 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSoft-ECM: An extension of Evidential C-Means for complex data
Jul 17, 2025Clustering based on belief functions has been gaining increasing attention in the machine learning community due to its ability to effectively represent uncertainty and/or imprecision. However, none of the existing algorithms can be applied to complex data, such as mixed data (numerical and categorical) or non-tabular data like time series. Indeed, these types of data are, in general, not represented in a Euclidean space and the aforementioned algorithms make use of the properties of such spaces, in particular for the construction of barycenters. In this paper, we reformulate the Evidential C-Means (ECM) problem for clustering complex data. We propose a new algorithm, Soft-ECM, which consistently positions the centroids of imprecise clusters requiring only a semi-metric. Our experiments show that Soft-ECM present results comparable to conventional fuzzy clustering approaches on numerical data, and we demonstrate its ability to handle mixed data and its benefits when combining fuzzy clustering with semi-metrics such as DTW for time series data.
Vascular Segmentation of Functional Ultrasound Images using Deep Learning
Oct 28, 2024
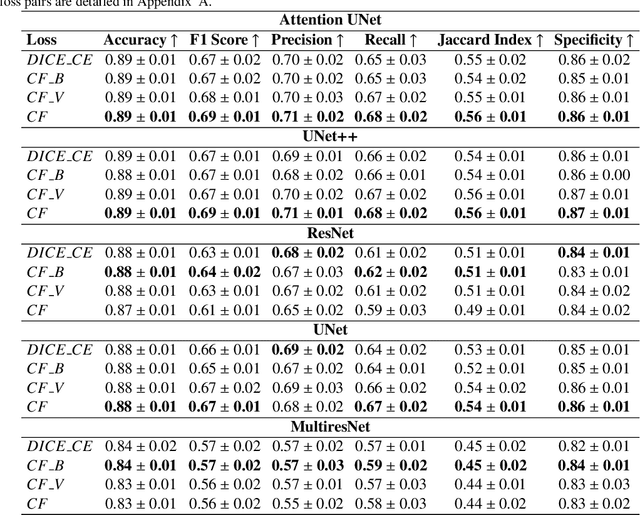


Segmentation of medical images is a fundamental task with numerous applications. While MRI, CT, and PET modalities have significantly benefited from deep learning segmentation techniques, more recent modalities, like functional ultrasound (fUS), have seen limited progress. fUS is a non invasive imaging method that measures changes in cerebral blood volume (CBV) with high spatio-temporal resolution. However, distinguishing arterioles from venules in fUS is challenging due to opposing blood flow directions within the same pixel. Ultrasound localization microscopy (ULM) can enhance resolution by tracking microbubble contrast agents but is invasive, and lacks dynamic CBV quantification. In this paper, we introduce the first deep learning-based segmentation tool for fUS images, capable of differentiating signals from different vascular compartments, based on ULM automatic annotation and enabling dynamic CBV quantification. We evaluate various UNet architectures on fUS images of rat brains, achieving competitive segmentation performance, with 90% accuracy, a 71% F1 score, and an IoU of 0.59, using only 100 temporal frames from a fUS stack. These results are comparable to those from tubular structure segmentation in other imaging modalities. Additionally, models trained on resting-state data generalize well to images captured during visual stimulation, highlighting robustness. This work offers a non-invasive, cost-effective alternative to ULM, enhancing fUS data interpretation and improving understanding of vessel function. Our pipeline shows high linear correlation coefficients between signals from predicted and actual compartments in both cortical and deeperregions, showcasing its ability to accurately capture blood flow dynamics.
Clustering of timed sequences -- Application to the analysis of care pathways
Apr 23, 2024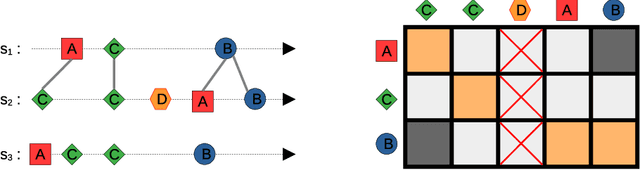

