 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShaping Up SHAP: Enhancing Stability through Layer-Wise Neighbor Selection
Dec 19, 2023

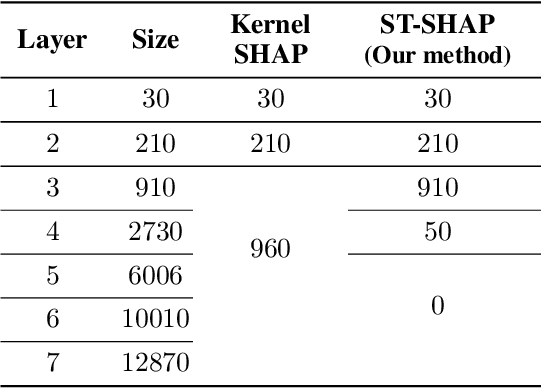

Machine learning techniques, such as deep learning and ensemble methods, are widely used in various domains due to their ability to handle complex real-world tasks. However, their black-box nature has raised multiple concerns about the fairness, trustworthiness, and transparency of computer-assisted decision-making. This has led to the emergence of local post-hoc explainability methods, which offer explanations for individual decisions made by black-box algorithms. Among these methods, Kernel SHAP is widely used due to its model-agnostic nature and its well-founded theoretical framework. Despite these strengths, Kernel SHAP suffers from high instability: different executions of the method with the same inputs can lead to significantly different explanations, which diminishes the utility of post-hoc explainability. The contribution of this paper is two-fold. On the one hand, we show that Kernel SHAP's instability is caused by its stochastic neighbor selection procedure, which we adapt to achieve full stability without compromising explanation fidelity. On the other hand, we show that by restricting the neighbors generation to perturbations of size 1 -- which we call the coalitions of Layer 1 -- we obtain a novel feature-attribution method that is fully stable, efficient to compute, and still meaningful.
LCE: An Augmented Combination of Bagging and Boosting in Python
Aug 15, 2023
lcensemble is a high-performing, scalable and user-friendly Python package for the general tasks of classification and regression. The package implements Local Cascade Ensemble (LCE), a machine learning method that further enhances the prediction performance of the current state-of-the-art methods Random Forest and XGBoost. LCE combines their strengths and adopts a complementary diversification approach to obtain a better generalizing predictor. The package is compatible with scikit-learn, therefore it can interact with scikit-learn pipelines and model selection tools. It is distributed under the Apache 2.0 license, and its source code is available at https://github.com/LocalCascadeEnsemble/LCE.
Generating robust counterfactual explanations
Apr 24, 2023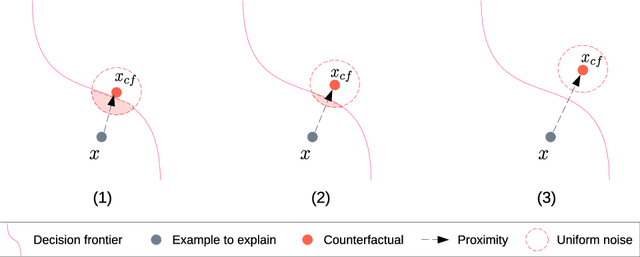



Counterfactual explanations have become a mainstay of the XAI field. This particularly intuitive statement allows the user to understand what small but necessary changes would have to be made to a given situation in order to change a model prediction. The quality of a counterfactual depends on several criteria: realism, actionability, validity, robustness, etc. In this paper, we are interested in the notion of robustness of a counterfactual. More precisely, we focus on robustness to counterfactual input changes. This form of robustness is particularly challenging as it involves a trade-off between the robustness of the counterfactual and the proximity with the example to explain. We propose a new framework, CROCO, that generates robust counterfactuals while managing effectively this trade-off, and guarantees the user a minimal robustness. An empirical evaluation on tabular datasets confirms the relevance and effectiveness of our approach.
