 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExperimental study of time series forecasting methods for groundwater level prediction
Sep 28, 2022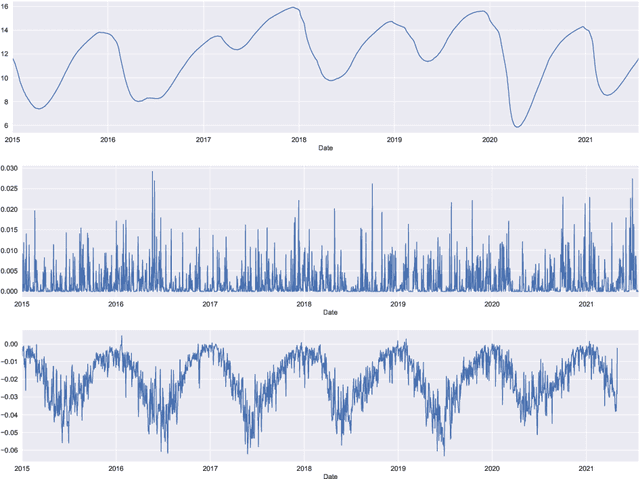
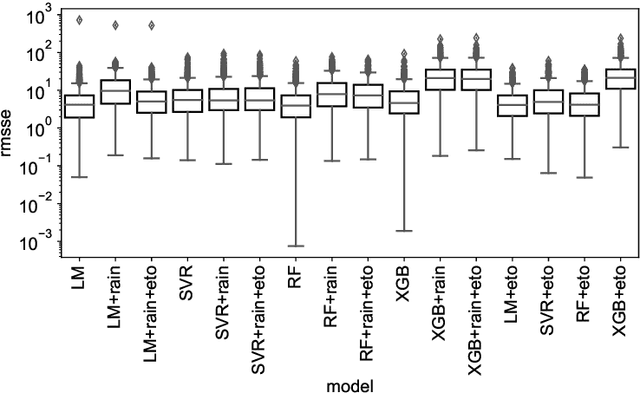
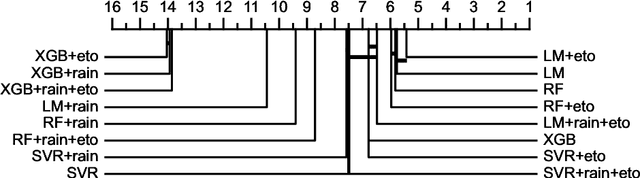
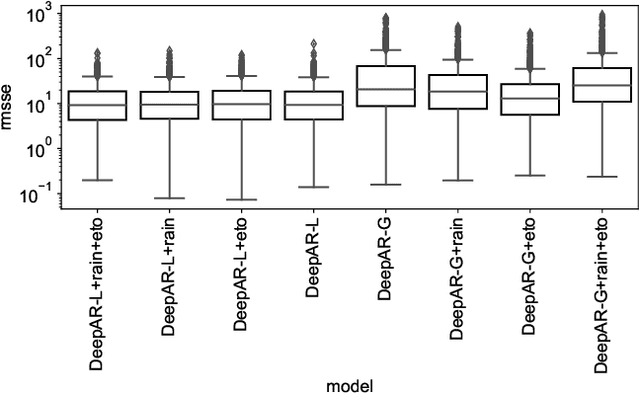
Groundwater level prediction is an applied time series forecasting task with important social impacts to optimize water management as well as preventing some natural disasters: for instance, floods or severe droughts. Machine learning methods have been reported in the literature to achieve this task, but they are only focused on the forecast of the groundwater level at a single location. A global forecasting method aims at exploiting the groundwater level time series from a wide range of locations to produce predictions at a single place or at several places at a time. Given the recent success of global forecasting methods in prestigious competitions, it is meaningful to assess them on groundwater level prediction and see how they are compared to local methods. In this work, we created a dataset of 1026 groundwater level time series. Each time series is made of daily measurements of groundwater levels and two exogenous variables, rainfall and evapotranspiration. This dataset is made available to the communities for reproducibility and further evaluation. To identify the best configuration to effectively predict groundwater level for the complete set of time series, we compared different predictors including local and global time series forecasting methods. We assessed the impact of exogenous variables. Our result analysis shows that the best predictions are obtained by training a global method on past groundwater levels and rainfall data.
