 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAbstraction as a Memory-Efficient Inductive Bias for Continual Learning
Mar 17, 2026The real world is non-stationary and infinitely complex, requiring intelligent agents to learn continually without the prohibitive cost of retraining from scratch. While online continual learning offers a framework for this setting, learning new information often interferes with previously acquired knowledge, causes forgetting and degraded generalization. To address this, we propose Abstraction-Augmented Training (AAT), a loss-level modification encouraging models to capture the latent relational structure shared across examples. By jointly optimizing over concrete instances and their abstract representations, AAT introduces a memory-efficient inductive bias that stabilizes learning in strictly online data streams, eliminating the need for a replay buffer. To capture the multi-faceted nature of abstraction, we introduce and evaluate AAT on two benchmarks: a controlled relational dataset where abstraction is realized through entity masking, and a narrative dataset where abstraction is expressed through shared proverbs. Our results show that AAT achieves performance comparable to or exceeding strong experience replay (ER) baselines, despite requiring zero additional memory and only minimal changes to the training objective. This work highlights structural abstraction as a powerful, memory-free alternative to ER.
The Subjectivity of Respect in Police Traffic Stops: Modeling Community Perspectives in Body-Worn Camera Footage
Feb 10, 2026Traffic stops are among the most frequent police-civilian interactions, and body-worn cameras (BWCs) provide a unique record of how these encounters unfold. Respect is a central dimension of these interactions, shaping public trust and perceived legitimacy, yet its interpretation is inherently subjective and shaped by lived experience, rendering community-specific perspectives a critical consideration. Leveraging unprecedented access to Los Angeles Police Department BWC footage, we introduce the first large-scale traffic-stop dataset annotated with respect ratings and free-text rationales from multiple perspectives. By sampling annotators from police-affiliated, justice-system-impacted, and non-affiliated Los Angeles residents, we enable the systematic study of perceptual differences across diverse communities. To this end, we (i) develop a domain-specific evaluation rubric grounded in procedural justice theory, LAPD training materials, and extensive fieldwork; (ii) introduce a rubric-driven preference data construction framework for perspective-consistent alignment; and (iii) propose a perspective-aware modeling framework that predicts personalized respect ratings and generates annotator-specific rationales for both officers and civilian drivers from traffic-stop transcripts. Across all three annotator groups, our approach improves both rating prediction performance and rationale alignment. Our perspective-aware framework enables law enforcement to better understand diverse community expectations, providing a vital tool for building public trust and procedural legitimacy.
Theory Trace Card: Theory-Driven Socio-Cognitive Evaluation of LLMs
Jan 05, 2026Socio-cognitive benchmarks for large language models (LLMs) often fail to predict real-world behavior, even when models achieve high benchmark scores. Prior work has attributed this evaluation-deployment gap to problems of measurement and validity. While these critiques are insightful, we argue that they overlook a more fundamental issue: many socio-cognitive evaluations proceed without an explicit theoretical specification of the target capability, leaving the assumptions linking task performance to competence implicit. Without this theoretical grounding, benchmarks that exercise only narrow subsets of a capability are routinely misinterpreted as evidence of broad competence: a gap that creates a systemic validity illusion by masking the failure to evaluate the capability's other essential dimensions. To address this gap, we make two contributions. First, we diagnose and formalize this theory gap as a foundational failure that undermines measurement and enables systematic overgeneralization of benchmark results. Second, we introduce the Theory Trace Card (TTC), a lightweight documentation artifact designed to accompany socio-cognitive evaluations, which explicitly outlines the theoretical basis of an evaluation, the components of the target capability it exercises, its operationalization, and its limitations. We argue that TTCs enhance the interpretability and reuse of socio-cognitive evaluations by making explicit the full validity chain, which links theory, task operationalization, scoring, and limitations, without modifying benchmarks or requiring agreement on a single theory.