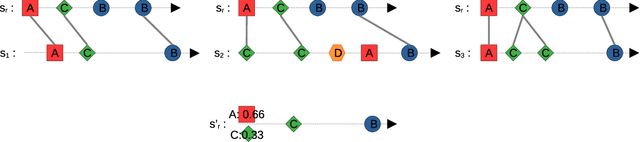

Improving the future of healthcare starts by better understanding the current actual practices in hospitals. This motivates the objective of discovering typical care pathways from patient data. Revealing homogeneous groups of care pathways can be achieved through clustering. The difficulty in clustering care pathways, represented by sequences of timestamped events, lies in defining a semantically appropriate metric and clustering algorithms. In this article, we adapt two methods developed for time series to time sequences: the drop-DTW metric and the DBA approach for the construction of averaged time sequences. These methods are then applied in clustering algorithms to propose original and sound clustering algorithms for timed sequences. This approach is experimented with and evaluated on synthetic and real use cases.
SWoTTeD: An Extension of Tensor Decomposition to Temporal Phenotyping
Oct 02, 2023Tensor decomposition has recently been gaining attention in the machine learning community for the analysis of individual traces, such as Electronic Health Records (EHR). However, this task becomes significantly more difficult when the data follows complex temporal patterns. This paper introduces the notion of a temporal phenotype as an arrangement of features over time and it proposes SWoTTeD (Sliding Window for Temporal Tensor Decomposition), a novel method to discover hidden temporal patterns. SWoTTeD integrates several constraints and regularizations to enhance the interpretability of the extracted phenotypes. We validate our proposal using both synthetic and real-world datasets, and we present an original usecase using data from the Greater Paris University Hospital. The results show that SWoTTeD achieves at least as accurate reconstruction as recent state-of-the-art tensor decomposition models, and extracts temporal phenotypes that are meaningful for clinicians.
A survey on the semantics of sequential patterns with negation
Sep 20, 2023



A sequential pattern with negation, or negative sequential pattern, takes the form of a sequential pattern for which the negation symbol may be used in front of some of the pattern's itemsets. Intuitively, such a pattern occurs in a sequence if negated itemsets are absent in the sequence. Recent work has shown that different semantics can be attributed to these pattern forms, and that state-of-the-art algorithms do not extract the same sets of patterns. This raises the important question of the interpretability of sequential pattern with negation. In this study, our focus is on exploring how potential users perceive negation in sequential patterns. Our aim is to determine whether specific semantics are more "intuitive" than others and whether these align with the semantics employed by one or more state-of-the-art algorithms. To achieve this, we designed a questionnaire to reveal the semantics' intuition of each user. This article presents both the design of the questionnaire and an in-depth analysis of the 124 responses obtained. The outcomes indicate that two of the semantics are predominantly intuitive; however, neither of them aligns with the semantics of the primary state-of-the-art algorithms. As a result, we provide recommendations to account for this disparity in the conclusions drawn.
Generating robust counterfactual explanations
Apr 24, 2023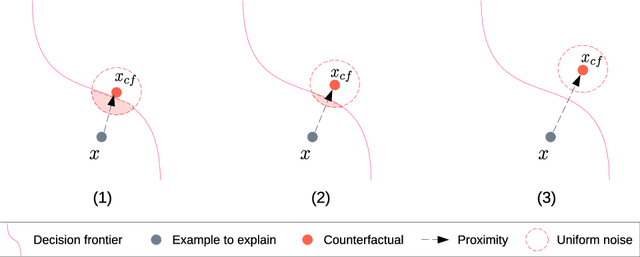



Counterfactual explanations have become a mainstay of the XAI field. This particularly intuitive statement allows the user to understand what small but necessary changes would have to be made to a given situation in order to change a model prediction. The quality of a counterfactual depends on several criteria: realism, actionability, validity, robustness, etc. In this paper, we are interested in the notion of robustness of a counterfactual. More precisely, we focus on robustness to counterfactual input changes. This form of robustness is particularly challenging as it involves a trade-off between the robustness of the counterfactual and the proximity with the example to explain. We propose a new framework, CROCO, that generates robust counterfactuals while managing effectively this trade-off, and guarantees the user a minimal robustness. An empirical evaluation on tabular datasets confirms the relevance and effectiveness of our approach.
Temporal Disaggregation of the Cumulative Grass Growth
Dec 21, 2022Information on the grass growth over a year is essential for some models simulating the use of this resource to feed animals on pasture or at barn with hay or grass silage. Unfortunately, this information is rarely available. The challenge is to reconstruct grass growth from two sources of information: usual daily climate data (rainfall, radiation, etc.) and cumulative growth over the year. We have to be able to capture the effect of seasonal climatic events which are known to distort the growth curve within the year. In this paper, we formulate this challenge as a problem of disaggregating the cumulative growth into a time series. To address this problem, our method applies time series forecasting using climate information and grass growth from previous time steps. Several alternatives of the method are proposed and compared experimentally using a database generated from a grassland process-based model. The results show that our method can accurately reconstruct the time series, independently of the use of the cumulative growth information.
VCNet: A self-explaining model for realistic counterfactual generation
Dec 21, 2022



