 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOne Model, All Roles: Multi-Turn, Multi-Agent Self-Play Reinforcement Learning for Conversational Social Intelligence
Feb 03, 2026This paper introduces OMAR: One Model, All Roles, a reinforcement learning framework that enables AI to develop social intelligence through multi-turn, multi-agent conversational self-play. Unlike traditional paradigms that rely on static, single-turn optimizations, OMAR allows a single model to role-play all participants in a conversation simultaneously, learning to achieve long-term goals and complex social norms directly from dynamic social interaction. To ensure training stability across long dialogues, we implement a hierarchical advantage estimation that calculates turn-level and token-level advantages. Evaluations in the SOTOPIA social environment and Werewolf strategy games show that our trained models develop fine-grained, emergent social intelligence, such as empathy, persuasion, and compromise seeking, demonstrating the effectiveness of learning collaboration even under competitive scenarios. While we identify practical challenges like reward hacking, our results show that rich social intelligence can emerge without human supervision. We hope this work incentivizes further research on AI social intelligence in group conversations.
CoAct-1: Computer-using Agents with Coding as Actions
Aug 05, 2025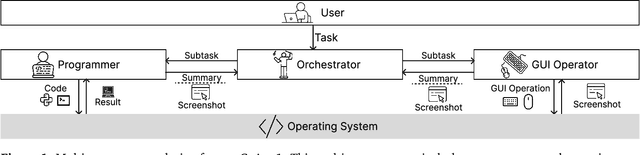
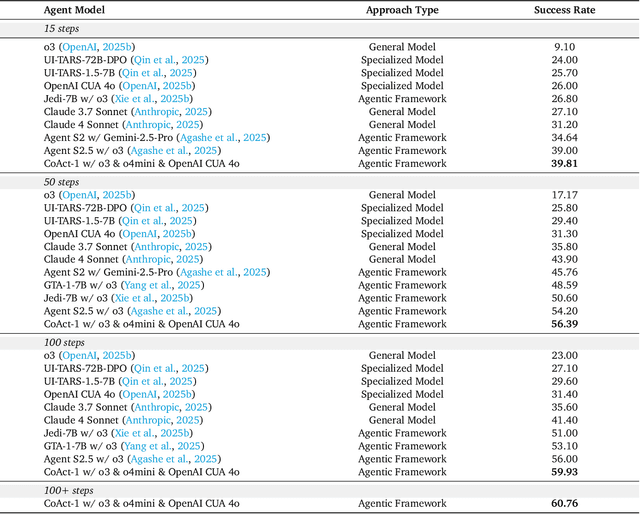
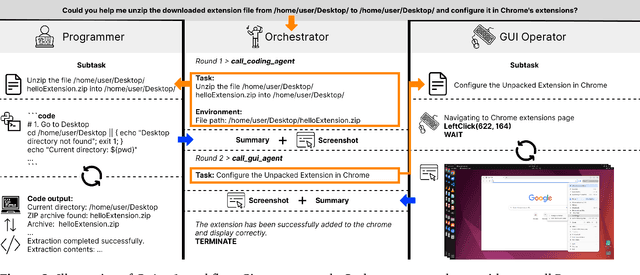

Autonomous agents that operate computers via Graphical User Interfaces (GUIs) often struggle with efficiency and reliability on complex, long-horizon tasks. While augmenting these agents with planners can improve task decomposition, they remain constrained by the inherent limitations of performing all actions through GUI manipulation, leading to brittleness and inefficiency. In this work, we introduce a more robust and flexible paradigm: enabling agents to use coding as a enhanced action. We present CoAct-1, a novel multi-agent system that synergistically combines GUI-based control with direct programmatic execution. CoAct-1 features an Orchestrator that dynamically delegates subtasks to either a conventional GUI Operator or a specialized Programmer agent, which can write and execute Python or Bash scripts. This hybrid approach allows the agent to bypass inefficient GUI action sequences for tasks like file management and data processing, while still leveraging visual interaction when necessary. We evaluate our system on the challenging OSWorld benchmark, where CoAct-1 achieves a new state-of-the-art success rate of 60.76%, significantly outperforming prior methods. Furthermore, our approach dramatically improves efficiency, reducing the average number of steps required to complete a task to just 10.15, compared to 15 for leading GUI agents. Our results demonstrate that integrating coding as a core action provides a more powerful, efficient, and scalable path toward generalized computer automation.
