 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDASH: Dual-Branch Score Distillation for Guidance-Calibrated Compact Diffusion Models
May 30, 2026Parameter compression of class-conditional diffusion models reveals an underexplored limitation in output-level distillation: the unconditional score branch remains unsupervised, leaving the classifier-free guidance gap underdetermined in the student. This gap, amplified at every denoising step, admits degenerate solutions where both branches collapse toward identical predictions, rendering guidance ineffective despite low output-level training loss. This paper introduces DASH, a dual-branch distillation framework that independently supervises both score branches, uniquely specifying target branch outputs for each training sample through independent branch constraints, with an anchor term regularising conditional predictions toward ground-truth noise. The framework further introduces TIRT Transfer, which copies the teacher's converged per-timestep importance curriculum into the student as a frozen prior, eliminating the need to relearn it within limited distillation budgets. Experiments on CIFAR-10 and CIFAR-100 demonstrate that 5.9x compression maintains quality within 4 FID points of the teacher at 50-step DDIM sampling, considerably outperforming training from scratch with guidance fidelity well preserved. Ablation studies confirm that unconditional supervision is the dominant contribution, accounting for over 60% of total distillation gain. Curriculum transfer and anchor regularisation provide complementary benefit, together validating dual-branch constraints as empirically essential for guidance-preserving compression.
Multi-Level Bidirectional Decoder Interaction for Uncertainty-Aware Breast Ultrasound Analysis
Mar 01, 2026Breast ultrasound interpretation requires simultaneous lesion segmentation and tissue classification. However, conventional multi-task learning approaches suffer from task interference and rigid coordination strategies that fail to adapt to instance-specific prediction difficulty. We propose a multi-task framework addressing these limitations through multi-level decoder interaction and uncertainty-aware adaptive coordination. Task Interaction Modules operate at all decoder levels, establishing bidirectional segmentation-classification communication during spatial reconstruction through attention weighted pooling and multiplicative modulation. Unlike prior single-level or encoder-only approaches, this multi-level design captures scale specific task synergies across semantic-to-spatial scales, producing complementary task interaction streams. Uncertainty-Proxy Attention adaptively weights base versus enhanced features at each level using feature activation variance, enabling per-level and per-sample task balancing without heuristic tuning. To support instance-adaptive prediction, multi-scale context fusion captures morphological cues across varying lesion sizes. Evaluation on multiple publicly available breast ultrasound datasets demonstrates competitive performance, including 74.5% lesion IoU and 90.6% classification accuracy on BUSI dataset. Ablation studies confirm that multi-level task interaction provides significant performance gains, validating that decoder-level bidirectional communication is more effective than conventional encoder-only parameter sharing. The code is available at: https://github.com/C-loud-Nine/Uncertainty-Aware-Multi-Level-Decoder-Interaction.
A K-Means, Ward and DBSCAN repeatability study
Dec 22, 2025Reproducibility is essential in machine learning because it ensures that a model or experiment yields the same scientific conclusion. For specific algorithms repeatability with bitwise identical results is also a key for scientific integrity because it allows debugging. We decomposed several very popular clustering algorithms: K-Means, DBSCAN and Ward into their fundamental steps, and we identify the conditions required to achieve repeatability at each stage. We use an implementation example with the Python library scikit-learn to examine the repeatable aspects of each method. Our results reveal inconsistent results with K-Means when the number of OpenMP threads exceeds two. This work aims to raise awareness of this issue among both users and developers, encouraging further investigation and potential fixes.