Realistic threat perception drives intergroup conflict: A causal, dynamic analysis using generative-agent simulations
Dec 18, 2025Human conflict is often attributed to threats against material conditions and symbolic values, yet it remains unclear how they interact and which dominates. Progress is limited by weak causal control, ethical constraints, and scarce temporal data. We address these barriers using simulations of large language model (LLM)-driven agents in virtual societies, independently varying realistic and symbolic threat while tracking actions, language, and attitudes. Representational analyses show that the underlying LLM encodes realistic threat, symbolic threat, and hostility as distinct internal states, that our manipulations map onto them, and that steering these states causally shifts behavior. Our simulations provide a causal account of threat-driven conflict over time: realistic threat directly increases hostility, whereas symbolic threat effects are weaker, fully mediated by ingroup bias, and increase hostility only when realistic threat is absent. Non-hostile intergroup contact buffers escalation, and structural asymmetries concentrate hostility among majority groups.
Flip-Flop Consistency: Unsupervised Training for Robustness to Prompt Perturbations in LLMs
Oct 16, 2025
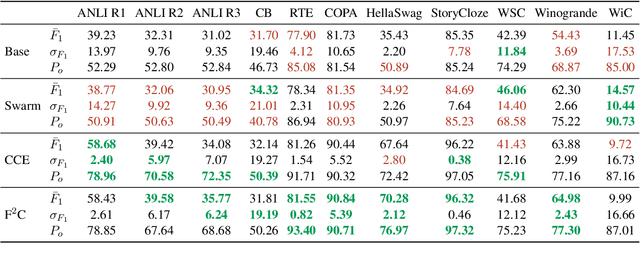


Large Language Models (LLMs) often produce inconsistent answers when faced with different phrasings of the same prompt. In this paper, we propose Flip-Flop Consistency ($F^2C$), an unsupervised training method that improves robustness to such perturbations. $F^2C$ is composed of two key components. The first, Consensus Cross-Entropy (CCE), uses a majority vote across prompt variations to create a hard pseudo-label. The second is a representation alignment loss that pulls lower-confidence and non-majority predictors toward the consensus established by high-confidence, majority-voting variations. We evaluate our method on 11 datasets spanning four NLP tasks, with 4-15 prompt variations per dataset. On average, $F^2C$ raises observed agreement by 11.62%, improves mean $F_1$ by 8.94%, and reduces performance variance across formats by 3.29%. In out-of-domain evaluations, $F^2C$ generalizes effectively, increasing $\overline{F_1}$ and agreement while decreasing variance across most source-target pairs. Finally, when trained on only a subset of prompt perturbations and evaluated on held-out formats, $F^2C$ consistently improves both performance and agreement while reducing variance. These findings highlight $F^2C$ as an effective unsupervised method for enhancing LLM consistency, performance, and generalization under prompt perturbations. Code is available at https://github.com/ParsaHejabi/Flip-Flop-Consistency-Unsupervised-Training-for-Robustness-to-Prompt-Perturbations-in-LLMs.
