 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeREFINE-LM: Mitigating Language Model Stereotypes via Reinforcement Learning
Aug 18, 2024



With the introduction of (large) language models, there has been significant concern about the unintended bias such models may inherit from their training data. A number of studies have shown that such models propagate gender stereotypes, as well as geographical and racial bias, among other biases. While existing works tackle this issue by preprocessing data and debiasing embeddings, the proposed methods require a lot of computational resources and annotation effort while being limited to certain types of biases. To address these issues, we introduce REFINE-LM, a debiasing method that uses reinforcement learning to handle different types of biases without any fine-tuning. By training a simple model on top of the word probability distribution of a LM, our bias agnostic reinforcement learning method enables model debiasing without human annotations or significant computational resources. Experiments conducted on a wide range of models, including several LMs, show that our method (i) significantly reduces stereotypical biases while preserving LMs performance; (ii) is applicable to different types of biases, generalizing across contexts such as gender, ethnicity, religion, and nationality-based biases; and (iii) it is not expensive to train.
Does It Make Sense to Explain a Black Box With Another Black Box?
Apr 23, 2024



Although counterfactual explanations are a popular approach to explain ML black-box classifiers, they are less widespread in NLP. Most methods find those explanations by iteratively perturbing the target document until it is classified differently by the black box. We identify two main families of counterfactual explanation methods in the literature, namely, (a) \emph{transparent} methods that perturb the target by adding, removing, or replacing words, and (b) \emph{opaque} approaches that project the target document into a latent, non-interpretable space where the perturbation is carried out subsequently. This article offers a comparative study of the performance of these two families of methods on three classical NLP tasks. Our empirical evidence shows that opaque approaches can be an overkill for downstream applications such as fake news detection or sentiment analysis since they add an additional level of complexity with no significant performance gain. These observations motivate our discussion, which raises the question of whether it makes sense to explain a black box using another black box.
Shaping Up SHAP: Enhancing Stability through Layer-Wise Neighbor Selection
Dec 19, 2023

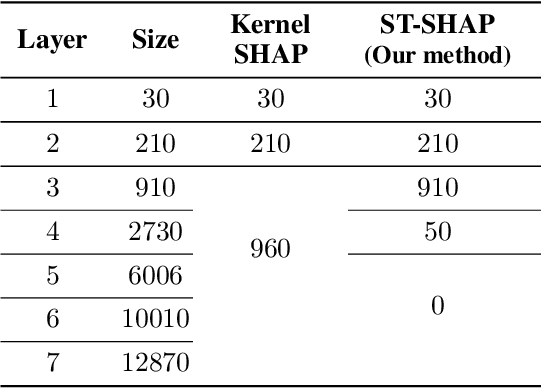

Machine learning techniques, such as deep learning and ensemble methods, are widely used in various domains due to their ability to handle complex real-world tasks. However, their black-box nature has raised multiple concerns about the fairness, trustworthiness, and transparency of computer-assisted decision-making. This has led to the emergence of local post-hoc explainability methods, which offer explanations for individual decisions made by black-box algorithms. Among these methods, Kernel SHAP is widely used due to its model-agnostic nature and its well-founded theoretical framework. Despite these strengths, Kernel SHAP suffers from high instability: different executions of the method with the same inputs can lead to significantly different explanations, which diminishes the utility of post-hoc explainability. The contribution of this paper is two-fold. On the one hand, we show that Kernel SHAP's instability is caused by its stochastic neighbor selection procedure, which we adapt to achieve full stability without compromising explanation fidelity. On the other hand, we show that by restricting the neighbors generation to perturbations of size 1 -- which we call the coalitions of Layer 1 -- we obtain a novel feature-attribution method that is fully stable, efficient to compute, and still meaningful.
Effects of Locality and Rule Language on Explanations for Knowledge Graph Embeddings
Feb 14, 2023

