 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvestigating the Robustness of Deductive Reasoning with Large Language Models
Feb 04, 2025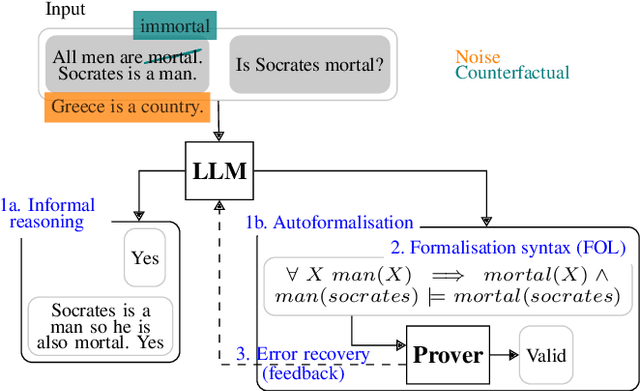
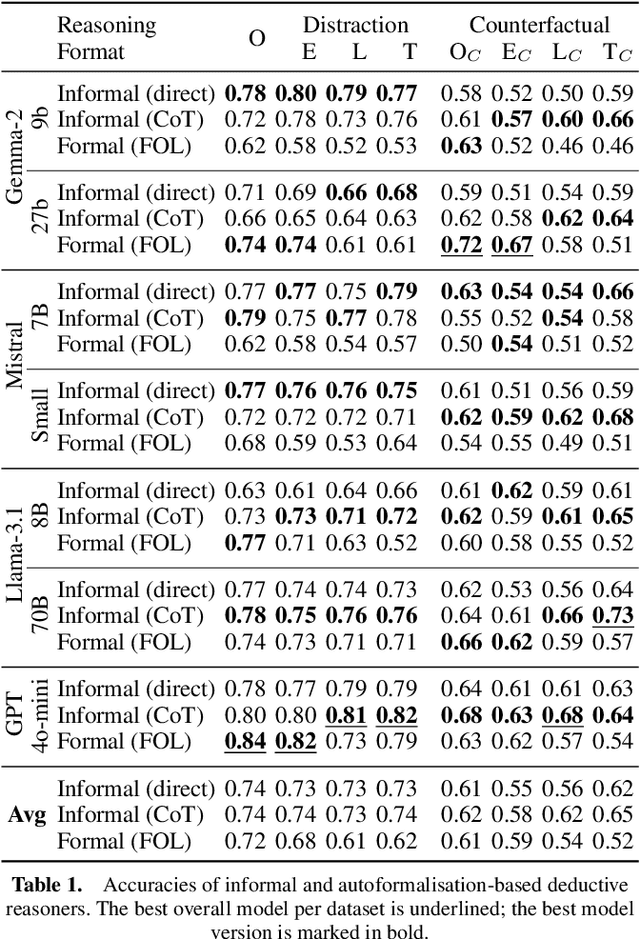

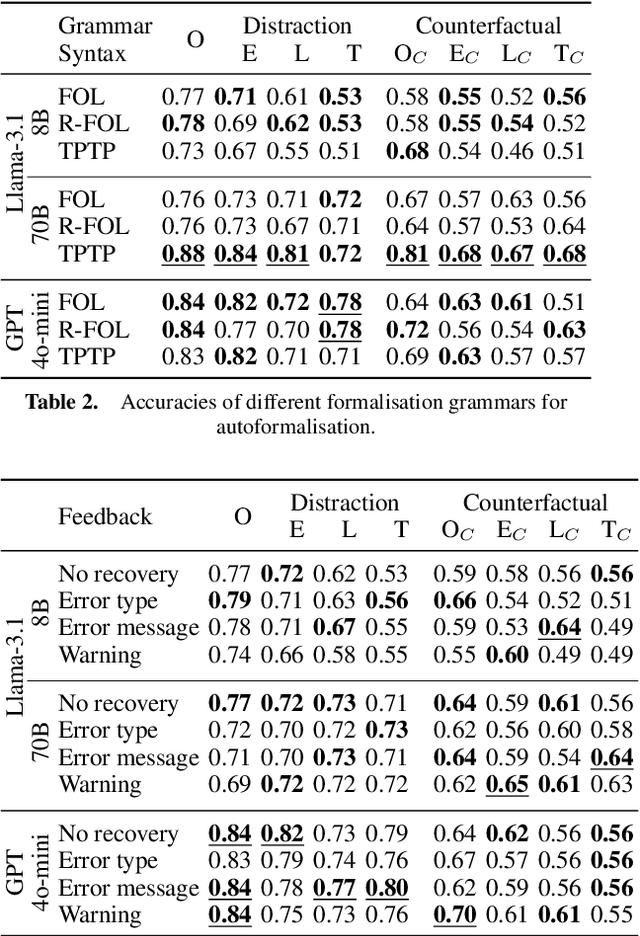
Large Language Models (LLMs) have been shown to achieve impressive results for many reasoning-based Natural Language Processing (NLP) tasks, suggesting a degree of deductive reasoning capability. However, it remains unclear to which extent LLMs, in both informal and autoformalisation methods, are robust on logical deduction tasks. Moreover, while many LLM-based deduction methods have been proposed, there is a lack of a systematic study that analyses the impact of their design components. Addressing these two challenges, we propose the first study of the robustness of LLM-based deductive reasoning methods. We devise a framework with two families of perturbations: adversarial noise and counterfactual statements, which jointly generate seven perturbed datasets. We organize the landscape of LLM reasoners according to their reasoning format, formalisation syntax, and feedback for error recovery. The results show that adversarial noise affects autoformalisation, while counterfactual statements influence all approaches. Detailed feedback does not improve overall accuracy despite reducing syntax errors, pointing to the challenge of LLM-based methods to self-correct effectively.
