 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSurprisal and Metaphor Novelty: Moderate Correlations and Divergent Scaling Effects
Jan 08, 2026Novel metaphor comprehension involves complex semantic processes and linguistic creativity, making it an interesting task for studying language models (LMs). This study investigates whether surprisal, a probabilistic measure of predictability in LMs, correlates with different metaphor novelty datasets. We analyse surprisal from 16 LM variants on corpus-based and synthetic metaphor novelty datasets. We explore a cloze-style surprisal method that conditions on full-sentence context. Results show that LMs yield significant moderate correlations with scores/labels of metaphor novelty. We further identify divergent scaling patterns: on corpus-based data, correlation strength decreases with model size (inverse scaling effect), whereas on synthetic data it increases (Quality-Power Hypothesis). We conclude that while surprisal can partially account for annotations of metaphor novelty, it remains a limited metric of linguistic creativity.
Dialogue Is Not Enough to Make a Communicative BabyLM (But Neither Is Developmentally Inspired Reinforcement Learning)
Oct 23, 2025We investigate whether pre-training exclusively on dialogue data results in formally and functionally apt small language models. Based on this pre-trained llamalogue model, we employ a variety of fine-tuning strategies to enforce "more communicative" text generations by our models. Although our models underperform on most standard BabyLM benchmarks, they excel at dialogue continuation prediction in a minimal pair setting. While PPO fine-tuning has mixed to adversarial effects on our models, DPO fine-tuning further improves their performance on our custom dialogue benchmark.
Linguistic Structure Induction from Language Models
Mar 11, 2024Linear sequences of words are implicitly represented in our brains by hierarchical structures that organize the composition of words in sentences. Linguists formalize different frameworks to model this hierarchy; two of the most common syntactic frameworks are Constituency and Dependency. Constituency represents sentences as nested groups of phrases, while dependency represents a sentence by assigning relations between its words. Recently, the pursuit of intelligent machines has produced Language Models (LMs) capable of solving many language tasks with a human-level performance. Many studies now question whether LMs implicitly represent syntactic hierarchies. This thesis focuses on producing constituency and dependency structures from LMs in an unsupervised setting. I review the critical methods in this field and highlight a line of work that utilizes a numerical representation for binary constituency trees (Syntactic Distance). I present a detailed study on StructFormer (SF) (Shen et al., 2021), which retrofits a transformer encoder architecture with a parser network to produce constituency and dependency structures. I present six experiments to analyze and address this field's challenges; experiments include investigating the effect of repositioning the parser network within the SF architecture, evaluating subword-based induced trees, and benchmarking the models developed in the thesis experiments on linguistic tasks. Models benchmarking is performed by participating in the BabyLM challenge, published at CoNLL 2023 (Momen et al., 2023). The results of this thesis encourage further development in the direction of retrofitting transformer-based models to induce syntactic structures, supported by the acceptable performance of SF in different experimental settings and the observed limitations that require innovative solutions to advance the state of syntactic structure induction.
Increasing The Performance of Cognitively Inspired Data-Efficient Language Models via Implicit Structure Building
Oct 31, 2023
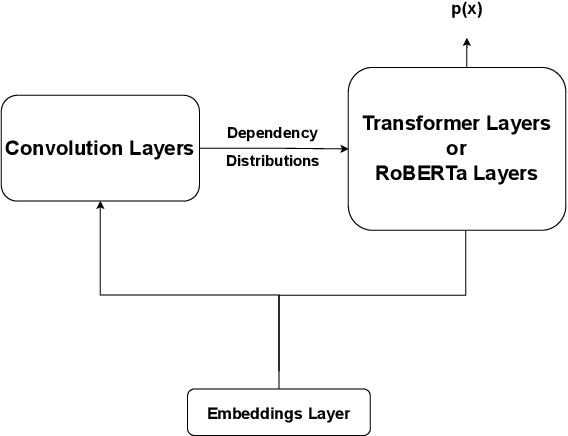
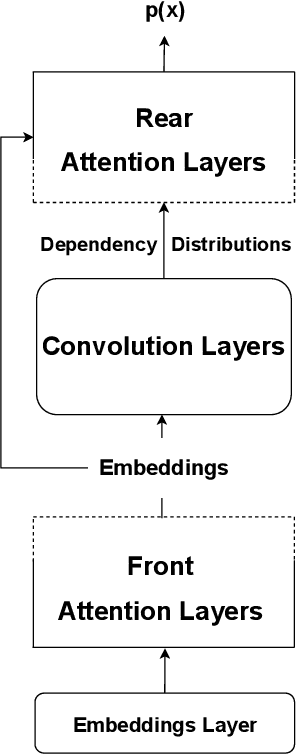

In this paper, we describe our submission to the BabyLM Challenge 2023 shared task on data-efficient language model (LM) pretraining (Warstadt et al., 2023). We train transformer-based masked language models that incorporate unsupervised predictions about hierarchical sentence structure into the model architecture. Concretely, we use the Structformer architecture (Shen et al., 2021) and variants thereof. StructFormer models have been shown to perform well on unsupervised syntactic induction based on limited pretraining data, and to yield performance improvements over a vanilla transformer architecture (Shen et al., 2021). Evaluation of our models on 39 tasks provided by the BabyLM challenge shows promising improvements of models that integrate a hierarchical bias into the architecture at some particular tasks, even though they fail to consistently outperform the RoBERTa baseline model provided by the shared task organizers on all tasks.
DEPLAIN: A German Parallel Corpus with Intralingual Translations into Plain Language for Sentence and Document Simplification
May 30, 2023



Text simplification is an intralingual translation task in which documents, or sentences of a complex source text are simplified for a target audience. The success of automatic text simplification systems is highly dependent on the quality of parallel data used for training and evaluation. To advance sentence simplification and document simplification in German, this paper presents DEplain, a new dataset of parallel, professionally written and manually aligned simplifications in plain German ("plain DE" or in German: "Einfache Sprache"). DEplain consists of a news domain (approx. 500 document pairs, approx. 13k sentence pairs) and a web-domain corpus (approx. 150 aligned documents, approx. 2k aligned sentence pairs). In addition, we are building a web harvester and experimenting with automatic alignment methods to facilitate the integration of non-aligned and to be published parallel documents. Using this approach, we are dynamically increasing the web domain corpus, so it is currently extended to approx. 750 document pairs and approx. 3.5k aligned sentence pairs. We show that using DEplain to train a transformer-based seq2seq text simplification model can achieve promising results. We make available the corpus, the adapted alignment methods for German, the web harvester and the trained models here: https://github.com/rstodden/DEPlain.