 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Node Representation Interpretation through Relation Coherence
Nov 01, 2024Understanding node representations in graph-based models is crucial for uncovering biases ,diagnosing errors, and building trust in model decisions. However, previous work on explainable AI for node representations has primarily emphasized explanations (reasons for model predictions) rather than interpretations (mapping representations to understandable concepts). Furthermore, the limited research that focuses on interpretation lacks validation, and thus the reliability of such methods is unclear. We address this gap by proposing a novel interpretation method-Node Coherence Rate for Representation Interpretation (NCI)-which quantifies how well different node relations are captured in node representations. We also propose a novel method (IME) to evaluate the accuracy of different interpretation methods. Our experimental results demonstrate that NCI reduces the error of the previous best approach by an average of 39%. We then apply NCI to derive insights about the node representations produced by several graph-based methods and assess their quality in unsupervised settings.
Improving Node Representation by Boosting Target-Aware Contrastive Loss
Oct 04, 2024Graphs model complex relationships between entities, with nodes and edges capturing intricate connections. Node representation learning involves transforming nodes into low-dimensional embeddings. These embeddings are typically used as features for downstream tasks. Therefore, their quality has a significant impact on task performance. Existing approaches for node representation learning span (semi-)supervised, unsupervised, and self-supervised paradigms. In graph domains, (semi-)supervised learning often only optimizes models based on class labels, neglecting other abundant graph signals, which limits generalization. While self-supervised or unsupervised learning produces representations that better capture underlying graph signals, the usefulness of these captured signals for downstream target tasks can vary. To bridge this gap, we introduce Target-Aware Contrastive Learning (Target-aware CL) which aims to enhance target task performance by maximizing the mutual information between the target task and node representations with a self-supervised learning process. This is achieved through a sampling function, XGBoost Sampler (XGSampler), to sample proper positive examples for the proposed Target-Aware Contrastive Loss (XTCL). By minimizing XTCL, Target-aware CL increases the mutual information between the target task and node representations, such that model generalization is improved. Additionally, XGSampler enhances the interpretability of each signal by showing the weights for sampling the proper positive examples. We show experimentally that XTCL significantly improves the performance on two target tasks: node classification and link prediction tasks, compared to state-of-the-art models.
WildFeedback: Aligning LLMs With In-situ User Interactions And Feedback
Aug 28, 2024



As large language models (LLMs) continue to advance, aligning these models with human preferences has emerged as a critical challenge. Traditional alignment methods, relying on human or LLM annotated datasets, are limited by their resource-intensive nature, inherent subjectivity, and the risk of feedback loops that amplify model biases. To overcome these limitations, we introduce WildFeedback, a novel framework that leverages real-time, in-situ user interactions to create preference datasets that more accurately reflect authentic human values. WildFeedback operates through a three-step process: feedback signal identification, preference data construction, and user-guided evaluation. We applied this framework to a large corpus of user-LLM conversations, resulting in a rich preference dataset that reflects genuine user preferences. This dataset captures the nuances of user preferences by identifying and classifying feedback signals within natural conversations, thereby enabling the construction of more representative and context-sensitive alignment data. Our extensive experiments demonstrate that LLMs fine-tuned on WildFeedback exhibit significantly improved alignment with user preferences, as evidenced by both traditional benchmarks and our proposed user-guided evaluation. By incorporating real-time feedback from actual users, WildFeedback addresses the scalability, subjectivity, and bias challenges that plague existing approaches, marking a significant step toward developing LLMs that are more responsive to the diverse and evolving needs of their users. In summary, WildFeedback offers a robust, scalable solution for aligning LLMs with true human values, setting a new standard for the development and evaluation of user-centric language models.
Interpretable User Satisfaction Estimation for Conversational Systems with Large Language Models
Mar 19, 2024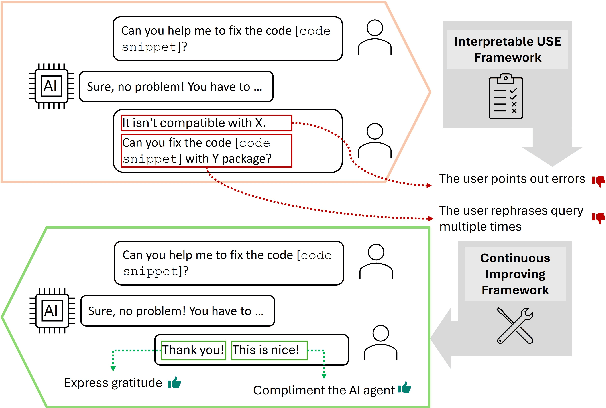
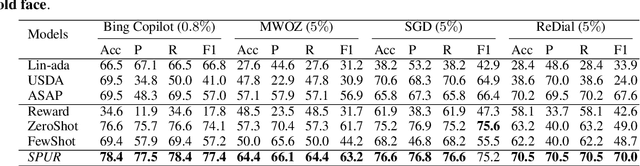
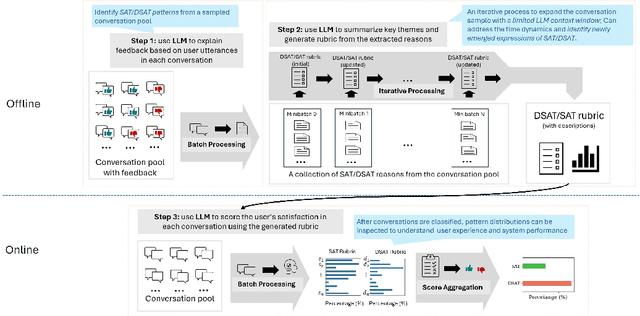
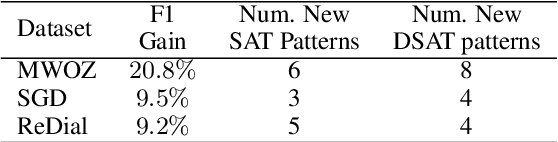
Accurate and interpretable user satisfaction estimation (USE) is critical for understanding, evaluating, and continuously improving conversational systems. Users express their satisfaction or dissatisfaction with diverse conversational patterns in both general-purpose (ChatGPT and Bing Copilot) and task-oriented (customer service chatbot) conversational systems. Existing approaches based on featurized ML models or text embeddings fall short in extracting generalizable patterns and are hard to interpret. In this work, we show that LLMs can extract interpretable signals of user satisfaction from their natural language utterances more effectively than embedding-based approaches. Moreover, an LLM can be tailored for USE via an iterative prompting framework using supervision from labeled examples. The resulting method, Supervised Prompting for User satisfaction Rubrics (SPUR), not only has higher accuracy but is more interpretable as it scores user satisfaction via learned rubrics with a detailed breakdown.