STEER-BENCH: A Benchmark for Evaluating the Steerability of Large Language Models
May 27, 2025Steerability, or the ability of large language models (LLMs) to adapt outputs to align with diverse community-specific norms, perspectives, and communication styles, is critical for real-world applications but remains under-evaluated. We introduce Steer-Bench, a benchmark for assessing population-specific steering using contrasting Reddit communities. Covering 30 contrasting subreddit pairs across 19 domains, Steer-Bench includes over 10,000 instruction-response pairs and validated 5,500 multiple-choice question with corresponding silver labels to test alignment with diverse community norms. Our evaluation of 13 popular LLMs using Steer-Bench reveals that while human experts achieve an accuracy of 81% with silver labels, the best-performing models reach only around 65% accuracy depending on the domain and configuration. Some models lag behind human-level alignment by over 15 percentage points, highlighting significant gaps in community-sensitive steerability. Steer-Bench is a benchmark to systematically assess how effectively LLMs understand community-specific instructions, their resilience to adversarial steering attempts, and their ability to accurately represent diverse cultural and ideological perspectives.
The Hallucination Tax of Reinforcement Finetuning
May 20, 2025Reinforcement finetuning (RFT) has become a standard approach for enhancing the reasoning capabilities of large language models (LLMs). However, its impact on model trustworthiness remains underexplored. In this work, we identify and systematically study a critical side effect of RFT, which we term the hallucination tax: a degradation in refusal behavior causing models to produce hallucinated answers to unanswerable questions confidently. To investigate this, we introduce SUM (Synthetic Unanswerable Math), a high-quality dataset of unanswerable math problems designed to probe models' ability to recognize an unanswerable question by reasoning from the insufficient or ambiguous information. Our results show that standard RFT training could reduce model refusal rates by more than 80%, which significantly increases model's tendency to hallucinate. We further demonstrate that incorporating just 10% SUM during RFT substantially restores appropriate refusal behavior, with minimal accuracy trade-offs on solvable tasks. Crucially, this approach enables LLMs to leverage inference-time compute to reason about their own uncertainty and knowledge boundaries, improving generalization not only to out-of-domain math problems but also to factual question answering tasks.
Efficient Reinforcement Finetuning via Adaptive Curriculum Learning
Apr 07, 2025Reinforcement finetuning (RFT) has shown great potential for enhancing the mathematical reasoning capabilities of large language models (LLMs), but it is often sample- and compute-inefficient, requiring extensive training. In this work, we introduce AdaRFT (Adaptive Curriculum Reinforcement Finetuning), a method that significantly improves both the efficiency and final accuracy of RFT through adaptive curriculum learning. AdaRFT dynamically adjusts the difficulty of training problems based on the model's recent reward signals, ensuring that the model consistently trains on tasks that are challenging but solvable. This adaptive sampling strategy accelerates learning by maintaining an optimal difficulty range, avoiding wasted computation on problems that are too easy or too hard. AdaRFT requires only a lightweight extension to standard RFT algorithms like Proximal Policy Optimization (PPO), without modifying the reward function or model architecture. Experiments on competition-level math datasets-including AMC, AIME, and IMO-style problems-demonstrate that AdaRFT significantly improves both training efficiency and reasoning performance. We evaluate AdaRFT across multiple data distributions and model sizes, showing that it reduces the number of training steps by up to 2x and improves accuracy by a considerable margin, offering a more scalable and effective RFT framework.
Discovering Knowledge Deficiencies of Language Models on Massive Knowledge Base
Mar 30, 2025Large language models (LLMs) possess impressive linguistic capabilities but often fail to faithfully retain factual knowledge, leading to hallucinations and unreliable outputs. Understanding LLMs' knowledge deficiencies by exhaustively evaluating against full-scale knowledge bases is computationally prohibitive, especially for closed-weight models. We propose stochastic error ascent (SEA), a scalable and efficient framework for discovering knowledge deficiencies (errors) in closed-weight LLMs under a strict query budget. Rather than naively probing all knowledge candidates, SEA formulates error discovery as a stochastic optimization process: it iteratively retrieves new high-error candidates by leveraging the semantic similarity to previously observed failures. To further enhance search efficiency and coverage, SEA employs hierarchical retrieval across document and paragraph levels, and constructs a relation directed acyclic graph to model error propagation and identify systematic failure modes. Empirically, SEA uncovers 40.7x more knowledge errors than Automated Capability Discovery and 26.7% more than AutoBencher, while reducing the cost-per-error by 599x and 9x, respectively. Human evaluation confirms the high quality of generated questions, while ablation and convergence analyses validate the contribution of each component in SEA. Further analysis on the discovered errors reveals correlated failure patterns across LLM families and recurring deficits, highlighting the need for better data coverage and targeted fine-tuning in future LLM development.
