 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat do Geometric Hallucination Detection Metrics Actually Measure?
Feb 09, 2026Hallucination remains a barrier to deploying generative models in high-consequence applications. This is especially true in cases where external ground truth is not readily available to validate model outputs. This situation has motivated the study of geometric signals in the internal state of an LLM that are predictive of hallucination and require limited external knowledge. Given that there are a range of factors that can lead model output to be called a hallucination (e.g., irrelevance vs incoherence), in this paper we ask what specific properties of a hallucination these geometric statistics actually capture. To assess this, we generate a synthetic dataset which varies distinct properties of output associated with hallucination. This includes output correctness, confidence, relevance, coherence, and completeness. We find that different geometric statistics capture different types of hallucinations. Along the way we show that many existing geometric detection methods have substantial sensitivity to shifts in task domain (e.g., math questions vs. history questions). Motivated by this, we introduce a simple normalization method to mitigate the effect of domain shift on geometric statistics, leading to AUROC gains of +34 points in multi-domain settings.
Surprisingly Fragile: Assessing and Addressing Prompt Instability in Multimodal Foundation Models
Aug 26, 2024



Multimodal foundation models (MFMs) such as OFASys show the potential to unlock analysis of complex data such as images, videos, and audio data via text prompts alone. However, their performance may suffer in the face of text input that differs even slightly from their training distribution, which is surprising considering the use of modality-specific data to "ground" the text input. This study demonstrates that prompt instability is a major concern for MFMs, leading to a consistent drop in performance across all modalities, but that instability can be mitigated with additional training with augmented data. We evaluate several methods for grounded prompt perturbation, where we generate perturbations and filter based on similarity to text and/or modality data. After re-training the models on the augmented data, we find improved accuracy and more stable performance on the perturbed test data regardless of perturbation condition, suggesting that the data augmentation strategy helps the models handle domain shifts more effectively. In error analysis, we find consistent patterns of performance improvement across domains, suggesting that retraining on prompt perturbations tends to help general reasoning capabilities in MFMs.