Knowledge graphs (KGs) are key tools in many AI-related tasks such as reasoning or question answering. This has, in turn, propelled research in link prediction in KGs, the task of predicting missing relationships from the available knowledge. Solutions based on KG embeddings have shown promising results in this matter. On the downside, these approaches are usually unable to explain their predictions. While some works have proposed to compute post-hoc rule explanations for embedding-based link predictors, these efforts have mostly resorted to rules with unbounded atoms, e.g., bornIn(x,y) => residence(x,y), learned on a global scope, i.e., the entire KG. None of these works has considered the impact of rules with bounded atoms such as nationality(x,England) => speaks(x, English), or the impact of learning from regions of the KG, i.e., local scopes. We therefore study the effects of these factors on the quality of rule-based explanations for embedding-based link predictors. Our results suggest that more specific rules and local scopes can improve the accuracy of the explanations. Moreover, these rules can provide further insights about the inner-workings of KG embeddings for link prediction.
s-LIME: Reconciling Locality and Fidelity in Linear Explanations
Aug 02, 2022The benefit of locality is one of the major premises of LIME, one of the most prominent methods to explain black-box machine learning models. This emphasis relies on the postulate that the more locally we look at the vicinity of an instance, the simpler the black-box model becomes, and the more accurately we can mimic it with a linear surrogate. As logical as this seems, our findings suggest that, with the current design of LIME, the surrogate model may degenerate when the explanation is too local, namely, when the bandwidth parameter $\sigma$ tends to zero. Based on this observation, the contribution of this paper is twofold. Firstly, we study the impact of both the bandwidth and the training vicinity on the fidelity and semantics of LIME explanations. Secondly, and based on our findings, we propose \slime, an extension of LIME that reconciles fidelity and locality.
Discovering Useful Compact Sets of Sequential Rules in a Long Sequence
Sep 15, 2021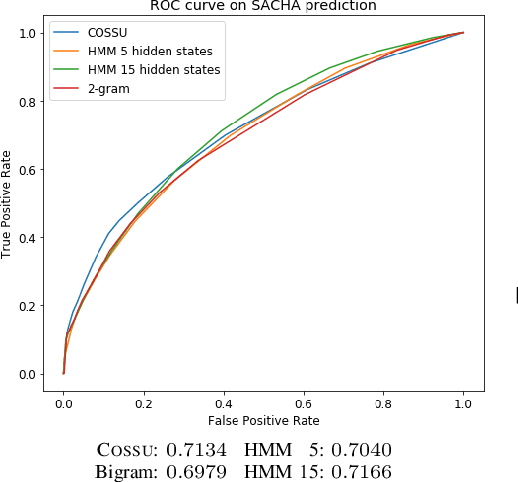


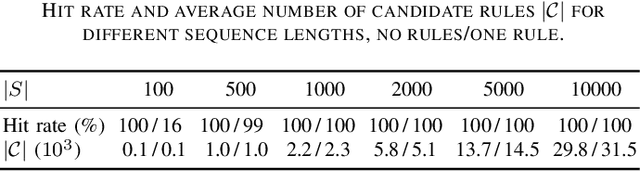
We are interested in understanding the underlying generation process for long sequences of symbolic events. To do so, we propose COSSU, an algorithm to mine small and meaningful sets of sequential rules. The rules are selected using an MDL-inspired criterion that favors compactness and relies on a novel rule-based encoding scheme for sequences. Our evaluation shows that COSSU can successfully retrieve relevant sets of closed sequential rules from a long sequence. Such rules constitute an interpretable model that exhibits competitive accuracy for the tasks of next-element prediction and classification.
HiPaR: Hierarchical Pattern-aided Regression
Feb 24, 2021


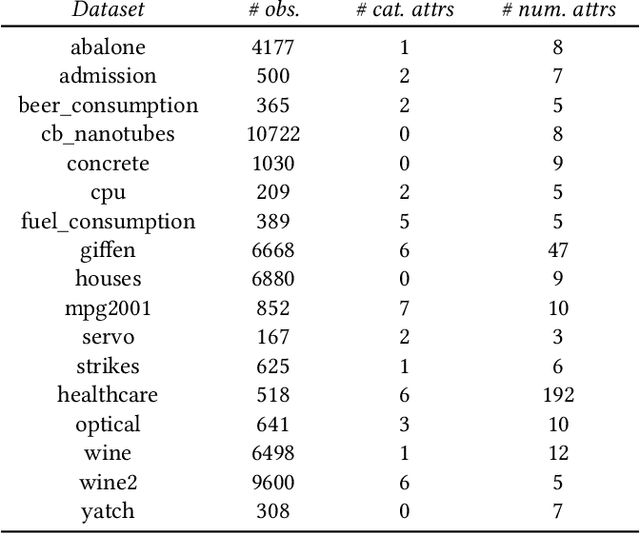
We introduce HiPaR, a novel pattern-aided regression method for tabular data containing both categorical and numerical attributes. HiPaR mines hybrid rules of the form $p \Rightarrow y = f(X)$ where $p$ is the characterization of a data region and $f(X)$ is a linear regression model on a variable of interest $y$. HiPaR relies on pattern mining techniques to identify regions of the data where the target variable can be accurately explained via local linear models. The novelty of the method lies in the combination of an enumerative approach to explore the space of regions and efficient heuristics that guide the search. Such a strategy provides more flexibility when selecting a small set of jointly accurate and human-readable hybrid rules that explain the entire dataset. As our experiments shows, HiPaR mines fewer rules than existing pattern-based regression methods while still attaining state-of-the-art prediction performance.
REMI: Mining Intuitive Referring Expressions on Knowledge Bases
Nov 04, 2019



A referring expression (RE) is a description that identifies a set of instances unambiguously. Mining REs from data finds applications in natural language generation, algorithmic journalism, and data maintenance. Since there may exist multiple REs for a given set of entities, it is common to focus on the most intuitive ones, i.e., the most concise and informative. In this paper we present REMI, a system that can mine intuitive REs on large RDF knowledge bases. Our experimental evaluation shows that REMI finds REs deemed intuitive by users. Moreover we show that REMI is several orders of magnitude faster than an approach based on inductive logic programming.