Semantic Web and Creative AI -- A Technical Report from ISWS 2023
Jan 30, 2025



The International Semantic Web Research School (ISWS) is a week-long intensive program designed to immerse participants in the field. This document reports a collaborative effort performed by ten teams of students, each guided by a senior researcher as their mentor, attending ISWS 2023. Each team provided a different perspective to the topic of creative AI, substantiated by a set of research questions as the main subject of their investigation. The 2023 edition of ISWS focuses on the intersection of Semantic Web technologies and Creative AI. ISWS 2023 explored various intersections between Semantic Web technologies and creative AI. A key area of focus was the potential of LLMs as support tools for knowledge engineering. Participants also delved into the multifaceted applications of LLMs, including legal aspects of creative content production, humans in the loop, decentralised approaches to multimodal generative AI models, nanopublications and AI for personal scientific knowledge graphs, commonsense knowledge in automatic story and narrative completion, generative AI for art critique, prompt engineering, automatic music composition, commonsense prototyping and conceptual blending, and elicitation of tacit knowledge. As Large Language Models and semantic technologies continue to evolve, new exciting prospects are emerging: a future where the boundaries between creative expression and factual knowledge become increasingly permeable and porous, leading to a world of knowledge that is both informative and inspiring.
ChronoSense: Exploring Temporal Understanding in Large Language Models with Time Intervals of Events
Jan 06, 2025



Large Language Models (LLMs) have achieved remarkable success in various NLP tasks, yet they still face significant challenges in reasoning and arithmetic. Temporal reasoning, a critical component of natural language understanding, has raised increasing research attention. However, comprehensive testing of Allen's interval relations (e.g., before, after, during) -- a fundamental framework for temporal relationships -- remains underexplored. To fill this gap, we present ChronoSense, a new benchmark for evaluating LLMs' temporal understanding. It includes 16 tasks, focusing on identifying the Allen relation between two temporal events and temporal arithmetic, using both abstract events and real-world data from Wikidata. We assess the performance of seven recent LLMs using this benchmark and the results indicate that models handle Allen relations, even symmetrical ones, quite differently. Moreover, the findings suggest that the models may rely on memorization to answer time-related questions. Overall, the models' low performance highlights the need for improved temporal understanding in LLMs and ChronoSense offers a robust framework for future research in this area. Our dataset and the source code are available at https://github.com/duyguislakoglu/chronosense.
Evaluating the Knowledge Base Completion Potential of GPT
Oct 23, 2023Structured knowledge bases (KBs) are an asset for search engines and other applications, but are inevitably incomplete. Language models (LMs) have been proposed for unsupervised knowledge base completion (KBC), yet, their ability to do this at scale and with high accuracy remains an open question. Prior experimental studies mostly fall short because they only evaluate on popular subjects, or sample already existing facts from KBs. In this work, we perform a careful evaluation of GPT's potential to complete the largest public KB: Wikidata. We find that, despite their size and capabilities, models like GPT-3, ChatGPT and GPT-4 do not achieve fully convincing results on this task. Nonetheless, they provide solid improvements over earlier approaches with smaller LMs. In particular, we show that, with proper thresholding, GPT-3 enables to extend Wikidata by 27M facts at 90% precision.