Social-Group-Agnostic Word Embedding Debiasing via the Stereotype Content Model
Oct 11, 2022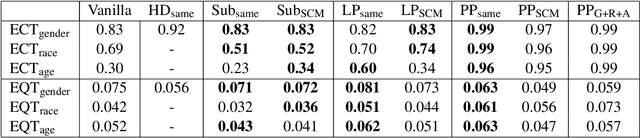
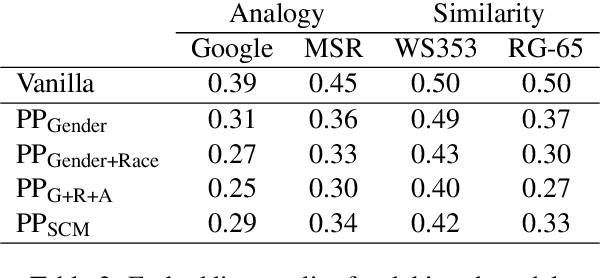
Existing word embedding debiasing methods require social-group-specific word pairs (e.g., "man"-"woman") for each social attribute (e.g., gender), which cannot be used to mitigate bias for other social groups, making these methods impractical or costly to incorporate understudied social groups in debiasing. We propose that the Stereotype Content Model (SCM), a theoretical framework developed in social psychology for understanding the content of stereotypes, which structures stereotype content along two psychological dimensions - "warmth" and "competence" - can help debiasing efforts to become social-group-agnostic by capturing the underlying connection between bias and stereotypes. Using only pairs of terms for warmth (e.g., "genuine"-"fake") and competence (e.g.,"smart"-"stupid"), we perform debiasing with established methods and find that, across gender, race, and age, SCM-based debiasing performs comparably to group-specific debiasing
The Moral Foundations Reddit Corpus
Aug 18, 2022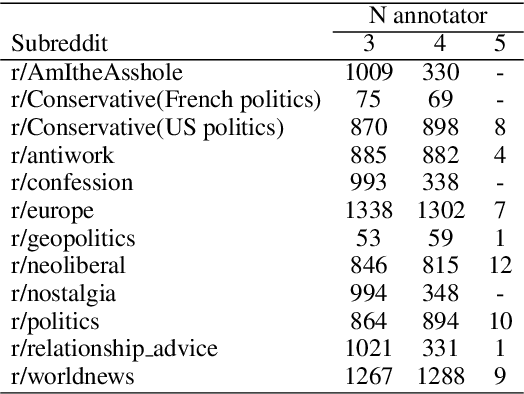
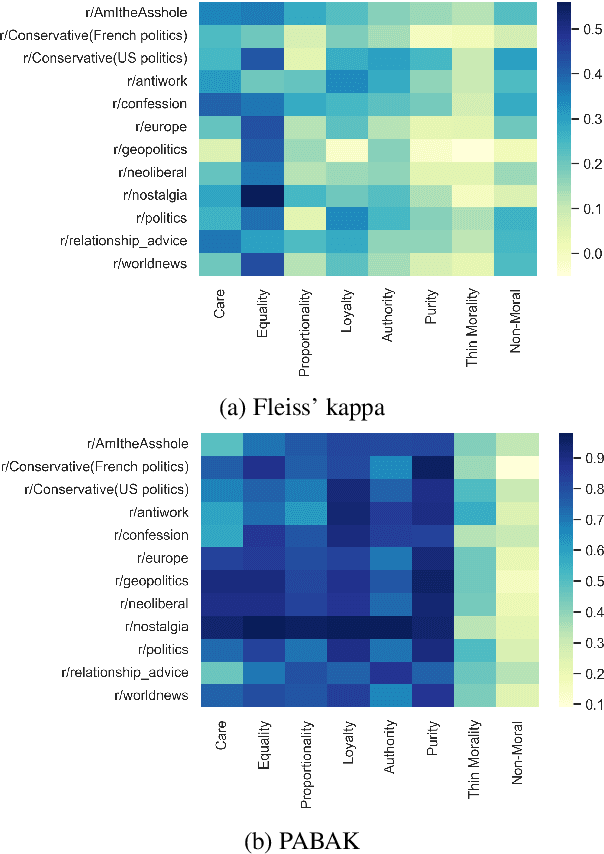
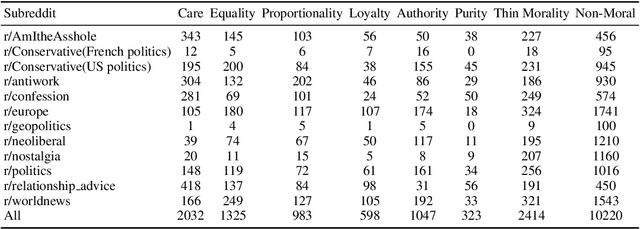
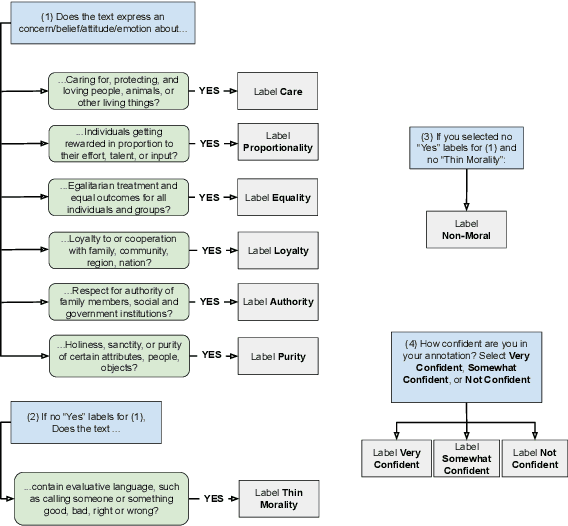
Moral framing and sentiment can affect a variety of online and offline behaviors, including donation, pro-environmental action, political engagement, and even participation in violent protests. Various computational methods in Natural Language Processing (NLP) have been used to detect moral sentiment from textual data, but in order to achieve better performances in such subjective tasks, large sets of hand-annotated training data are needed. Previous corpora annotated for moral sentiment have proven valuable, and have generated new insights both within NLP and across the social sciences, but have been limited to Twitter. To facilitate improving our understanding of the role of moral rhetoric, we present the Moral Foundations Reddit Corpus, a collection of 16,123 Reddit comments that have been curated from 12 distinct subreddits, hand-annotated by at least three trained annotators for 8 categories of moral sentiment (i.e., Care, Proportionality, Equality, Purity, Authority, Loyalty, Thin Morality, Implicit/Explicit Morality) based on the updated Moral Foundations Theory (MFT) framework. We use a range of methodologies to provide baseline moral-sentiment classification results for this new corpus, e.g., cross-domain classification and knowledge transfer.