Explainable classification of astronomical uncertain time series
Sep 28, 2022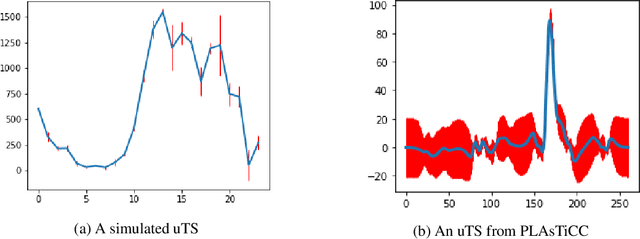
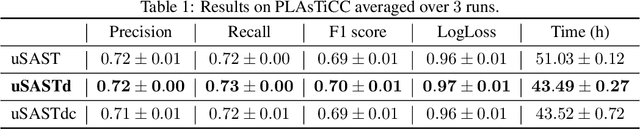
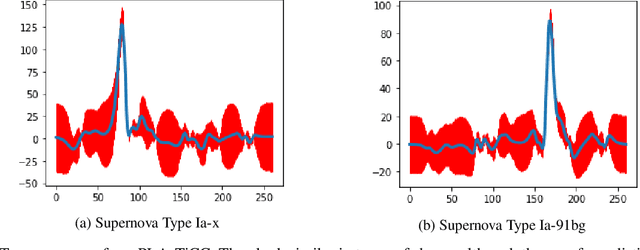
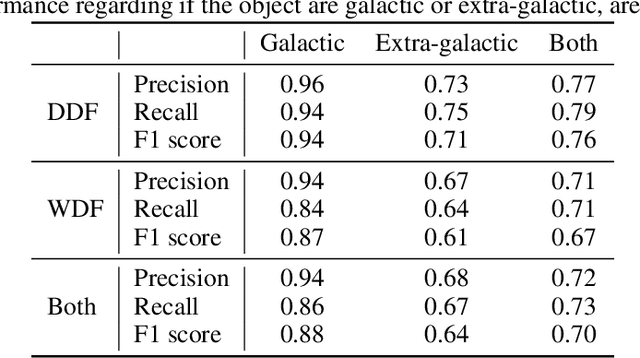
Exploring the expansion history of the universe, understanding its evolutionary stages, and predicting its future evolution are important goals in astrophysics. Today, machine learning tools are used to help achieving these goals by analyzing transient sources, which are modeled as uncertain time series. Although black-box methods achieve appreciable performance, existing interpretable time series methods failed to obtain acceptable performance for this type of data. Furthermore, data uncertainty is rarely taken into account in these methods. In this work, we propose an uncertaintyaware subsequence based model which achieves a classification comparable to that of state-of-the-art methods. Unlike conformal learning which estimates model uncertainty on predictions, our method takes data uncertainty as additional input. Moreover, our approach is explainable-by-design, giving domain experts the ability to inspect the model and explain its predictions. The explainability of the proposed method has also the potential to inspire new developments in theoretical astrophysics modeling by suggesting important subsequences which depict details of light curve shapes. The dataset, the source code of our experiment, and the results are made available on a public repository.
Uncertain Time Series Classification With Shapelet Transform
Feb 03, 2021
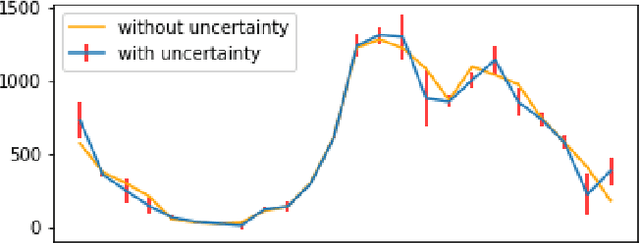
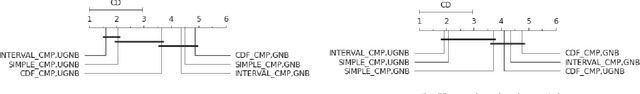

Time series classification is a task that aims at classifying chronological data. It is used in a diverse range of domains such as meteorology, medicine and physics. In the last decade, many algorithms have been built to perform this task with very appreciable accuracy. However, applications where time series have uncertainty has been under-explored. Using uncertainty propagation techniques, we propose a new uncertain dissimilarity measure based on Euclidean distance. We then propose the uncertain shapelet transform algorithm for the classification of uncertain time series. The large experiments we conducted on state of the art datasets show the effectiveness of our contribution. The source code of our contribution and the datasets we used are all available on a public repository.
Neurals Networks for Projecting Named Entities from English to Ewondo
Mar 29, 2020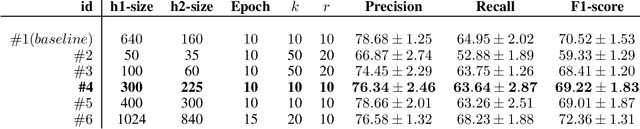
Named entity recognition is an important task in natural language processing. It is very well studied for rich language, but still under explored for low-resource languages. The main reason is that the existing techniques required a lot of annotated data to reach good performance. Recently, a new distributional representation of words has been proposed to project named entities from a rich language to a low-resource one. This representation has been coupled to a neural network in order to project named entities from English to Ewondo, a Bantu language spoken in Cameroon. Although the proposed method reached appreciable results, the size of the used neural network was too large compared to the size of the dataset. Furthermore the impact of the model parameters has not been studied. In this paper, we show experimentally that the same results can be obtained using a smaller neural network. We also emphasize the parameters that are highly correlated to the network performance. This work is a step forward to build a reliable and robust network architecture for named entity projection in low resource languages.