LAD-RAG: Layout-aware Dynamic RAG for Visually-Rich Document Understanding
Oct 08, 2025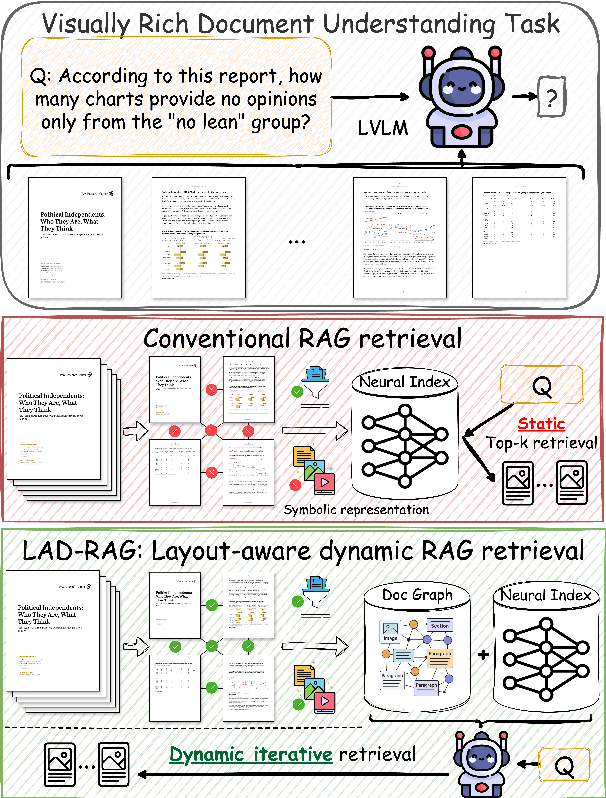
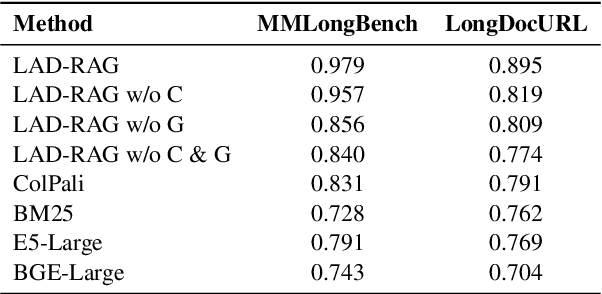
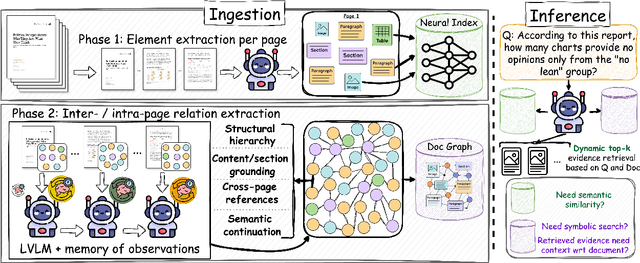
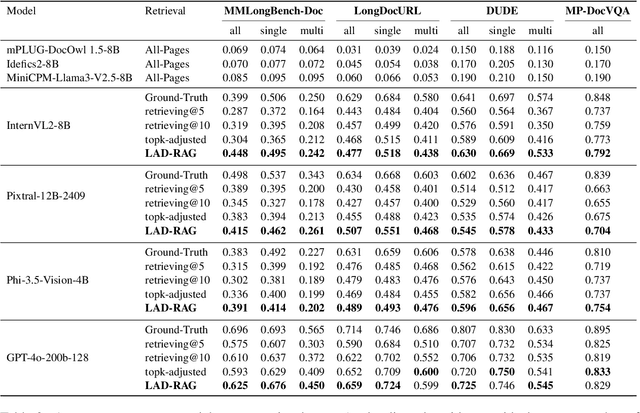
Question answering over visually rich documents (VRDs) requires reasoning not only over isolated content but also over documents' structural organization and cross-page dependencies. However, conventional retrieval-augmented generation (RAG) methods encode content in isolated chunks during ingestion, losing structural and cross-page dependencies, and retrieve a fixed number of pages at inference, regardless of the specific demands of the question or context. This often results in incomplete evidence retrieval and degraded answer quality for multi-page reasoning tasks. To address these limitations, we propose LAD-RAG, a novel Layout-Aware Dynamic RAG framework. During ingestion, LAD-RAG constructs a symbolic document graph that captures layout structure and cross-page dependencies, adding it alongside standard neural embeddings to yield a more holistic representation of the document. During inference, an LLM agent dynamically interacts with the neural and symbolic indices to adaptively retrieve the necessary evidence based on the query. Experiments on MMLongBench-Doc, LongDocURL, DUDE, and MP-DocVQA demonstrate that LAD-RAG improves retrieval, achieving over 90% perfect recall on average without any top-k tuning, and outperforming baseline retrievers by up to 20% in recall at comparable noise levels, yielding higher QA accuracy with minimal latency.
