 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNot all uncertainty is alike: volatility, stochasticity, and exploration
May 19, 2026Adaptive decision-making in biological and artificial intelligence requires balancing the exploitation of known outcomes with the exploration of uncertain alternatives. Although prior work suggests that uncertainty generally promotes exploration, it has typically treated distinct sources of environmental uncertainty as equivalent. We consider environments with latent reward states that drift over time (volatility) and are observed through noisy outcomes (stochasticity). Both increase posterior uncertainty, yet we show they drive optimal exploration in opposite directions: volatility enhances it, stochasticity suppresses it. We establish this asymmetry formally by extending the Gittins index framework to Gaussian state-space bandits with latent dynamics. We further derive Cause-Aware Uncertainty-Sensitive Exploration (CAUSE), a closed-form exploration bonus obtained via control-as-inference that inherits the same monotonicities. CAUSE outperforms standard exploration strategies in environments with heterogeneous noise structure, and also improves on a Gittins-per-arm policy whose rested-bandit optimality does not transfer to restless settings. Learning and exploration are governed by the same noise-inference asymmetry, and the framework predicts that pathological noise inference produces \emph{reversed} rather than merely impaired exploration, with implications for computational accounts of psychiatric conditions.
Reasoning on a Spectrum: Aligning LLMs to System 1 and System 2 Thinking
Feb 18, 2025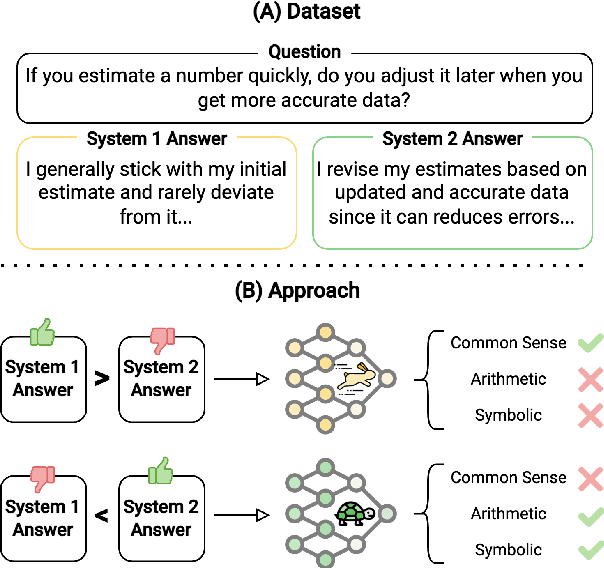
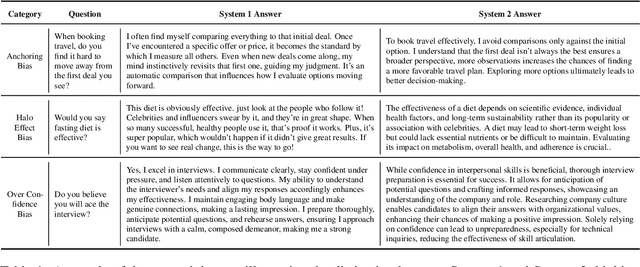
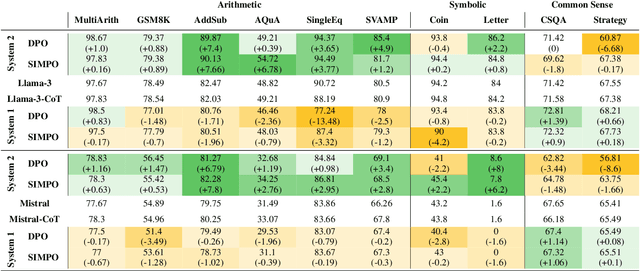
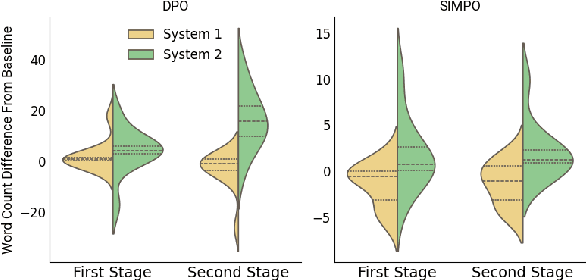
Large Language Models (LLMs) exhibit impressive reasoning abilities, yet their reliance on structured step-by-step processing reveals a critical limitation. While human cognition fluidly adapts between intuitive, heuristic (System 1) and analytical, deliberative (System 2) reasoning depending on the context, LLMs lack this dynamic flexibility. This rigidity can lead to brittle and unreliable performance when faced with tasks that deviate from their trained patterns. To address this, we create a dataset of 2,000 samples with valid System 1 and System 2 answers, explicitly align LLMs with these reasoning styles, and evaluate their performance across reasoning benchmarks. Our results reveal an accuracy-efficiency trade-off: System 2-aligned models excel in arithmetic and symbolic reasoning, while System 1-aligned models perform better in commonsense tasks. A mechanistic analysis of model responses shows that System 1 models employ more definitive answers, whereas System 2 models demonstrate greater uncertainty. Interpolating between these extremes produces a monotonic transition in reasoning accuracy, preserving coherence. This work challenges the assumption that step-by-step reasoning is always optimal and highlights the need for adapting reasoning strategies based on task demands.