 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeeing Syntax: Uncovering Syntactic Learning Limitations in Vision-Language Models
Paper and Code



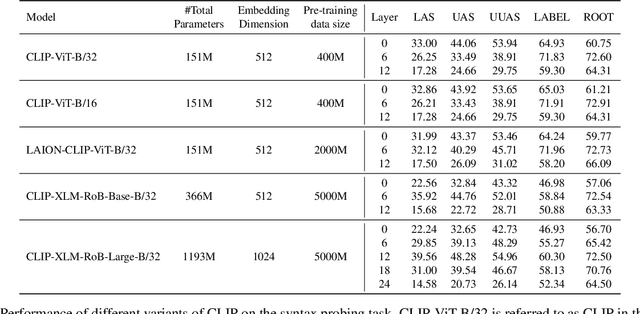
Vision-language models (VLMs), serve as foundation models for multi-modal applications such as image captioning and text-to-image generation. Recent studies have highlighted limitations in VLM text encoders, particularly in areas like compositionality and semantic understanding, though the underlying reasons for these limitations remain unclear. In this work, we aim to address this gap by analyzing the syntactic information, one of the fundamental linguistic properties, encoded by the text encoders of VLMs. We perform a thorough analysis comparing VLMs with different objective functions, parameter size and training data size, and with uni-modal language models (ULMs) in their ability to encode syntactic knowledge. Our findings suggest that ULM text encoders acquire syntactic information more effectively than those in VLMs. The syntactic information learned by VLM text encoders is shaped primarily by the pre-training objective, which plays a more crucial role than other factors such as model architecture, model size, or the volume of pre-training data. Models exhibit different layer-wise trends where CLIP performance dropped across layers while for other models, middle layers are rich in encoding syntactic knowledge.