Persistence-Based Discretization for Learning Discrete Event Systems from Time Series
Jan 12, 2023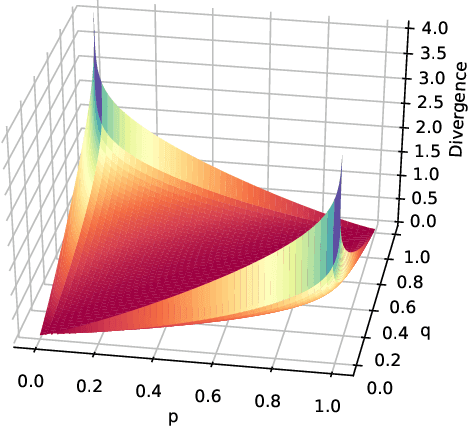
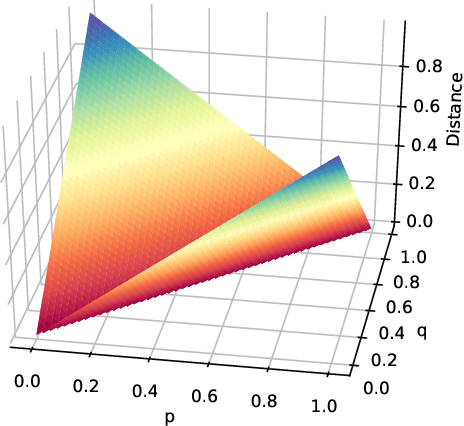
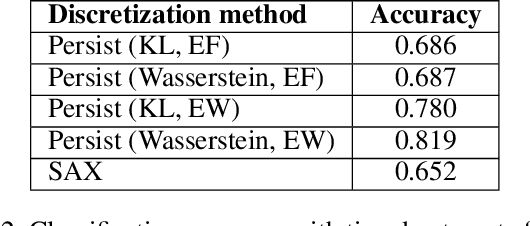
To get a good understanding of a dynamical system, it is convenient to have an interpretable and versatile model of it. Timed discrete event systems are a kind of model that respond to these requirements. However, such models can be inferred from timestamped event sequences but not directly from numerical data. To solve this problem, a discretization step must be done to identify events or symbols in the time series. Persist is a discretization method that intends to create persisting symbols by using a score called persistence score. This allows to mitigate the risk of undesirable symbol changes that would lead to a too complex model. After the study of the persistence score, we point out that it tends to favor excessive cases making it miss interesting persisting symbols. To correct this behavior, we replace the metric used in the persistence score, the Kullback-Leibler divergence, with the Wasserstein distance. Experiments show that the improved persistence score enhances Persist's ability to capture the information of the original time series and that it makes it better suited for discrete event systems learning.
VCNet: A self-explaining model for realistic counterfactual generation
Dec 21, 2022



Counterfactual explanation is a common class of methods to make local explanations of machine learning decisions. For a given instance, these methods aim to find the smallest modification of feature values that changes the predicted decision made by a machine learning model. One of the challenges of counterfactual explanation is the efficient generation of realistic counterfactuals. To address this challenge, we propose VCNet-Variational Counter Net-a model architecture that combines a predictor and a counterfactual generator that are jointly trained, for regression or classification tasks. VCNet is able to both generate predictions, and to generate counterfactual explanations without having to solve another minimisation problem. Our contribution is the generation of counterfactuals that are close to the distribution of the predicted class. This is done by learning a variational autoencoder conditionally to the output of the predictor in a join-training fashion. We present an empirical evaluation on tabular datasets and across several interpretability metrics. The results are competitive with the state-of-the-art method.