A comparative study of emotion recognition methods using facial expressions
Dec 05, 2022
Understanding the facial expressions of our interlocutor is important to enrich the communication and to give it a depth that goes beyond the explicitly expressed. In fact, studying one's facial expression gives insight into their hidden emotion state. However, even as humans, and despite our empathy and familiarity with the human emotional experience, we are only able to guess what the other might be feeling. In the fields of artificial intelligence and computer vision, Facial Emotion Recognition (FER) is a topic that is still in full growth mostly with the advancement of deep learning approaches and the improvement of data collection. The main purpose of this paper is to compare the performance of three state-of-the-art networks, each having their own approach to improve on FER tasks, on three FER datasets. The first and second sections respectively describe the three datasets and the three studied network architectures designed for an FER task. The experimental protocol, the results and their interpretation are outlined in the remaining sections.
Explainable classification of astronomical uncertain time series
Sep 28, 2022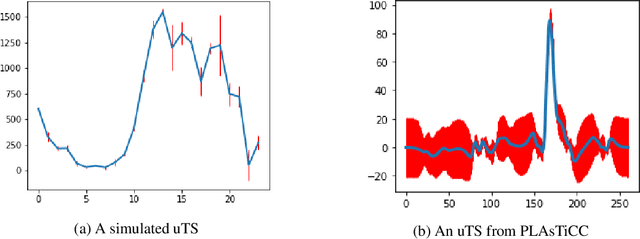
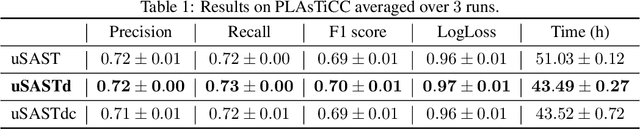
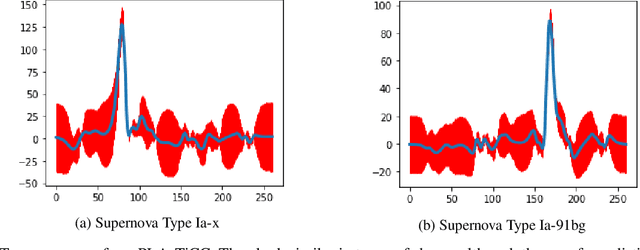
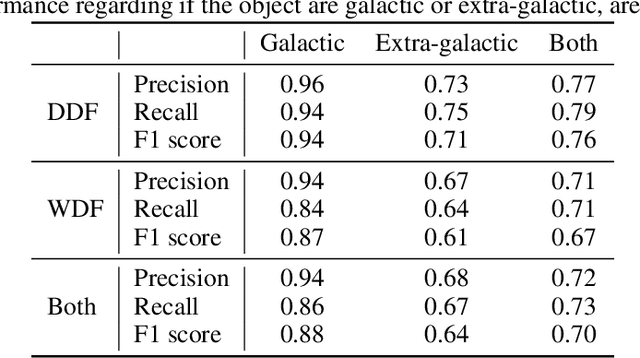
Exploring the expansion history of the universe, understanding its evolutionary stages, and predicting its future evolution are important goals in astrophysics. Today, machine learning tools are used to help achieving these goals by analyzing transient sources, which are modeled as uncertain time series. Although black-box methods achieve appreciable performance, existing interpretable time series methods failed to obtain acceptable performance for this type of data. Furthermore, data uncertainty is rarely taken into account in these methods. In this work, we propose an uncertaintyaware subsequence based model which achieves a classification comparable to that of state-of-the-art methods. Unlike conformal learning which estimates model uncertainty on predictions, our method takes data uncertainty as additional input. Moreover, our approach is explainable-by-design, giving domain experts the ability to inspect the model and explain its predictions. The explainability of the proposed method has also the potential to inspire new developments in theoretical astrophysics modeling by suggesting important subsequences which depict details of light curve shapes. The dataset, the source code of our experiment, and the results are made available on a public repository.
