 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccelerating Thematic Investment with Prompt Tuned Pretrained Language Models
Paper and Code
Sep 21, 2023
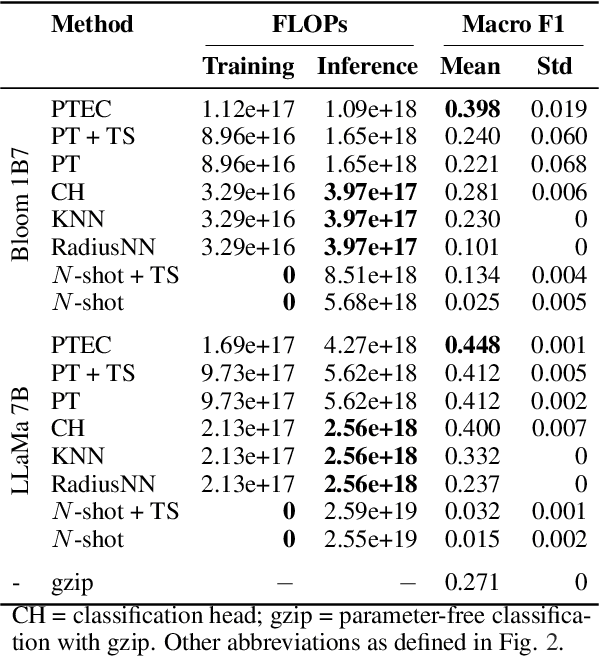


Prompt Tuning is emerging as a scalable and cost-effective method to fine-tune Pretrained Language Models (PLMs). This study benchmarks the performance and computational efficiency of Prompt Tuning and baseline methods on a multi-label text classification task. This is applied to the use case of classifying companies into an investment firm's proprietary industry taxonomy, supporting their thematic investment strategy. Text-to-text classification with PLMs is frequently reported to outperform classification with a classification head, but has several limitations when applied to a multi-label classification problem where each label consists of multiple tokens: (a) Generated labels may not match any label in the industry taxonomy; (b) During fine-tuning, multiple labels must be provided in an arbitrary order; (c) The model provides a binary decision for each label, rather than an appropriate confidence score. Limitation (a) is addressed by applying constrained decoding using Trie Search, which slightly improves classification performance. All limitations (a), (b), and (c) are addressed by replacing the PLM's language head with a classification head. This improves performance significantly, while also reducing computational costs during inference. The results indicate the continuing need to adapt state-of-the-art methods to domain-specific tasks, even in the era of PLMs with strong generalization abilities.