Discovering Useful Compact Sets of Sequential Rules in a Long Sequence
Sep 15, 2021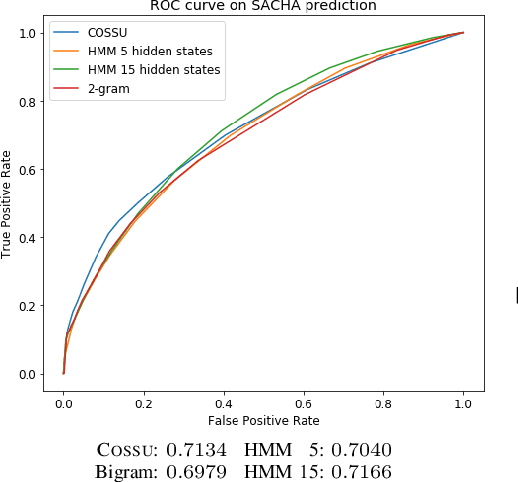


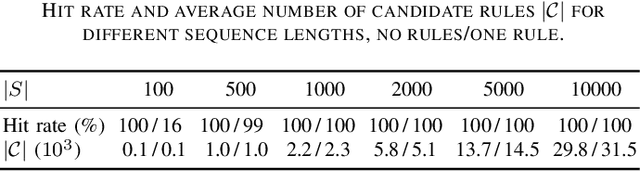
We are interested in understanding the underlying generation process for long sequences of symbolic events. To do so, we propose COSSU, an algorithm to mine small and meaningful sets of sequential rules. The rules are selected using an MDL-inspired criterion that favors compactness and relies on a novel rule-based encoding scheme for sequences. Our evaluation shows that COSSU can successfully retrieve relevant sets of closed sequential rules from a long sequence. Such rules constitute an interpretable model that exhibits competitive accuracy for the tasks of next-element prediction and classification.
HiPaR: Hierarchical Pattern-aided Regression
Feb 24, 2021


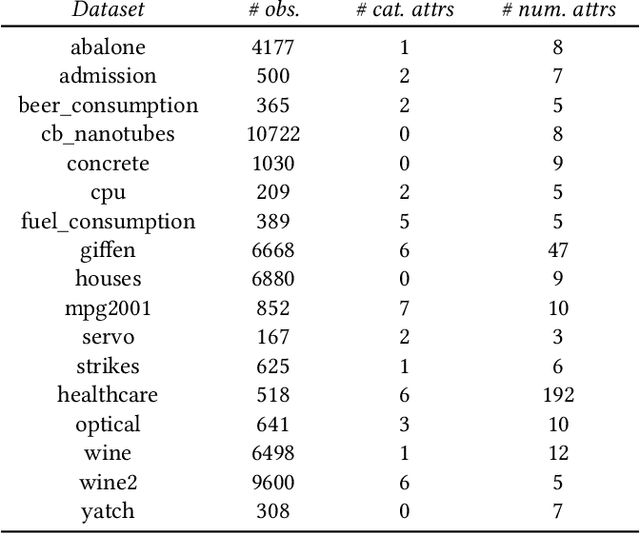
We introduce HiPaR, a novel pattern-aided regression method for tabular data containing both categorical and numerical attributes. HiPaR mines hybrid rules of the form $p \Rightarrow y = f(X)$ where $p$ is the characterization of a data region and $f(X)$ is a linear regression model on a variable of interest $y$. HiPaR relies on pattern mining techniques to identify regions of the data where the target variable can be accurately explained via local linear models. The novelty of the method lies in the combination of an enumerative approach to explore the space of regions and efficient heuristics that guide the search. Such a strategy provides more flexibility when selecting a small set of jointly accurate and human-readable hybrid rules that explain the entire dataset. As our experiments shows, HiPaR mines fewer rules than existing pattern-based regression methods while still attaining state-of-the-art prediction performance.