Expert Opinion Elicitation for Assisting Deep Learning based Lyme Disease Classifier with Patient Data
Aug 30, 2022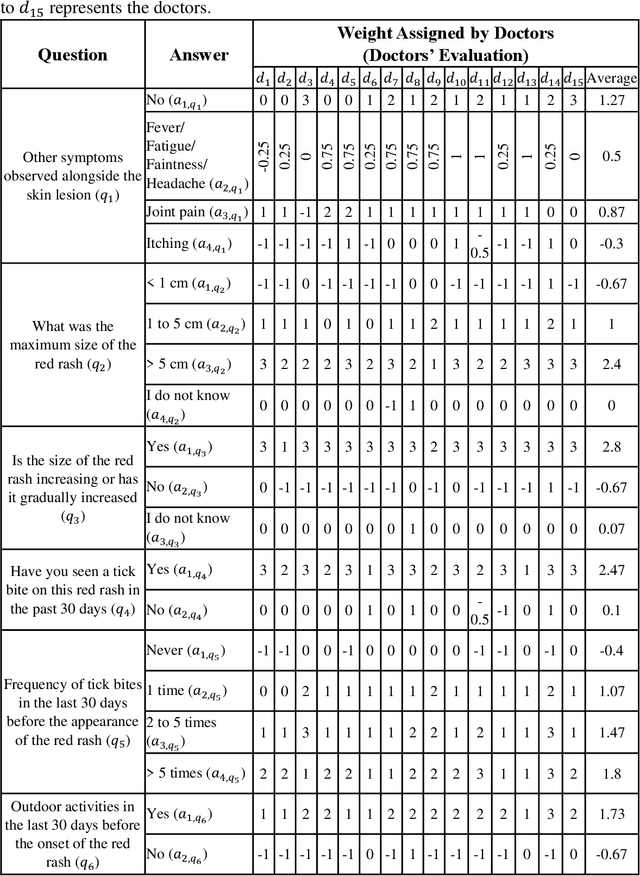
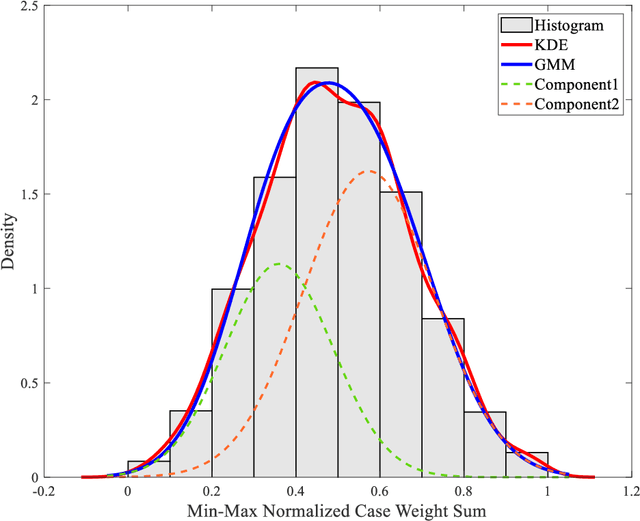
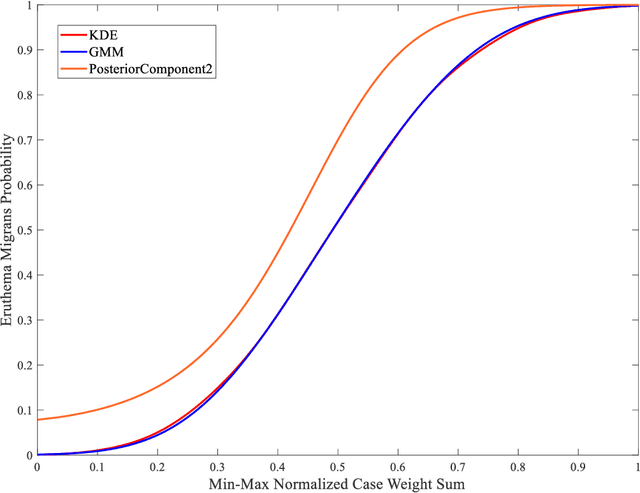
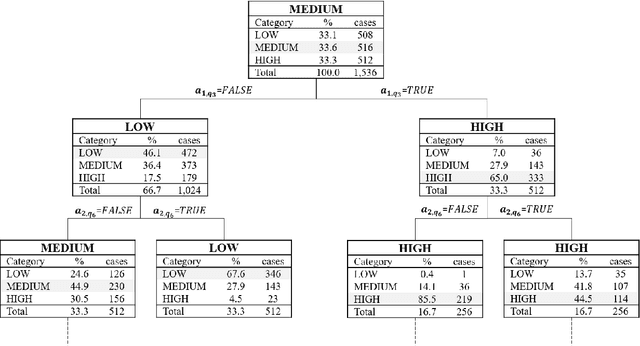
Diagnosing erythema migrans (EM) skin lesion, the most common early symptom of Lyme disease using deep learning techniques can be effective to prevent long-term complications. Existing works on deep learning based EM recognition only utilizes lesion image due to the lack of a dataset of Lyme disease related images with associated patient data. Physicians rely on patient information about the background of the skin lesion to confirm their diagnosis. In order to assist the deep learning model with a probability score calculated from patient data, this study elicited opinion from fifteen doctors. For the elicitation process, a questionnaire with questions and possible answers related to EM was prepared. Doctors provided relative weights to different answers to the questions. We converted doctors evaluations to probability scores using Gaussian mixture based density estimation. For elicited probability model validation, we exploited formal concept analysis and decision tree. The elicited probability scores can be utilized to make image based deep learning Lyme disease pre-scanners robust.