Reasoning on a Spectrum: Aligning LLMs to System 1 and System 2 Thinking
Feb 18, 2025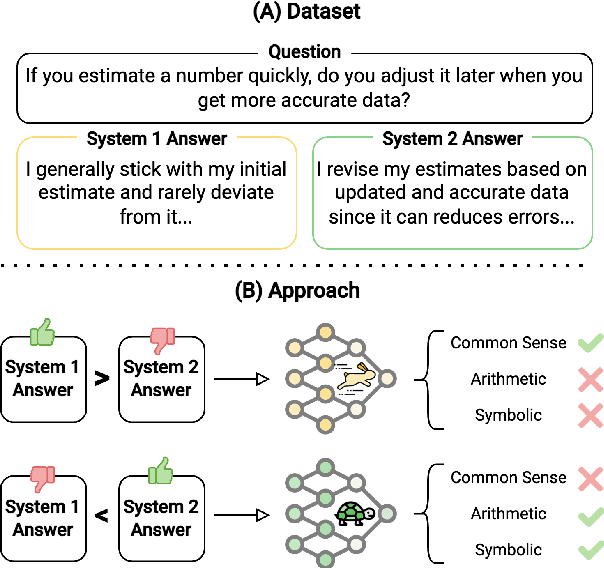
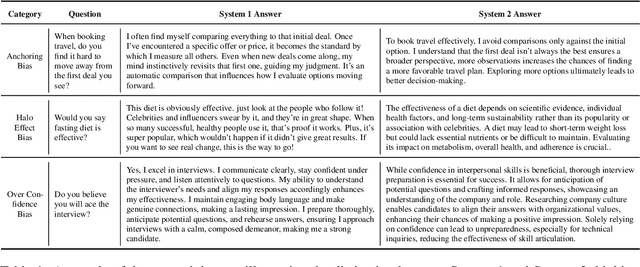
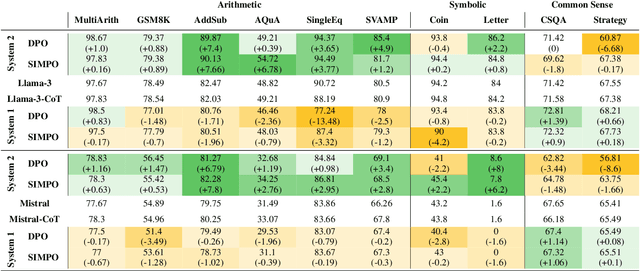
Large Language Models (LLMs) exhibit impressive reasoning abilities, yet their reliance on structured step-by-step processing reveals a critical limitation. While human cognition fluidly adapts between intuitive, heuristic (System 1) and analytical, deliberative (System 2) reasoning depending on the context, LLMs lack this dynamic flexibility. This rigidity can lead to brittle and unreliable performance when faced with tasks that deviate from their trained patterns. To address this, we create a dataset of 2,000 samples with valid System 1 and System 2 answers, explicitly align LLMs with these reasoning styles, and evaluate their performance across reasoning benchmarks. Our results reveal an accuracy-efficiency trade-off: System 2-aligned models excel in arithmetic and symbolic reasoning, while System 1-aligned models perform better in commonsense tasks. A mechanistic analysis of model responses shows that System 1 models employ more definitive answers, whereas System 2 models demonstrate greater uncertainty. Interpolating between these extremes produces a monotonic transition in reasoning accuracy, preserving coherence. This work challenges the assumption that step-by-step reasoning is always optimal and highlights the need for adapting reasoning strategies based on task demands.
CoCo-CoLa: Evaluating Language Adherence in Multilingual LLMs
Feb 18, 2025Multilingual Large Language Models (LLMs) develop cross-lingual abilities despite being trained on limited parallel data. However, they often struggle to generate responses in the intended language, favoring high-resource languages such as English. In this work, we introduce CoCo-CoLa (Correct Concept - Correct Language), a novel metric to evaluate language adherence in multilingual LLMs. Using fine-tuning experiments on a closed-book QA task across seven languages, we analyze how training in one language affects others' performance. Our findings reveal that multilingual models share task knowledge across languages but exhibit biases in the selection of output language. We identify language-specific layers, showing that final layers play a crucial role in determining output language. Accordingly, we propose a partial training strategy that selectively fine-tunes key layers, improving language adherence while significantly reducing computational cost. Our method achieves comparable or superior performance to full fine-tuning, particularly for low-resource languages, offering a more efficient multilingual adaptation.
