 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWorking with AI: Measuring the Occupational Implications of Generative AI
Jul 10, 2025Given the rapid adoption of generative AI and its potential to impact a wide range of tasks, understanding the effects of AI on the economy is one of society's most important questions. In this work, we take a step toward that goal by analyzing the work activities people do with AI, how successfully and broadly those activities are done, and combine that with data on what occupations do those activities. We analyze a dataset of 200k anonymized and privacy-scrubbed conversations between users and Microsoft Bing Copilot, a publicly available generative AI system. We find the most common work activities people seek AI assistance for involve gathering information and writing, while the most common activities that AI itself is performing are providing information and assistance, writing, teaching, and advising. Combining these activity classifications with measurements of task success and scope of impact, we compute an AI applicability score for each occupation. We find the highest AI applicability scores for knowledge work occupation groups such as computer and mathematical, and office and administrative support, as well as occupations such as sales whose work activities involve providing and communicating information. Additionally, we characterize the types of work activities performed most successfully, how wage and education correlate with AI applicability, and how real-world usage compares to predictions of occupational AI impact.
Interpretable User Satisfaction Estimation for Conversational Systems with Large Language Models
Mar 19, 2024
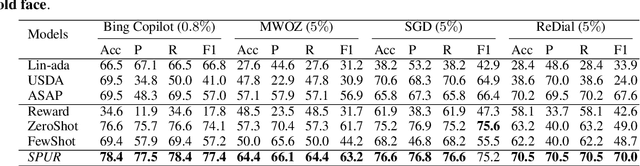
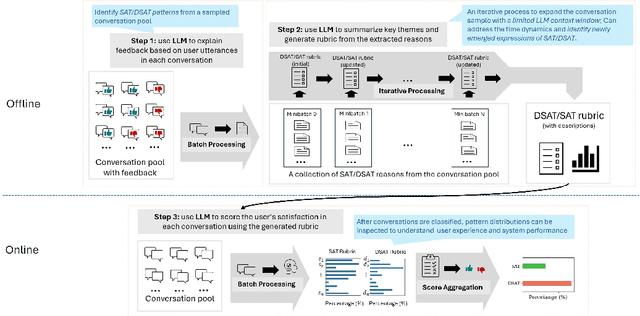
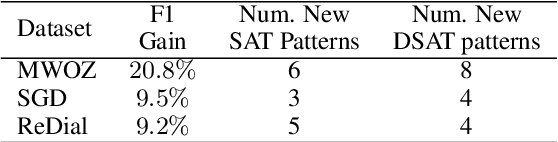
Accurate and interpretable user satisfaction estimation (USE) is critical for understanding, evaluating, and continuously improving conversational systems. Users express their satisfaction or dissatisfaction with diverse conversational patterns in both general-purpose (ChatGPT and Bing Copilot) and task-oriented (customer service chatbot) conversational systems. Existing approaches based on featurized ML models or text embeddings fall short in extracting generalizable patterns and are hard to interpret. In this work, we show that LLMs can extract interpretable signals of user satisfaction from their natural language utterances more effectively than embedding-based approaches. Moreover, an LLM can be tailored for USE via an iterative prompting framework using supervision from labeled examples. The resulting method, Supervised Prompting for User satisfaction Rubrics (SPUR), not only has higher accuracy but is more interpretable as it scores user satisfaction via learned rubrics with a detailed breakdown.
TnT-LLM: Text Mining at Scale with Large Language Models
Mar 18, 2024Transforming unstructured text into structured and meaningful forms, organized by useful category labels, is a fundamental step in text mining for downstream analysis and application. However, most existing methods for producing label taxonomies and building text-based label classifiers still rely heavily on domain expertise and manual curation, making the process expensive and time-consuming. This is particularly challenging when the label space is under-specified and large-scale data annotations are unavailable. In this paper, we address these challenges with Large Language Models (LLMs), whose prompt-based interface facilitates the induction and use of large-scale pseudo labels. We propose TnT-LLM, a two-phase framework that employs LLMs to automate the process of end-to-end label generation and assignment with minimal human effort for any given use-case. In the first phase, we introduce a zero-shot, multi-stage reasoning approach which enables LLMs to produce and refine a label taxonomy iteratively. In the second phase, LLMs are used as data labelers that yield training samples so that lightweight supervised classifiers can be reliably built, deployed, and served at scale. We apply TnT-LLM to the analysis of user intent and conversational domain for Bing Copilot (formerly Bing Chat), an open-domain chat-based search engine. Extensive experiments using both human and automatic evaluation metrics demonstrate that TnT-LLM generates more accurate and relevant label taxonomies when compared against state-of-the-art baselines, and achieves a favorable balance between accuracy and efficiency for classification at scale. We also share our practical experiences and insights on the challenges and opportunities of using LLMs for large-scale text mining in real-world applications.
