 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSystem-Initiated Transitions from Chit-Chat to Task-Oriented Dialogues with Transition Info Extractor and Transition Sentence Generator
Aug 06, 2023
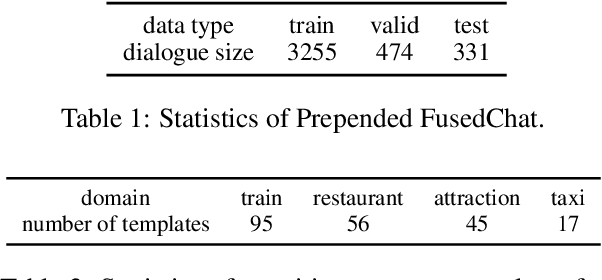


In this work, we study dialogue scenarios that start from chit-chat but eventually switch to task-related services, and investigate how a unified dialogue model, which can engage in both chit-chat and task-oriented dialogues, takes the initiative during the dialogue mode transition from chit-chat to task-oriented in a coherent and cooperative manner. We firstly build a {transition info extractor} (TIE) that keeps track of the preceding chit-chat interaction and detects the potential user intention to switch to a task-oriented service. Meanwhile, in the unified model, a {transition sentence generator} (TSG) is extended through efficient Adapter tuning and transition prompt learning. When the TIE successfully finds task-related information from the preceding chit-chat, such as a transition domain, then the TSG is activated automatically in the unified model to initiate this transition by generating a transition sentence under the guidance of transition information extracted by TIE. The experimental results show promising performance regarding the proactive transitions. We achieve an additional large improvement on TIE model by utilizing Conditional Random Fields (CRF). The TSG can flexibly generate transition sentences while maintaining the unified capabilities of normal chit-chat and task-oriented response generation.
Unified Conversational Models with System-Initiated Transitions between Chit-Chat and Task-Oriented Dialogues
Jul 04, 2023Spoken dialogue systems (SDSs) have been separately developed under two different categories, task-oriented and chit-chat. The former focuses on achieving functional goals and the latter aims at creating engaging social conversations without special goals. Creating a unified conversational model that can engage in both chit-chat and task-oriented dialogue is a promising research topic in recent years. However, the potential ``initiative'' that occurs when there is a change between dialogue modes in one dialogue has rarely been explored. In this work, we investigate two kinds of dialogue scenarios, one starts from chit-chat implicitly involving task-related topics and finally switching to task-oriented requests; the other starts from task-oriented interaction and eventually changes to casual chat after all requested information is provided. We contribute two efficient prompt models which can proactively generate a transition sentence to trigger system-initiated transitions in a unified dialogue model. One is a discrete prompt model trained with two discrete tokens, the other one is a continuous prompt model using continuous prompt embeddings automatically generated by a classifier. We furthermore show that the continuous prompt model can also be used to guide the proactive transitions between particular domains in a multi-domain task-oriented setting.
ConceptNet infused DialoGPT for Underlying Commonsense Understanding and Reasoning in Dialogue Response Generation
Sep 29, 2022
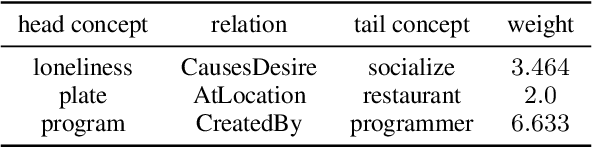