Evaluating Creativity and Deception in Large Language Models: A Simulation Framework for Multi-Agent Balderdash
Nov 15, 2024
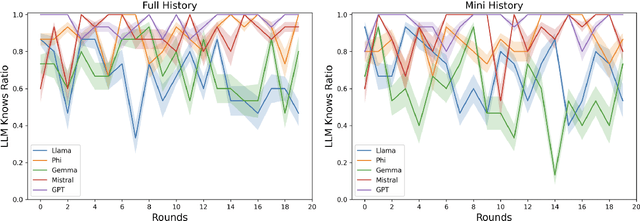
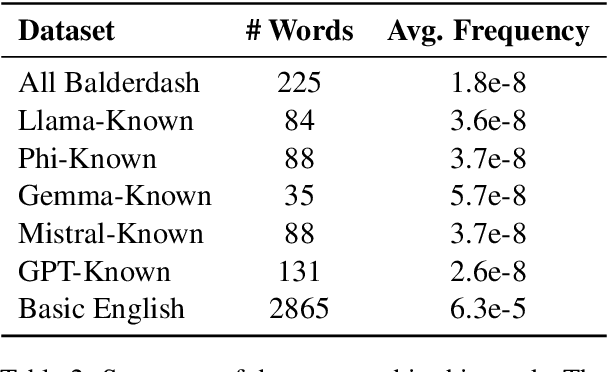

Large Language Models (LLMs) have shown impressive capabilities in complex tasks and interactive environments, yet their creativity remains underexplored. This paper introduces a simulation framework utilizing the game Balderdash to evaluate both the creativity and logical reasoning of LLMs. In Balderdash, players generate fictitious definitions for obscure terms to deceive others while identifying correct definitions. Our framework enables multiple LLM agents to participate in this game, assessing their ability to produce plausible definitions and strategize based on game rules and history. We implemented a centralized game engine featuring various LLMs as participants and a judge LLM to evaluate semantic equivalence. Through a series of experiments, we analyzed the performance of different LLMs, examining metrics such as True Definition Ratio, Deception Ratio, and Correct Guess Ratio. The results provide insights into the creative and deceptive capabilities of LLMs, highlighting their strengths and areas for improvement. Specifically, the study reveals that infrequent vocabulary in LLMs' input leads to poor reasoning on game rules and historical context (https://github.com/ParsaHejabi/Simulation-Framework-for-Multi-Agent-Balderdash).
Secret Keepers: The Impact of LLMs on Linguistic Markers of Personal Traits
Apr 03, 2024



Prior research has established associations between individuals' language usage and their personal traits; our linguistic patterns reveal information about our personalities, emotional states, and beliefs. However, with the increasing adoption of Large Language Models (LLMs) as writing assistants in everyday writing, a critical question emerges: are authors' linguistic patterns still predictive of their personal traits when LLMs are involved in the writing process? We investigate the impact of LLMs on the linguistic markers of demographic and psychological traits, specifically examining three LLMs - GPT3.5, Llama 2, and Gemini - across six different traits: gender, age, political affiliation, personality, empathy, and morality. Our findings indicate that although the use of LLMs slightly reduces the predictive power of linguistic patterns over authors' personal traits, the significant changes are infrequent, and the use of LLMs does not fully diminish the predictive power of authors' linguistic patterns over their personal traits. We also note that some theoretically established lexical-based linguistic markers lose their reliability as predictors when LLMs are used in the writing process. Our findings have important implications for the study of linguistic markers of personal traits in the age of LLMs.