XCM: An Explainable Convolutional Neural Network for Multivariate Time Series Classification
Sep 10, 2020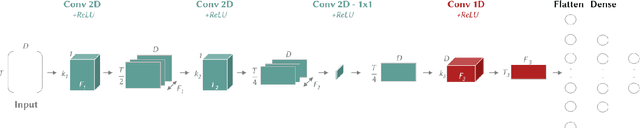
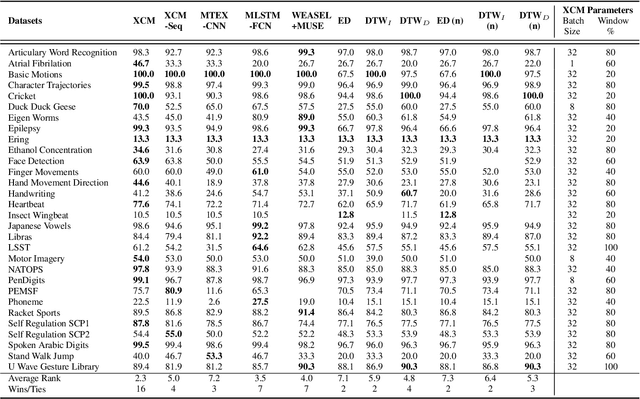
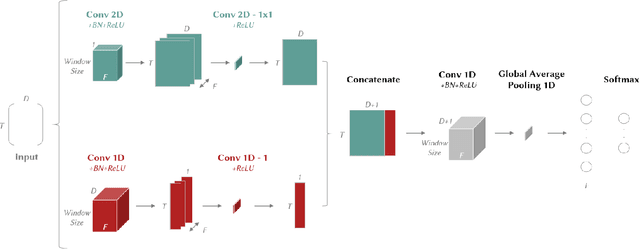

We present XCM, an eXplainable Convolutional neural network for Multivariate time series classification. XCM is a new compact convolutional neural network which extracts, in parallel, information relative to the observed variables and time from the input data. Thus, XCM architecture enables faithful explainability based on a post-hoc model-specific method (Gradient-weighted Class Activation Mapping), which identifies the observed variables and timestamps of the input data that are important for predictions. Our evaluation firstly shows that XCM outperforms the state-of-the-art multivariate time series classifiers on both the large and small public UEA datasets. Furthermore, following the illustration of the performance and explainability of XCM on a synthetic dataset, we present how XCM can outperform the current most accurate state-of-the-art algorithm on a real-world application while enhancing explainability by providing faithful and more informative explanations.
Local Cascade Ensemble for Multivariate Data Classification
May 07, 2020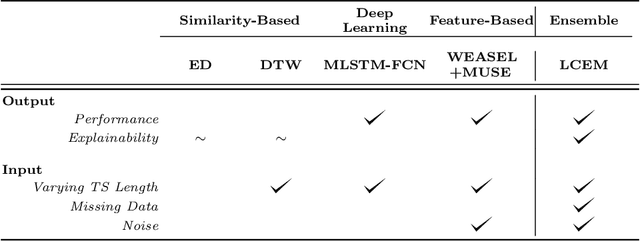
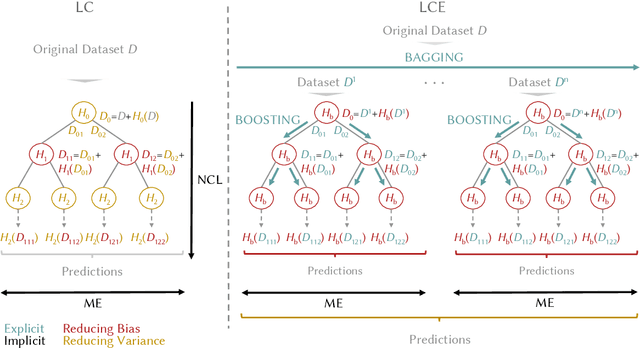
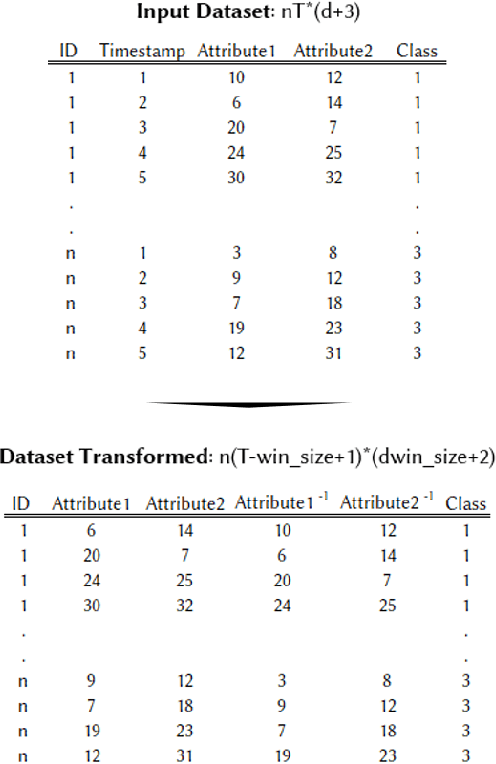
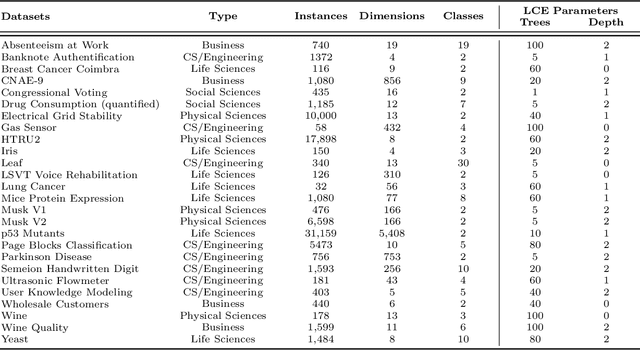