* 12 pages 4 tables
Accelerating Thematic Investment with Prompt Tuned Pretrained Language Models
Sep 21, 2023
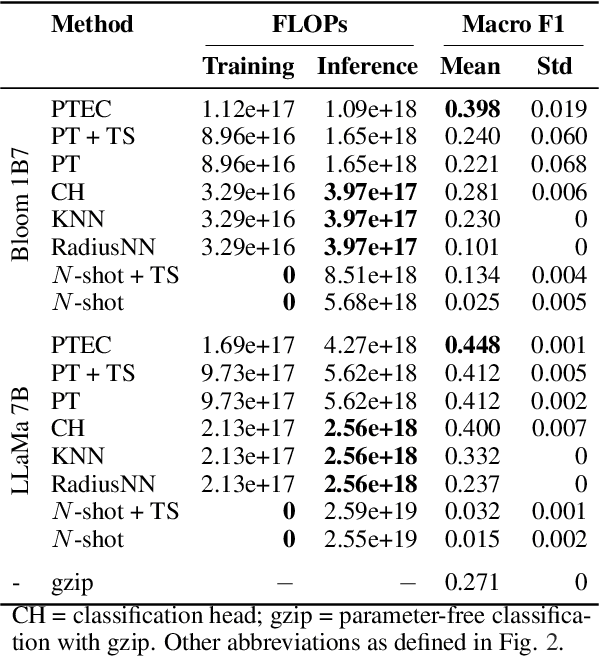


Prompt Tuning is emerging as a scalable and cost-effective method to fine-tune Pretrained Language Models (PLMs). This study benchmarks the performance and computational efficiency of Prompt Tuning and baseline methods on a multi-label text classification task. This is applied to the use case of classifying companies into an investment firm's proprietary industry taxonomy, supporting their thematic investment strategy. Text-to-text classification with PLMs is frequently reported to outperform classification with a classification head, but has several limitations when applied to a multi-label classification problem where each label consists of multiple tokens: (a) Generated labels may not match any label in the industry taxonomy; (b) During fine-tuning, multiple labels must be provided in an arbitrary order; (c) The model provides a binary decision for each label, rather than an appropriate confidence score. Limitation (a) is addressed by applying constrained decoding using Trie Search, which slightly improves classification performance. All limitations (a), (b), and (c) are addressed by replacing the PLM's language head with a classification head. This improves performance significantly, while also reducing computational costs during inference. The results indicate the continuing need to adapt state-of-the-art methods to domain-specific tasks, even in the era of PLMs with strong generalization abilities.
Large Language Models and Knowledge Graphs: Opportunities and Challenges
Aug 11, 2023Large Language Models (LLMs) have taken Knowledge Representation -- and the world -- by storm. This inflection point marks a shift from explicit knowledge representation to a renewed focus on the hybrid representation of both explicit knowledge and parametric knowledge. In this position paper, we will discuss some of the common debate points within the community on LLMs (parametric knowledge) and Knowledge Graphs (explicit knowledge) and speculate on opportunities and visions that the renewed focus brings, as well as related research topics and challenges.
BLOOM: A 176B-Parameter Open-Access Multilingual Language Model
Nov 09, 2022Large language models (LLMs) have been shown to be able to perform new tasks based on a few demonstrations or natural language instructions. While these capabilities have led to widespread adoption, most LLMs are developed by resource-rich organizations and are frequently kept from the public. As a step towards democratizing this powerful technology, we present BLOOM, a 176B-parameter open-access language model designed and built thanks to a collaboration of hundreds of researchers. BLOOM is a decoder-only Transformer language model that was trained on the ROOTS corpus, a dataset comprising hundreds of sources in 46 natural and 13 programming languages (59 in total). We find that BLOOM achieves competitive performance on a wide variety of benchmarks, with stronger results after undergoing multitask prompted finetuning. To facilitate future research and applications using LLMs, we publicly release our models and code under the Responsible AI License.
