 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEMO: Frustratingly Easy Progressive Training of Extendable MoE
May 14, 2026Sparse Mixture-of-Experts (MoE) models offer a powerful way to scale model size without increasing compute, as per-token FLOPs depend only on k active experts rather than the total pool of E experts. Yet, this asymmetry creates an MoE efficiency paradox in practice: adding more experts balloons memory and communication costs, making actual training inefficient. We argue that this bottleneck arises in part because current MoE training allocates too many experts from the beginning, even though early-stage data may not fully utilize such capacity. Motivated by this, we propose EMO, a simple progressive training framework that treats MoE capacity as expandable memory and grows the expert pool over the course of training. EMO explicitly models sparsity in scaling law to derive stage-wise compute-optimal token budgets for progressive expansion. Empirical results show that EMO matches the performance of a fixed-expert setup in large-scale experiments while improving wall-clock efficiency. It offers a surprisingly simple yet effective path to scalable MoE training, preserving the benefits of large expert pools while reducing both training time and GPU cost.
Secret Keepers: The Impact of LLMs on Linguistic Markers of Personal Traits
Apr 03, 2024



Prior research has established associations between individuals' language usage and their personal traits; our linguistic patterns reveal information about our personalities, emotional states, and beliefs. However, with the increasing adoption of Large Language Models (LLMs) as writing assistants in everyday writing, a critical question emerges: are authors' linguistic patterns still predictive of their personal traits when LLMs are involved in the writing process? We investigate the impact of LLMs on the linguistic markers of demographic and psychological traits, specifically examining three LLMs - GPT3.5, Llama 2, and Gemini - across six different traits: gender, age, political affiliation, personality, empathy, and morality. Our findings indicate that although the use of LLMs slightly reduces the predictive power of linguistic patterns over authors' personal traits, the significant changes are infrequent, and the use of LLMs does not fully diminish the predictive power of authors' linguistic patterns over their personal traits. We also note that some theoretically established lexical-based linguistic markers lose their reliability as predictors when LLMs are used in the writing process. Our findings have important implications for the study of linguistic markers of personal traits in the age of LLMs.
Can Language Model Moderators Improve the Health of Online Discourse?
Nov 16, 2023



Human moderation of online conversation is essential to maintaining civility and focus in a dialogue, but is challenging to scale and harmful to moderators. The inclusion of sophisticated natural language generation modules as a force multiplier aid moderators is a tantalizing prospect, but adequate evaluation approaches have so far been elusive. In this paper, we establish a systematic definition of conversational moderation effectiveness through a multidisciplinary lens that incorporates insights from social science. We then propose a comprehensive evaluation framework that uses this definition to asses models' moderation capabilities independently of human intervention. With our framework, we conduct the first known study of conversational dialogue models as moderators, finding that appropriately prompted models can provide specific and fair feedback on toxic behavior but struggle to influence users to increase their levels of respect and cooperation.
MIDDAG: Where Does Our News Go? Investigating Information Diffusion via Community-Level Information Pathways
Oct 04, 2023We present MIDDAG, an intuitive, interactive system that visualizes the information propagation paths on social media triggered by COVID-19-related news articles accompanied by comprehensive insights including user/community susceptibility level, as well as events and popular opinions raised by the crowd while propagating the information. Besides discovering information flow patterns among users, we construct communities among users and develop the propagation forecasting capability, enabling tracing and understanding of how information is disseminated at a higher level.
Beyond the Imitation Game: Quantifying and extrapolating the capabilities of language models
Jun 10, 2022Language models demonstrate both quantitative improvement and new qualitative capabilities with increasing scale. Despite their potentially transformative impact, these new capabilities are as yet poorly characterized. In order to inform future research, prepare for disruptive new model capabilities, and ameliorate socially harmful effects, it is vital that we understand the present and near-future capabilities and limitations of language models. To address this challenge, we introduce the Beyond the Imitation Game benchmark (BIG-bench). BIG-bench currently consists of 204 tasks, contributed by 442 authors across 132 institutions. Task topics are diverse, drawing problems from linguistics, childhood development, math, common-sense reasoning, biology, physics, social bias, software development, and beyond. BIG-bench focuses on tasks that are believed to be beyond the capabilities of current language models. We evaluate the behavior of OpenAI's GPT models, Google-internal dense transformer architectures, and Switch-style sparse transformers on BIG-bench, across model sizes spanning millions to hundreds of billions of parameters. In addition, a team of human expert raters performed all tasks in order to provide a strong baseline. Findings include: model performance and calibration both improve with scale, but are poor in absolute terms (and when compared with rater performance); performance is remarkably similar across model classes, though with benefits from sparsity; tasks that improve gradually and predictably commonly involve a large knowledge or memorization component, whereas tasks that exhibit "breakthrough" behavior at a critical scale often involve multiple steps or components, or brittle metrics; social bias typically increases with scale in settings with ambiguous context, but this can be improved with prompting.