Using Large Language Models to Generate, Validate, and Apply User Intent Taxonomies
Sep 14, 2023



Log data can reveal valuable information about how users interact with web search services, what they want, and how satisfied they are. However, analyzing user intents in log data is not easy, especially for new forms of web search such as AI-driven chat. To understand user intents from log data, we need a way to label them with meaningful categories that capture their diversity and dynamics. Existing methods rely on manual or ML-based labeling, which are either expensive or inflexible for large and changing datasets. We propose a novel solution using large language models (LLMs), which can generate rich and relevant concepts, descriptions, and examples for user intents. However, using LLMs to generate a user intent taxonomy and apply it to do log analysis can be problematic for two main reasons: such a taxonomy is not externally validated, and there may be an undesirable feedback loop. To overcome these issues, we propose a new methodology with human experts and assessors to verify the quality of the LLM-generated taxonomy. We also present an end-to-end pipeline that uses an LLM with human-in-the-loop to produce, refine, and use labels for user intent analysis in log data. Our method offers a scalable and adaptable way to analyze user intents in web-scale log data with minimal human effort. We demonstrate its effectiveness by uncovering new insights into user intents from search and chat logs from Bing.
What You See Is What You Get? The Impact of Representation Criteria on Human Bias in Hiring
Sep 08, 2019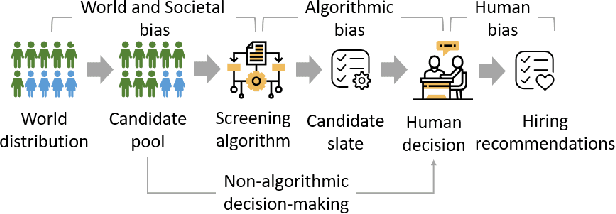
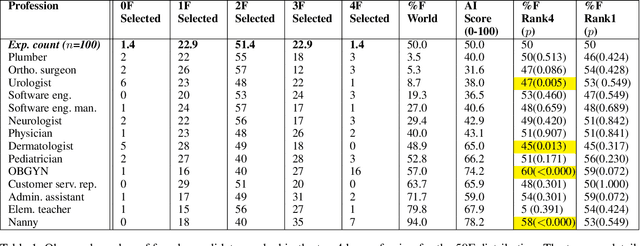
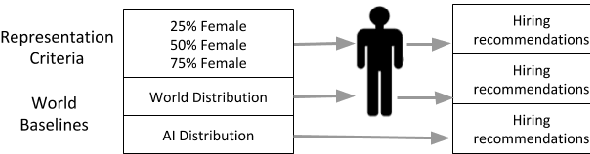
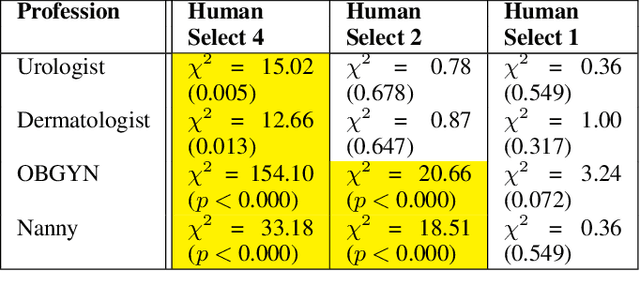
Although systematic biases in decision-making are widely documented, the ways in which they emerge from different sources is less understood. We present a controlled experimental platform to study gender bias in hiring by decoupling the effect of world distribution (the gender breakdown of candidates in a specific profession) from bias in human decision-making. We explore the effectiveness of \textit{representation criteria}, fixed proportional display of candidates, as an intervention strategy for mitigation of gender bias by conducting experiments measuring human decision-makers' rankings for who they would recommend as potential hires. Experiments across professions with varying gender proportions show that balancing gender representation in candidate slates can correct biases for some professions where the world distribution is skewed, although doing so has no impact on other professions where human persistent preferences are at play. We show that the gender of the decision-maker, complexity of the decision-making task and over- and under-representation of genders in the candidate slate can all impact the final decision. By decoupling sources of bias, we can better isolate strategies for bias mitigation in human-in-the-loop systems.