Uncertain Time Series Classification With Shapelet Transform
Feb 03, 2021
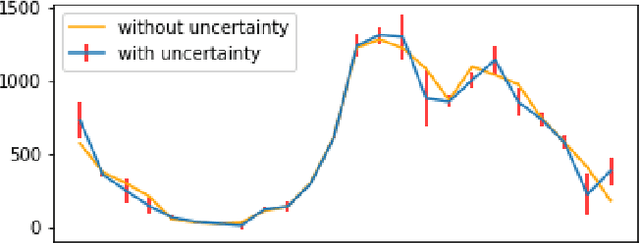
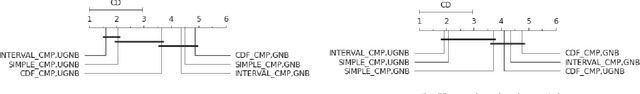

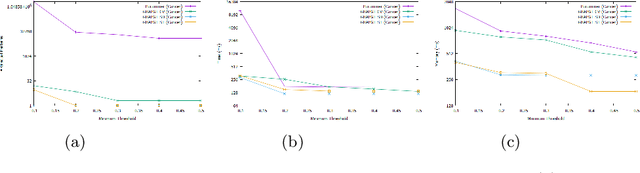
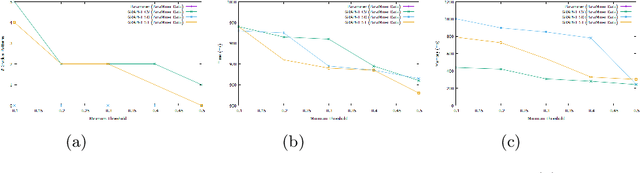
Time series classification is a task that aims at classifying chronological data. It is used in a diverse range of domains such as meteorology, medicine and physics. In the last decade, many algorithms have been built to perform this task with very appreciable accuracy. However, applications where time series have uncertainty has been under-explored. Using uncertainty propagation techniques, we propose a new uncertain dissimilarity measure based on Euclidean distance. We then propose the uncertain shapelet transform algorithm for the classification of uncertain time series. The large experiments we conducted on state of the art datasets show the effectiveness of our contribution. The source code of our contribution and the datasets we used are all available on a public repository.
