 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTo Be or Not To Be a Verbal Multiword Expression: A Quest for Discriminating Features
Jul 22, 2020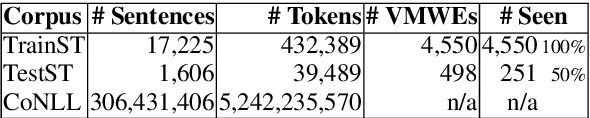
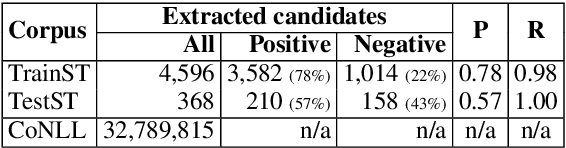
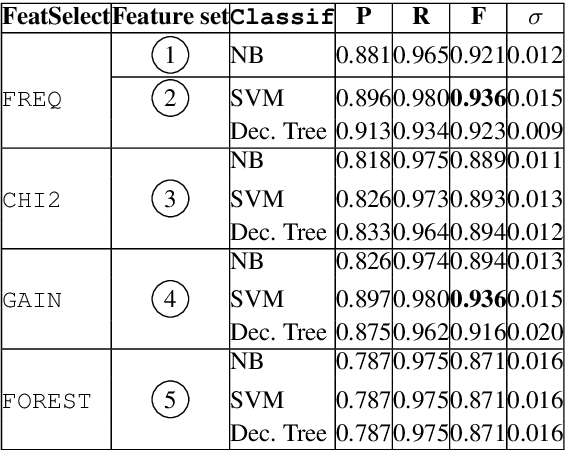

Automatic identification of mutiword expressions (MWEs) is a pre-requisite for semantically-oriented downstream applications. This task is challenging because MWEs, especially verbal ones (VMWEs), exhibit surface variability. However, this variability is usually more restricted than in regular (non-VMWE) constructions, which leads to various variability profiles. We use this fact to determine the optimal set of features which could be used in a supervised classification setting to solve a subproblem of VMWE identification: the identification of occurrences of previously seen VMWEs. Surprisingly, a simple custom frequency-based feature selection method proves more efficient than other standard methods such as Chi-squared test, information gain or decision trees. An SVM classifier using the optimal set of only 6 features outperforms the best systems from a recent shared task on the French seen data.