Counterfactual explanation is a common class of methods to make local explanations of machine learning decisions. For a given instance, these methods aim to find the smallest modification of feature values that changes the predicted decision made by a machine learning model. One of the challenges of counterfactual explanation is the efficient generation of realistic counterfactuals. To address this challenge, we propose VCNet-Variational Counter Net-a model architecture that combines a predictor and a counterfactual generator that are jointly trained, for regression or classification tasks. VCNet is able to both generate predictions, and to generate counterfactual explanations without having to solve another minimisation problem. Our contribution is the generation of counterfactuals that are close to the distribution of the predicted class. This is done by learning a variational autoencoder conditionally to the output of the predictor in a join-training fashion. We present an empirical evaluation on tabular datasets and across several interpretability metrics. The results are competitive with the state-of-the-art method.
Experimental study of time series forecasting methods for groundwater level prediction
Sep 28, 2022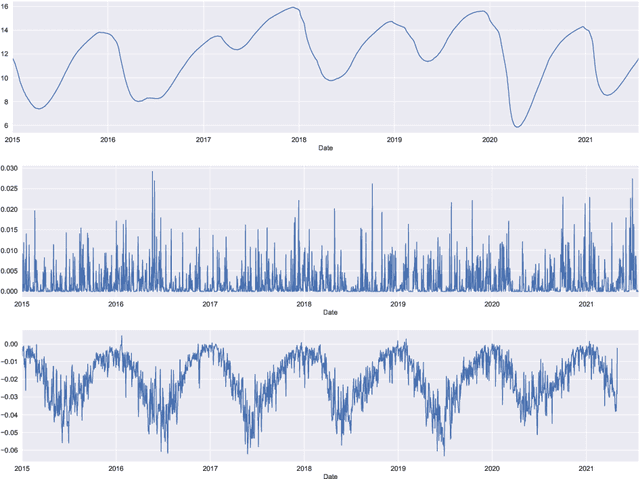
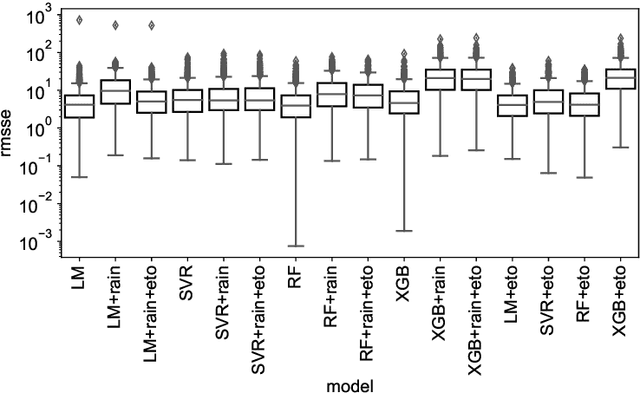
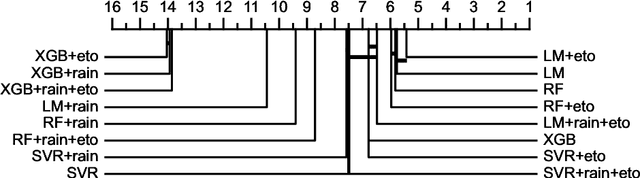
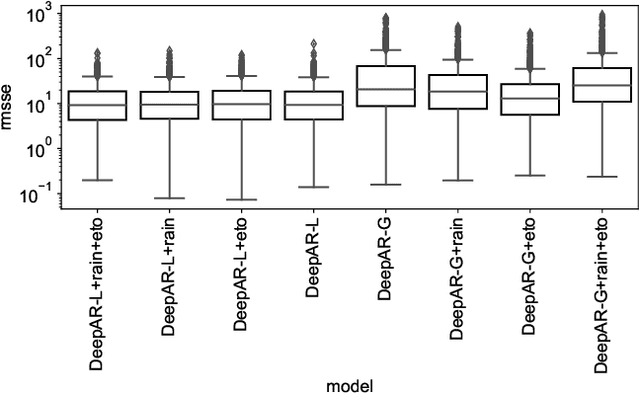
Groundwater level prediction is an applied time series forecasting task with important social impacts to optimize water management as well as preventing some natural disasters: for instance, floods or severe droughts. Machine learning methods have been reported in the literature to achieve this task, but they are only focused on the forecast of the groundwater level at a single location. A global forecasting method aims at exploiting the groundwater level time series from a wide range of locations to produce predictions at a single place or at several places at a time. Given the