The pre-trained conversational models still fail to capture the implicit commonsense (CS) knowledge hidden in the dialogue interaction, even though they were pre-trained with an enormous dataset. In order to build a dialogue agent with CS capability, we firstly inject external knowledge into a pre-trained conversational model to establish basic commonsense through efficient Adapter tuning (Section 4). Secondly, we propose the ``two-way learning'' method to enable the bidirectional relationship between CS knowledge and sentence pairs so that the model can generate a sentence given the CS triplets, also generate the underlying CS knowledge given a sentence (Section 5). Finally, we leverage this integrated CS capability to improve open-domain dialogue response generation so that the dialogue agent is capable of understanding the CS knowledge hidden in dialogue history on top of inferring related other knowledge to further guide response generation (Section 6). The experiment results demonstrate that CS\_Adapter fusion helps DialoGPT to be able to generate series of CS knowledge. And the DialoGPT+CS\_Adapter response model adapted from CommonGen training can generate underlying CS triplets that fits better to dialogue context.
Context Matters in Semantically Controlled Language Generation for Task-oriented Dialogue Systems
Nov 28, 2021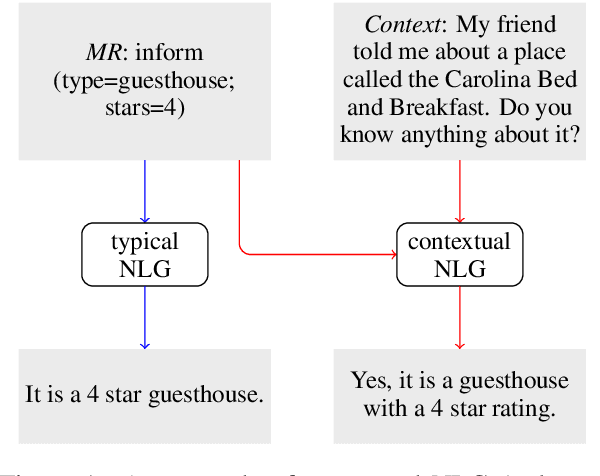

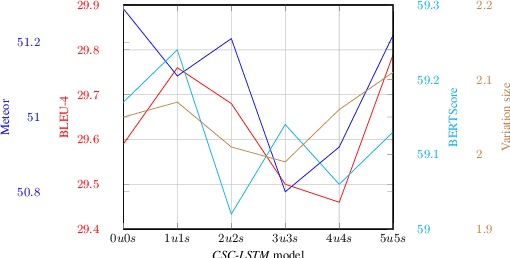
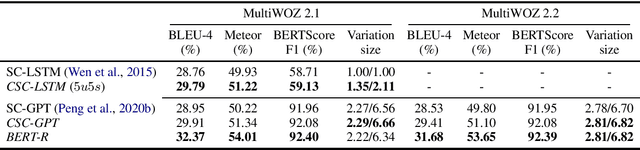
This work combines information about the dialogue history encoded by pre-trained model with a meaning representation of the current system utterance to realize contextual language generation in task-oriented dialogues. We utilize the pre-trained multi-context ConveRT model for context representation in a model trained from scratch; and leverage the immediate preceding user utterance for context generation in a model adapted from the pre-trained GPT-2. Both experiments with the MultiWOZ dataset show that contextual information encoded by pre-trained model improves the performance of response generation both in automatic metrics and human evaluation. Our presented contextual generator enables higher variety of generated responses that fit better to the ongoing dialogue. Analysing the context size shows that longer context does not automatically lead to better performance, but the immediate preceding user utterance plays an essential role for contextual generation. In addition, we also propose a re-ranker for the GPT-based generation model. The experiments show that the response selected by the re-ranker has a significant improvement on automatic metrics.
Empathetic Dialogue Generation with Pre-trained RoBERTa-GPT2 and External Knowledge
Sep 07, 2021

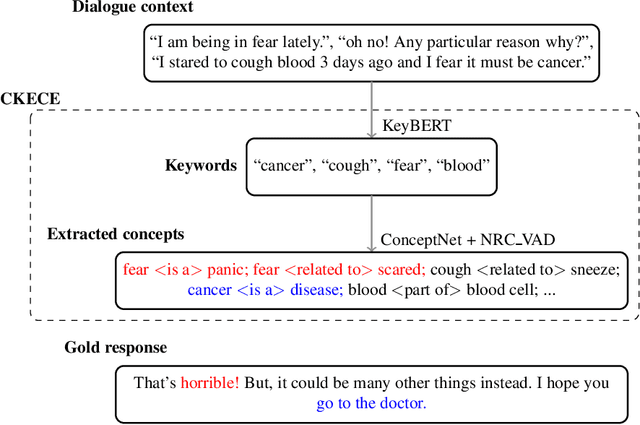
One challenge for dialogue agents is to recognize feelings of the conversation partner and respond accordingly. In this work, RoBERTa-GPT2 is proposed for empathetic dialogue generation, where the pre-trained auto-encoding RoBERTa is utilised as encoder and the pre-trained auto-regressive GPT-2 as decoder. With the combination of the pre-trained RoBERTa and GPT-2, our model realizes a new state-of-the-art emotion accuracy. To enable the empathetic ability of RoBERTa-GPT2 model, we propose a commonsense knowledge and emotional concepts extractor, in which the commonsensible and emotional concepts of dialogue context are extracted for the GPT-2 decoder. The experiment results demonstrate that the empathetic dialogue generation benefits from both pre-trained encoder-decoder architecture and external knowledge.
Naturalness Evaluation of Natural Language Generation in Task-oriented Dialogues using BERT
Sep 07, 2021
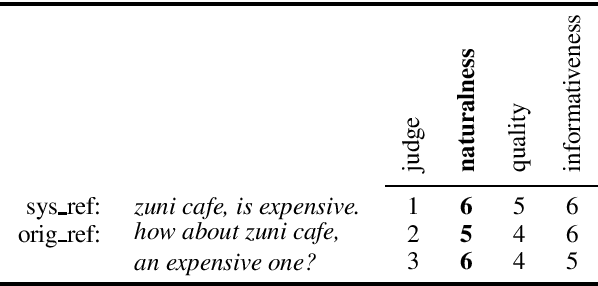