Prompting as Probing: Using Language Models for Knowledge Base Construction
Aug 25, 2022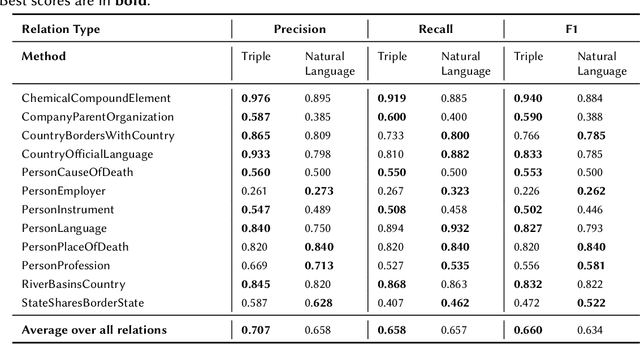
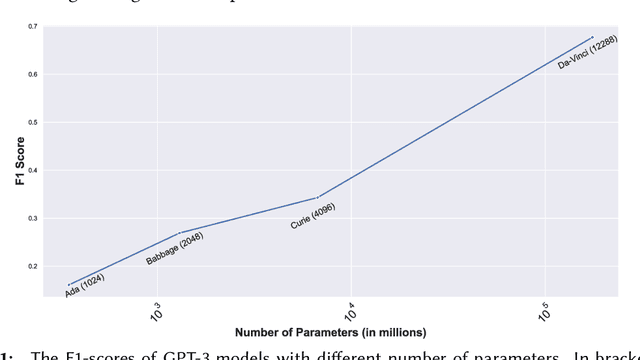
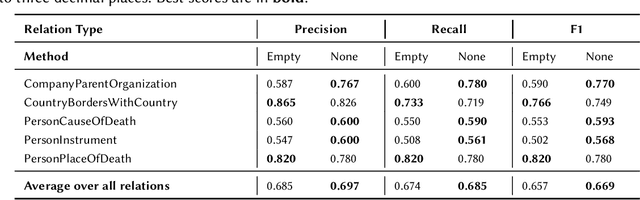
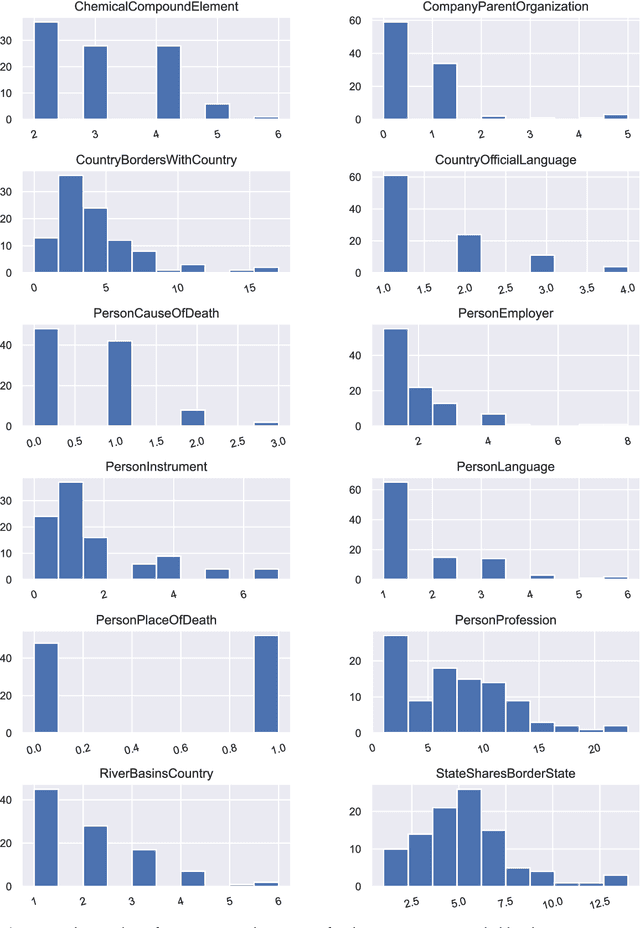
Language Models (LMs) have proven to be useful in various downstream applications, such as summarisation, translation, question answering and text classification. LMs are becoming increasingly important tools in Artificial Intelligence, because of the vast quantity of information they can store. In this work, we present ProP (Prompting as Probing), which utilizes GPT-3, a large Language Model originally proposed by OpenAI in 2020, to perform the task of Knowledge Base Construction (KBC). ProP implements a multi-step approach that combines a variety of prompting techniques to achieve this. Our results show that manual prompt curation is essential, that the LM must be encouraged to give answer sets of variable lengths, in particular including empty answer sets, that true/false questions are a useful device to increase precision on suggestions generated by the LM, that the size of the LM is a crucial factor, and that a dictionary of entity aliases improves the LM score. Our evaluation study indicates that these proposed techniques can substantially enhance the quality of the final predictions: ProP won track 2 of the LM-KBC competition, outperforming the baseline by 36.4 percentage points. Our implementation is available on https://github.com/HEmile/iswc-challenge.