recent success of global forecasting methods in prestigious competitions, it is meaningful to assess them on groundwater level prediction and see how they are compared to local methods. In this work, we created a dataset of 1026 groundwater level time series. Each time series is made of daily measurements of groundwater levels and two exogenous variables, rainfall and evapotranspiration. This dataset is made available to the communities for reproducibility and further evaluation. To identify the best configuration to effectively predict groundwater level for the complete set of time series, we compared different predictors including local and global time series forecasting methods. We assessed the impact of exogenous variables. Our result analysis shows that the best predictions are obtained by training a global method on past groundwater levels and rainfall data.
Incremental Mining of Frequent Serial Episodes Considering Multiple Occurrence
Feb 03, 2022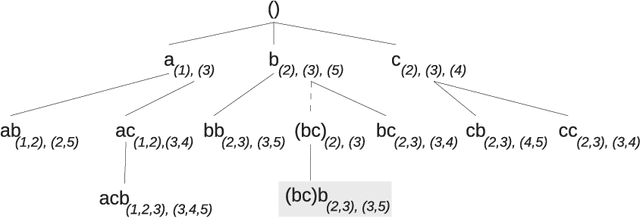
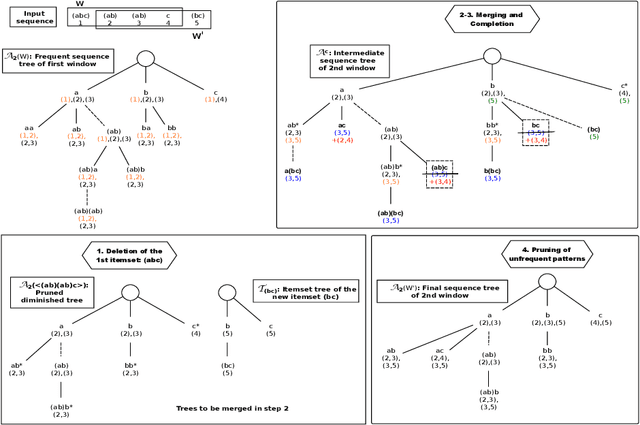
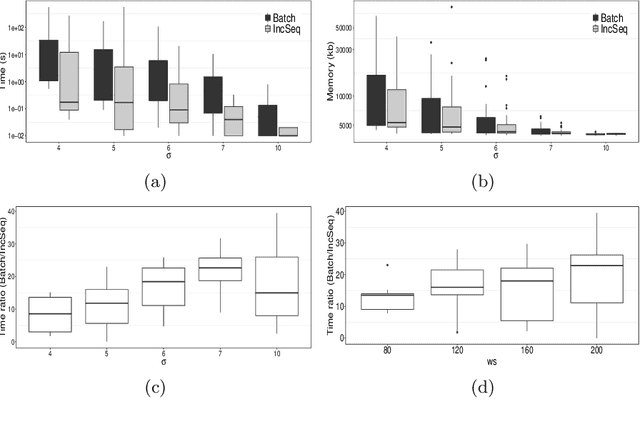

The need to analyze information from streams arises in a variety of applications. One of the fundamental research directions is to mine sequential patterns over data streams. Current studies mine series of items based on the existence of the pattern in transactions but pay no attention to the series of itemsets and their multiple occurrences. The pattern over a window of itemsets stream and their multiple occurrences, however, provides additional capability to recognize the essential characteristics of the patterns and the inter-relationships among them that are unidentifiable by the existing items and existence based studies. In this paper, we study such a new sequential pattern mining problem and propose a corresponding efficient sequential miner with novel strategies to prune search space efficiently. Experiments on both real and synthetic data show the utility of our approach.