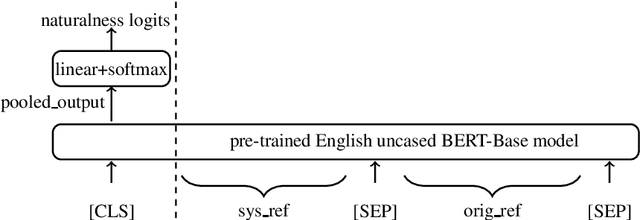
This paper presents an automatic method to evaluate the naturalness of natural language generation in dialogue systems. While this task was previously rendered through expensive and time-consuming human labor, we present this novel task of automatic naturalness evaluation of generated language. By fine-tuning the BERT model, our proposed naturalness evaluation method shows robust results and outperforms the baselines: support vector machines, bi-directional LSTMs, and BLEURT. In addition, the training speed and evaluation performance of naturalness model are improved by transfer learning from quality and informativeness linguistic knowledge.
TuLiPA: Towards a Multi-Formalism Parsing Environment for Grammar Engineering
Jul 23, 2008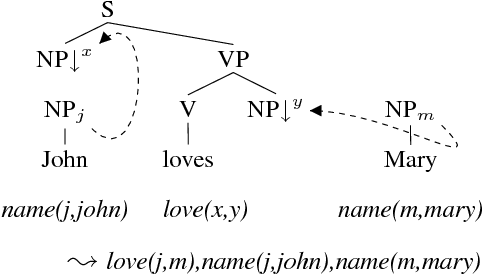
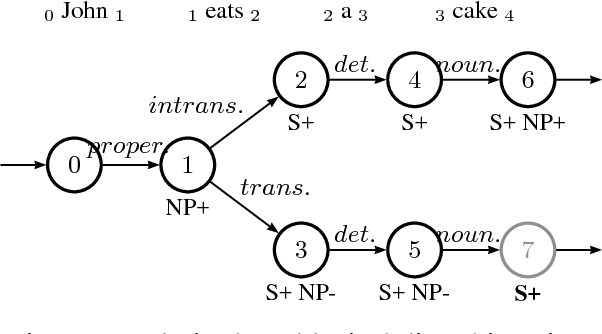
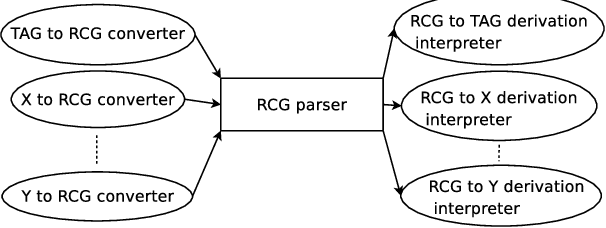

In this paper, we present an open-source parsing environment (Tuebingen Linguistic Parsing Architecture, TuLiPA) which uses Range Concatenation Grammar (RCG) as a pivot formalism, thus opening the way to the parsing of several mildly context-sensitive formalisms. This environment currently supports tree-based grammars (namely Tree-Adjoining Grammars, TAG) and Multi-Component Tree-Adjoining Grammars with Tree Tuples (TT-MCTAG)) and allows computation not only of syntactic structures, but also of the corresponding semantic representations. It is used for the development of a tree-based grammar for German.