 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Diversity Diet for a Healthier Model: A Case Study of French ModernBERT
Feb 25, 2026Diversity has been gaining interest in the NLP community in recent years. At the same time, state-of-the-art transformer models such as ModernBERT use very large pre-training datasets, which are driven by size rather than by diversity. This summons for an investigation of the impact of diversity on the ModernBERT pre-training. We do so in this study, with the express intent of reducing pre-training dataset size, while retaining at least comparable performance. We compare diversity-driven sampling algorithms, so as to pick the best one. We find that diversity-driven sampling allows in some tasks to gain 10 points relative to randomly-sampled pre-training data of commensurate size. We also see that a model pre-trained for 483h on a diversity-driven dataset of 150M tokens can yield a commensurate performance to a model pre-trained for 1,775h on a randomly-driven dataset of 2.4B tokens.
A survey of diversity quantification in natural language processing: The why, what, where and how
Jul 28, 2025The concept of diversity has received increased consideration in Natural Language Processing (NLP) in recent years. This is due to various motivations like promoting and inclusion, approximating human linguistic behavior, and increasing systems' performance. Diversity has however often been addressed in an ad hoc manner in NLP, and with few explicit links to other domains where this notion is better theorized. We survey articles in the ACL Anthology from the past 6 years, with "diversity" or "diverse" in their title. We find a wide range of settings in which diversity is quantified, often highly specialized and using inconsistent terminology. We put forward a unified taxonomy of why, what on, where, and how diversity is measured in NLP. Diversity measures are cast upon a unified framework from ecology and economy (Stirling, 2007) with 3 dimensions of diversity: variety, balance and disparity. We discuss the trends which emerge due to this systematized approach. We believe that this study paves the way towards a better formalization of diversity in NLP, which should bring a better understanding of this notion and a better comparability between various approaches.
Formalising lexical and syntactic diversity for data sampling in French
Jan 14, 2025Diversity is an important property of datasets and sampling data for diversity is useful in dataset creation. Finding the optimally diverse sample is expensive, we therefore present a heuristic significantly increasing diversity relative to random sampling. We also explore whether different kinds of diversity -- lexical and syntactic -- correlate, with the purpose of sampling for expensive syntactic diversity through inexpensive lexical diversity. We find that correlations fluctuate with different datasets and versions of diversity measures. This shows that an arbitrarily chosen measure may fall short of capturing diversity-related properties of datasets.
To Be or Not To Be a Verbal Multiword Expression: A Quest for Discriminating Features
Jul 22, 2020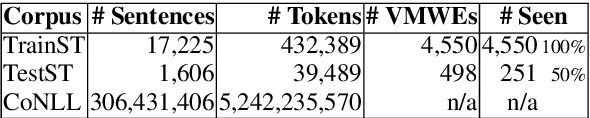
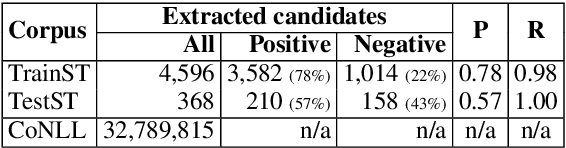
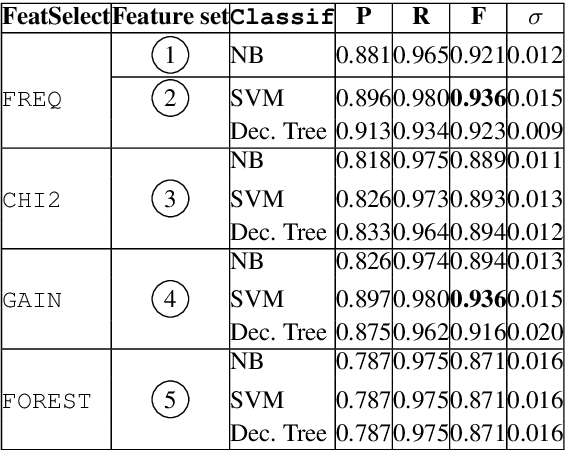

Automatic identification of mutiword expressions (MWEs) is a pre-requisite for semantically-oriented downstream applications. This task is challenging because MWEs, especially verbal ones (VMWEs), exhibit surface variability. However, this variability is usually more restricted than in regular (non-VMWE) constructions, which leads to various variability profiles. We use this fact to determine the optimal set of features which could be used in a supervised classification setting to solve a subproblem of VMWE identification: the identification of occurrences of previously seen VMWEs. Surprisingly, a simple custom frequency-based feature selection method proves more efficient than other standard methods such as Chi-squared test, information gain or decision trees. An SVM classifier using the optimal set of only 6 features outperforms the best systems from a recent shared task on the French seen data.
Object-oriented lexical encoding of multiword expressions: Short and sweet
Oct 23, 2018
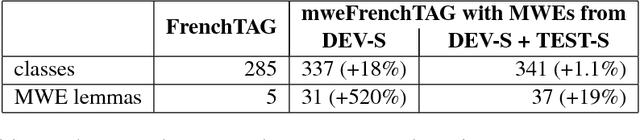


Multiword expressions (MWEs) exhibit both regular and idiosyncratic properties. Their idiosyncrasy requires lexical encoding in parallel with their component words. Their (at times intricate) regularity, on the other hand, calls for means of flexible factorization to avoid redundant descriptions of shared properties. However, so far, non-redundant general-purpose lexical encoding of MWEs has not received a satisfactory solution. We offer a proof of concept that this challenge might be effectively addressed within eXtensible MetaGrammar (XMG), an object-oriented metagrammar framework. We first make an existing metagrammatical resource, the FrenchTAG grammar, MWE-aware. We then evaluate the factorization gain during incremental implementation with XMG on a dataset extracted from an MWE-annotated reference corpus.