We present LCE, a Local Cascade Ensemble for traditional (tabular) multivariate data classification, and its extension LCEM for Multivariate Time Series (MTS) classification. LCE is a new hybrid ensemble method that combines an explicit boosting-bagging approach to handle the usual bias-variance tradeoff faced by machine learning models and an implicit divide-and-conquer approach to individualize classifier errors on different parts of the training data. Our evaluation firstly shows that the hybrid ensemble method LCE outperforms the state-of-the-art classifiers on the UCI datasets and that LCEM outperforms the state-of-the-art MTS classifiers on the UEA datasets. Furthermore, LCEM provides explainability by design and manifests robust performance when faced with challenges arising from continuous data collection (different MTS length, missing data and noise).
Statistically Significant Discriminative Patterns Searching
Jun 02, 2019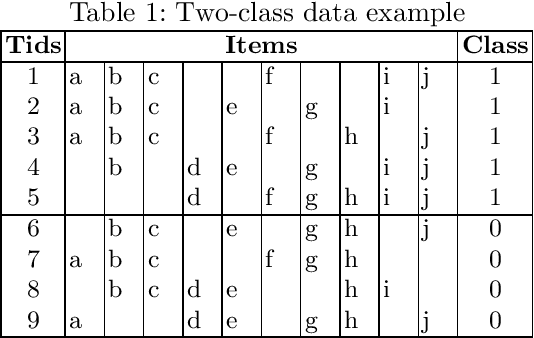


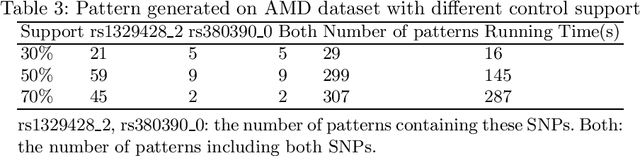
Discriminative pattern mining is an essential task of data mining. This task aims to discover patterns which occur more frequently in a class than other classes in a class-labeled dataset. This type of patterns is valuable in various domains such as bioinformatics, data classification. In this paper, we propose a novel algorithm, named SSDPS, to discover patterns in two-class datasets. The SSDPS algorithm owes its efficiency to an original enumeration strategy of the patterns, which allows to exploit some degrees of anti-monotonicity on the measures of discriminance and statistical significance. Experimental results demonstrate that the performance of the SSDPS algorithm is better than others. In addition, the number of generated patterns is much less than the number of other algorithms. Experiment on real data also shows that SSDPS efficiently detects multiple SNPs combinations in genetic data.