 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWildFeedback: Aligning LLMs With In-situ User Interactions And Feedback
Aug 28, 2024



As large language models (LLMs) continue to advance, aligning these models with human preferences has emerged as a critical challenge. Traditional alignment methods, relying on human or LLM annotated datasets, are limited by their resource-intensive nature, inherent subjectivity, and the risk of feedback loops that amplify model biases. To overcome these limitations, we introduce WildFeedback, a novel framework that leverages real-time, in-situ user interactions to create preference datasets that more accurately reflect authentic human values. WildFeedback operates through a three-step process: feedback signal identification, preference data construction, and user-guided evaluation. We applied this framework to a large corpus of user-LLM conversations, resulting in a rich preference dataset that reflects genuine user preferences. This dataset captures the nuances of user preferences by identifying and classifying feedback signals within natural conversations, thereby enabling the construction of more representative and context-sensitive alignment data. Our extensive experiments demonstrate that LLMs fine-tuned on WildFeedback exhibit significantly improved alignment with user preferences, as evidenced by both traditional benchmarks and our proposed user-guided evaluation. By incorporating real-time feedback from actual users, WildFeedback addresses the scalability, subjectivity, and bias challenges that plague existing approaches, marking a significant step toward developing LLMs that are more responsive to the diverse and evolving needs of their users. In summary, WildFeedback offers a robust, scalable solution for aligning LLMs with true human values, setting a new standard for the development and evaluation of user-centric language models.
Supporting Complex Information-Seeking Tasks with Implicit Constraints
May 02, 2022
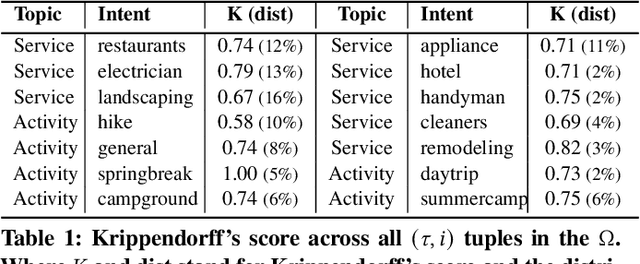
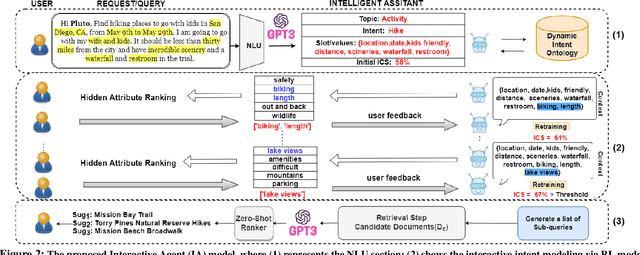
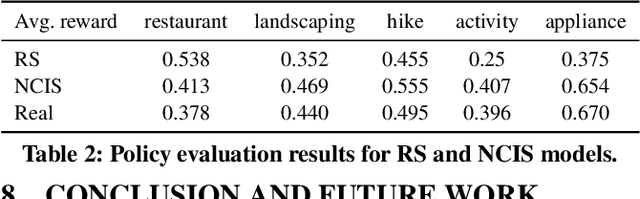
Current interactive systems with natural language interface lack an ability to understand a complex information-seeking request which expresses several implicit constraints at once, and there is no prior information about user preferences, e.g., "find hiking trails around San Francisco which are accessible with toddlers and have beautiful scenery in summer", where output is a list of possible suggestions for users to start their exploration. In such scenarios, the user requests can be issued at once in the form of a complex and long query, unlike conversational and exploratory search models that require short utterances or queries where they often require to be fed into the system step by step. This advancement provides the final user more flexibility and precision in expressing their intent through the search process. Such systems are inherently helpful for day-today user tasks requiring planning that are usually time-consuming, sometimes tricky, and cognitively taxing. We have designed and deployed a platform to collect the data from approaching such complex interactive systems. In this paper, we propose an Interactive Agent (IA) that allows intricately refined user requests by making it complete, which should lead to better retrieval. To demonstrate the performance of the proposed modeling paradigm, we have adopted various pre-retrieval metrics that capture the extent to which guided interactions with our system yield better retrieval results. Through extensive experimentation, we demonstrated that our method significantly outperforms several robust baselines