DEAM: Dialogue Coherence Evaluation using AMR-based Semantic Manipulations
Mar 18, 2022
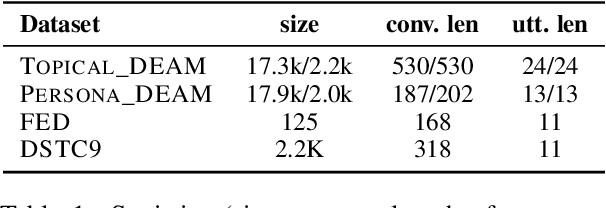
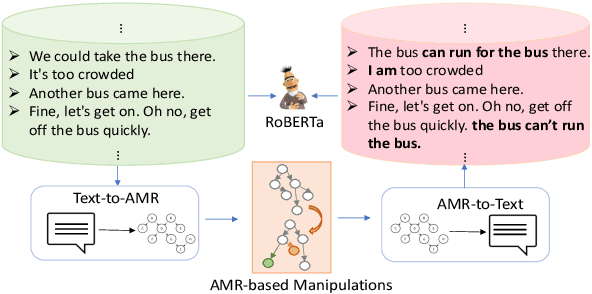
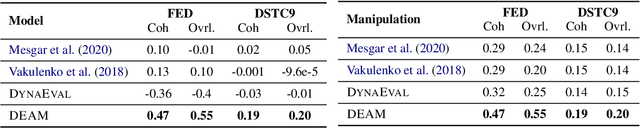
Automatic evaluation metrics are essential for the rapid development of open-domain dialogue systems as they facilitate hyper-parameter tuning and comparison between models. Although recently proposed trainable conversation-level metrics have shown encouraging results, the quality of the metrics is strongly dependent on the quality of training data. Prior works mainly resort to heuristic text-level manipulations (e.g. utterances shuffling) to bootstrap incoherent conversations (negative examples) from coherent dialogues (positive examples). Such approaches are insufficient to appropriately reflect the incoherence that occurs in interactions between advanced dialogue models and humans. To tackle this problem, we propose DEAM, a Dialogue coherence Evaluation metric that relies on Abstract Meaning Representation (AMR) to apply semantic-level Manipulations for incoherent (negative) data generation. AMRs naturally facilitate the injection of various types of incoherence sources, such as coreference inconsistency, irrelevancy, contradictions, and decrease engagement, at the semantic level, thus resulting in more natural incoherent samples. Our experiments show that DEAM achieves higher correlations with human judgments compared to baseline methods on several dialog datasets by significant margins. We also show that DEAM can distinguish between coherent and incoherent dialogues generated by baseline manipulations, whereas those baseline models cannot detect incoherent examples generated by DEAM. Our results demonstrate the potential of AMR-based semantic manipulations for natural negative example generation.
COM2SENSE: A Commonsense Reasoning Benchmark with Complementary Sentences
Jun 02, 2021Commonsense reasoning is intuitive for humans but has been a long-term challenge for artificial intelligence (AI). Recent advancements in pretrained language models have shown promising results on several commonsense benchmark datasets. However, the reliability and comprehensiveness of these benchmarks towards assessing model's commonsense reasoning ability remains unclear. To this end, we introduce a new commonsense reasoning benchmark dataset comprising natural language true/false statements, with each sample paired with its complementary counterpart, resulting in 4k sentence pairs. We propose a pairwise accuracy metric to reliably measure an agent's ability to perform commonsense reasoning over a given situation. The dataset is crowdsourced and enhanced with an adversarial model-in-the-loop setup to incentivize challenging samples. To facilitate a systematic analysis of commonsense capabilities, we design our dataset along the dimensions of knowledge domains, reasoning scenarios and numeracy. Experimental results demonstrate that our strongest baseline (UnifiedQA-3B), after fine-tuning, achieves ~71% standard accuracy and ~51% pairwise accuracy, well below human performance (~95% for both metrics). The dataset is available at https://github.com/PlusLabNLP/Com2Sense.
EventPlus: A Temporal Event Understanding Pipeline
Jan 13, 2021
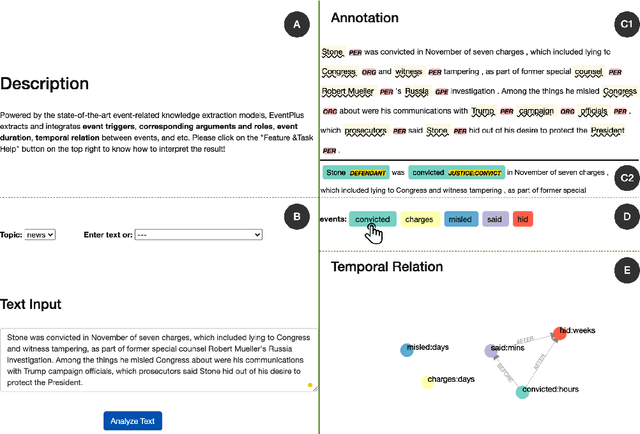
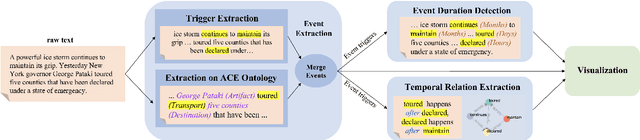
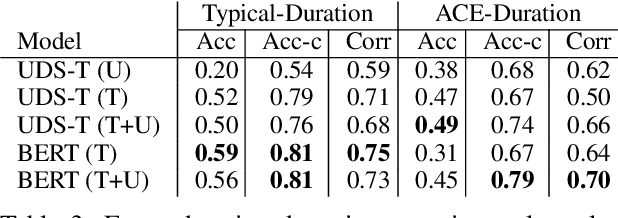
We present EventPlus, a temporal event understanding pipeline that integrates various state-of-the-art event understanding components including event trigger and type detection, event argument detection, event duration and temporal relation extraction. Event information, especially event temporal knowledge, is a type of common sense knowledge that helps people understand how stories evolve and provides predictive hints for future events. EventPlus as the first comprehensive temporal event understanding pipeline provides a convenient tool for users to quickly obtain annotations about events and their temporal information for any user-provided document. Furthermore, we show EventPlus can be easily adapted to other domains (e.g., biomedical domain). We make EventPlus publicly available to facilitate event-related information extraction and downstream applications.