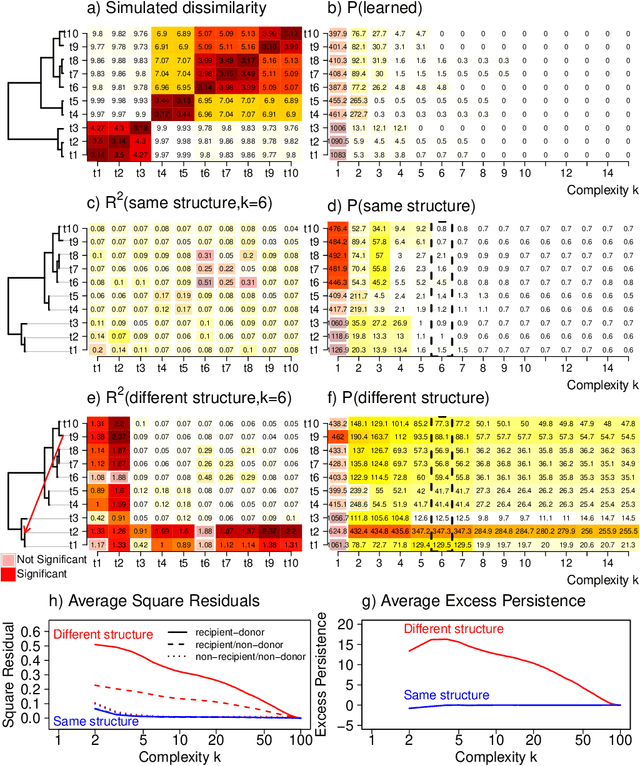
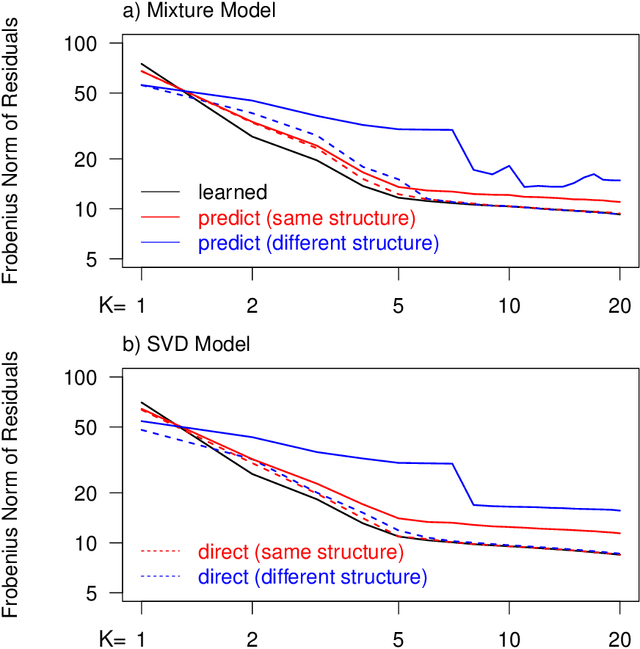

Integrating datasets from different disciplines is hard because the data are often qualitatively different in meaning, scale, and reliability. When two datasets describe the same entities, many scientific questions can be phrased around whether the similarities between entities are conserved. Our method, CLARITY, quantifies consistency across datasets, identifies where inconsistencies arise, and aids in their interpretation. We explore three diverse comparisons: Gene Methylation vs Gene Expression, evolution of language sounds vs word use, and country-level economic metrics vs cultural beliefs. The non-parametric approach is robust to noise and differences in scaling, and makes only weak assumptions about how the data were generated. It operates by decomposing similarities into two components: the `structural' component analogous to a clustering, and an underlying `relationship' between those structures. This allows a `structural comparison' between two similarity matrices using their predictability from `structure'. The software, CLARITY, is available as an R package from https://github.com/danjlawson/CLARITY.