 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExperimental study of time series forecasting methods for groundwater level prediction
Sep 28, 2022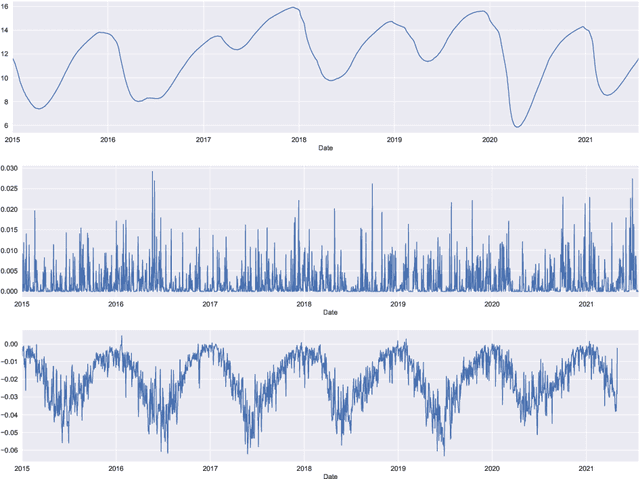
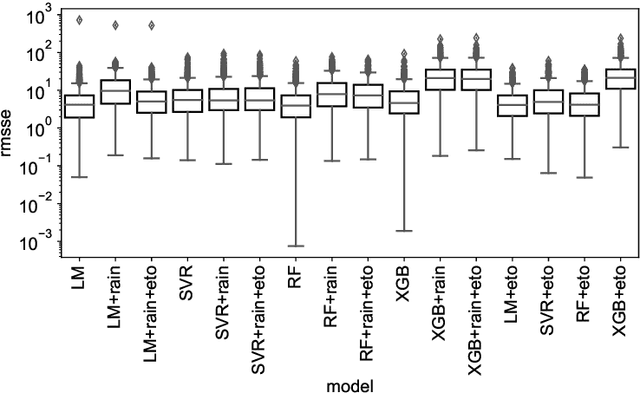
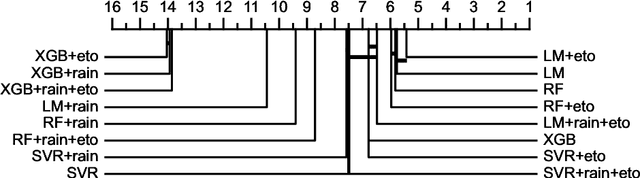
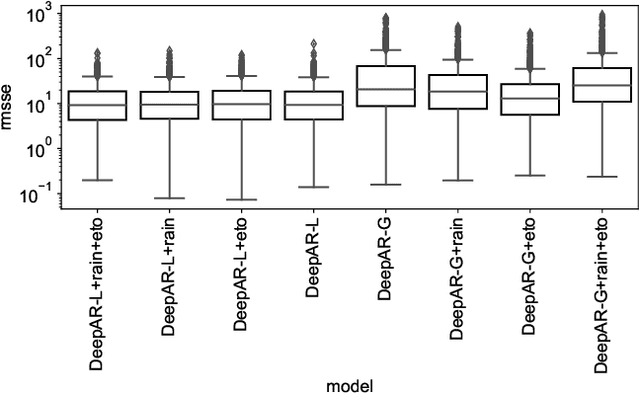
Groundwater level prediction is an applied time series forecasting task with important social impacts to optimize water management as well as preventing some natural disasters: for instance, floods or severe droughts. Machine learning methods have been reported in the literature to achieve this task, but they are only focused on the forecast of the groundwater level at a single location. A global forecasting method aims at exploiting the groundwater level time series from a wide range of locations to produce predictions at a single place or at several places at a time. Given the recent success of global forecasting methods in prestigious competitions, it is meaningful to assess them on groundwater level prediction and see how they are compared to local methods. In this work, we created a dataset of 1026 groundwater level time series. Each time series is made of daily measurements of groundwater levels and two exogenous variables, rainfall and evapotranspiration. This dataset is made available to the communities for reproducibility and further evaluation. To identify the best configuration to effectively predict groundwater level for the complete set of time series, we compared different predictors including local and global time series forecasting methods. We assessed the impact of exogenous variables. Our result analysis shows that the best predictions are obtained by training a global method on past groundwater levels and rainfall data.
To Be or Not To Be a Verbal Multiword Expression: A Quest for Discriminating Features
Jul 22, 2020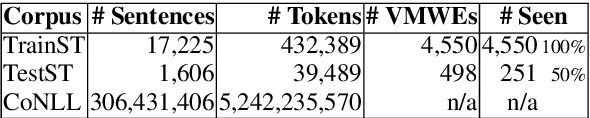
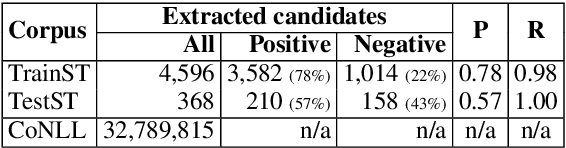
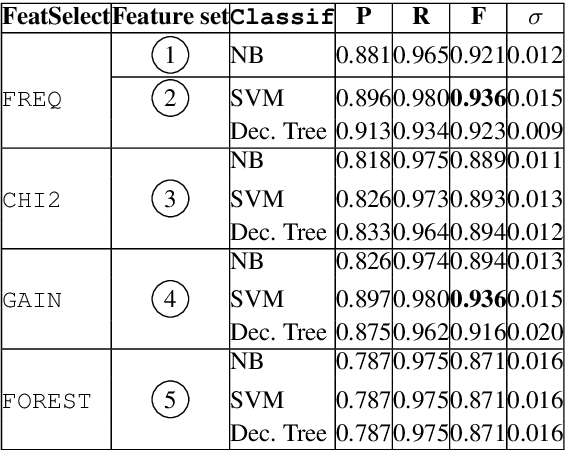

Automatic identification of mutiword expressions (MWEs) is a pre-requisite for semantically-oriented downstream applications. This task is challenging because MWEs, especially verbal ones (VMWEs), exhibit surface variability. However, this variability is usually more restricted than in regular (non-VMWE) constructions, which leads to various variability profiles. We use this fact to determine the optimal set of features which could be used in a supervised classification setting to solve a subproblem of VMWE identification: the identification of occurrences of previously seen VMWEs. Surprisingly, a simple custom frequency-based feature selection method proves more efficient than other standard methods such as Chi-squared test, information gain or decision trees. An SVM classifier using the optimal set of only 6 features outperforms the best systems from a recent shared task on the French seen data.