Discovering Frequent Gradual Itemsets with Imprecise Data
May 22, 2020

The gradual patterns that model the complex co-variations of attributes of the form "The more/less X, The more/less Y" play a crucial role in many real world applications where the amount of numerical data to manage is important, this is the biological data. Recently, these types of patterns have caught the attention of the data mining community, where several methods have been defined to automatically extract and manage these patterns from different data models. However, these methods are often faced the problem of managing the quantity of mined patterns, and in many practical applications, the calculation of all these patterns can prove to be intractable for the user-defined frequency threshold and the lack of focus leads to generating huge collections of patterns. Moreover another problem with the traditional approaches is that the concept of gradualness is defined just as an increase or a decrease. Indeed, a gradualness is considered as soon as the values of the attribute on both objects are different. As a result, numerous quantities of patterns extracted by traditional algorithms can be presented to the user although their gradualness is only a noise effect in the data. To address this issue, this paper suggests to introduce the gradualness thresholds from which to consider an increase or a decrease. In contrast to literature approaches, the proposed approach takes into account the distribution of attribute values, as well as the user's preferences on the gradualness threshold and makes it possible to extract gradual patterns on certain databases where literature approaches fail due to too large search space. Moreover, results from an experimental evaluation on real databases show that the proposed algorithm is scalable, efficient, and can eliminate numerous patterns that do not verify specific gradualness requirements to show a small set of patterns to the user.
Classification des S{é}ries Temporelles Incertaines par Transformation Shapelet
Dec 11, 2019

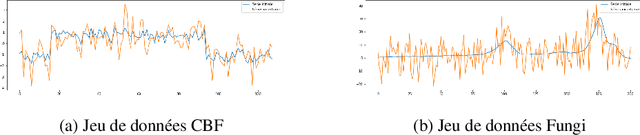
Time serie classification is used in a diverse range of domain such as meteorology, medicine and physics. It aims to classify chronological data. Many accurate approaches have been built during the last decade and shapelet transformation is one of them. However, none of these approaches does take data uncertainty into account. Using uncertainty propagation techiniques, we propose a new dissimilarity measure based on euclidean distance. We also show how to use this new measure to adapt shapelet transformation to uncertain time series classification. An experimental assessment of our contribution is done on some state of the art datasets.
Extracting Frequent Gradual Patterns Using Constraints Modeling
Mar 20, 2019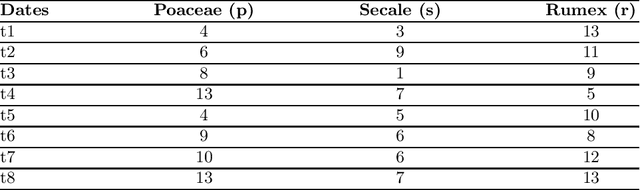
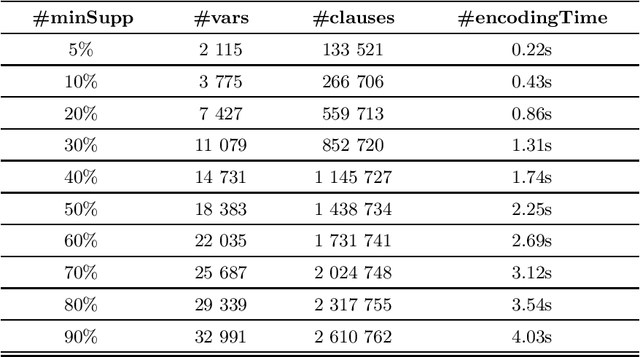
In this paper, we propose a constraint-based modeling approach for the problem of discovering frequent gradual patterns in a numerical dataset. This SAT-based declarative approach offers an additional possibility to benefit from the recent progress in satisfiability testing and to exploit the efficiency of modern SAT solvers for enumerating all frequent gradual patterns in a numerical dataset. Our approach can easily be extended with extra constraints, such as temporal constraints in order to extract more specific patterns in a broad range of gradual patterns mining applications. We show the practical feasibility of our SAT model by running experiments on two real world datasets.