Detecting and Filtering Unsafe Training Data via Data Attribution
Feb 17, 2025Large language models (LLMs) are vulnerable to unsafe training data that even small amounts of unsafe data can lead to harmful model behaviors. Detecting and filtering such unsafe training data is essential for trustworthy model development. Current state-of-the-art (SOTA) approaches typically rely on training moderation classifiers which requires significant computational overhead and are limited to predefined taxonomies, making them less adaptable to evolving safety concerns. Moreover, these classifiers lack insight into the training process, limiting their effectiveness in filtering unsafe data. To address these limitations, we propose DABUF, leveraging data attribution to detect and filter unsafe training data by attributing harmful model outputs to influential training data points. DABUF enables flexible identification of various unsafe data types without predefined taxonomies. However, in practice, model outputs can be complex with combined safe linguistic features and unsafe content, leading to reduced attribution accuracy. In such cases, DABUF will integrate moderation classifiers to identify a minimal subset of unsafe training data for targeted attribution (such as jailbreak). When model outputs are relatively straightforward, DABUF uses model outputs directly as the attribution targets. We evaluate the performance on two different tasks: in filtering jailbreaking training data and in identifying and mitigating gender bias. DABUF outperforms SOTA approaches by up to 7.5\% in detection AUPRC in jailbreaking scenarios, and 44.1\% in detecting gender bias. Moreover, retraining on DABUF-filtered data leads to higher model safety across experiments, underscoring its versatility in addressing a broad spectrum of unsafe data issues.
WildFeedback: Aligning LLMs With In-situ User Interactions And Feedback
Aug 28, 2024



As large language models (LLMs) continue to advance, aligning these models with human preferences has emerged as a critical challenge. Traditional alignment methods, relying on human or LLM annotated datasets, are limited by their resource-intensive nature, inherent subjectivity, and the risk of feedback loops that amplify model biases. To overcome these limitations, we introduce WildFeedback, a novel framework that leverages real-time, in-situ user interactions to create preference datasets that more accurately reflect authentic human values. WildFeedback operates through a three-step process: feedback signal identification, preference data construction, and user-guided evaluation. We applied this framework to a large corpus of user-LLM conversations, resulting in a rich preference dataset that reflects genuine user preferences. This dataset captures the nuances of user preferences by identifying and classifying feedback signals within natural conversations, thereby enabling the construction of more representative and context-sensitive alignment data. Our extensive experiments demonstrate that LLMs fine-tuned on WildFeedback exhibit significantly improved alignment with user preferences, as evidenced by both traditional benchmarks and our proposed user-guided evaluation. By incorporating real-time feedback from actual users, WildFeedback addresses the scalability, subjectivity, and bias challenges that plague existing approaches, marking a significant step toward developing LLMs that are more responsive to the diverse and evolving needs of their users. In summary, WildFeedback offers a robust, scalable solution for aligning LLMs with true human values, setting a new standard for the development and evaluation of user-centric language models.
How Susceptible are Large Language Models to Ideological Manipulation?
Feb 22, 2024



Large Language Models (LLMs) possess the potential to exert substantial influence on public perceptions and interactions with information. This raises concerns about the societal impact that could arise if the ideologies within these models can be easily manipulated. In this work, we investigate how effectively LLMs can learn and generalize ideological biases from their instruction-tuning data. Our findings reveal a concerning vulnerability: exposure to only a small amount of ideologically driven samples significantly alters the ideology of LLMs. Notably, LLMs demonstrate a startling ability to absorb ideology from one topic and generalize it to even unrelated ones. The ease with which LLMs' ideologies can be skewed underscores the risks associated with intentionally poisoned training data by malicious actors or inadvertently introduced biases by data annotators. It also emphasizes the imperative for robust safeguards to mitigate the influence of ideological manipulations on LLMs.
Can Language Model Moderators Improve the Health of Online Discourse?
Nov 16, 2023



Human moderation of online conversation is essential to maintaining civility and focus in a dialogue, but is challenging to scale and harmful to moderators. The inclusion of sophisticated natural language generation modules as a force multiplier aid moderators is a tantalizing prospect, but adequate evaluation approaches have so far been elusive. In this paper, we establish a systematic definition of conversational moderation effectiveness through a multidisciplinary lens that incorporates insights from social science. We then propose a comprehensive evaluation framework that uses this definition to asses models' moderation capabilities independently of human intervention. With our framework, we conduct the first known study of conversational dialogue models as moderators, finding that appropriately prompted models can provide specific and fair feedback on toxic behavior but struggle to influence users to increase their levels of respect and cooperation.