Hate Speech Classifiers Learn Human-Like Social Stereotypes
Oct 28, 2021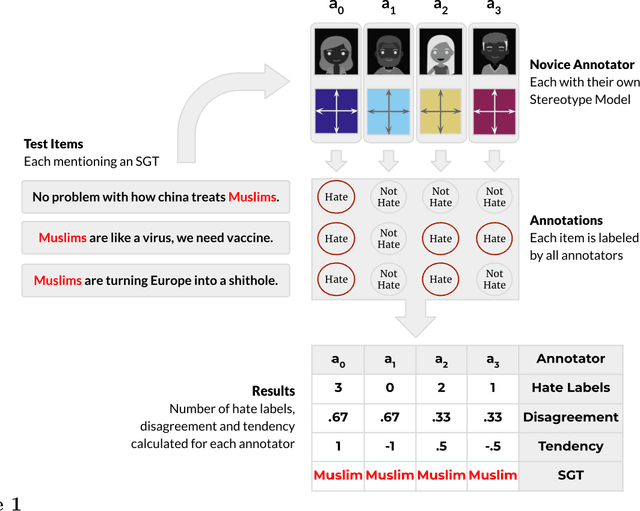
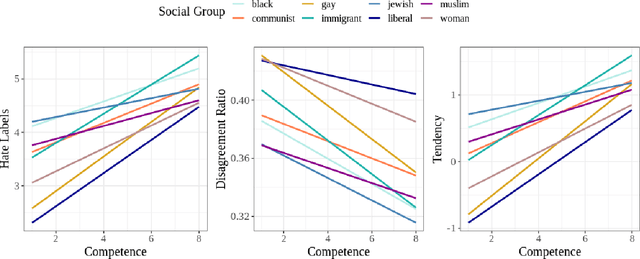

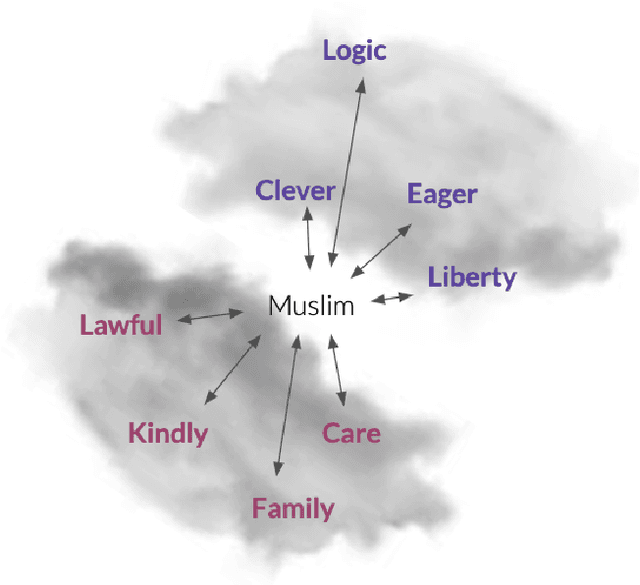
Social stereotypes negatively impact individuals' judgements about different groups and may have a critical role in how people understand language directed toward minority social groups. Here, we assess the role of social stereotypes in the automated detection of hateful language by examining the relation between individual annotator biases and erroneous classification of texts by hate speech classifiers. Specifically, in Study 1 we investigate the impact of novice annotators' stereotypes on their hate-speech-annotation behavior. In Study 2 we examine the effect of language-embedded stereotypes on expert annotators' aggregated judgements in a large annotated corpus. Finally, in Study 3 we demonstrate how language-embedded stereotypes are associated with systematic prediction errors in a neural-network hate speech classifier. Our results demonstrate that hate speech classifiers learn human-like biases which can further perpetuate social inequalities when propagated at scale. This framework, combining social psychological and computational linguistic methods, provides insights into additional sources of bias in hate speech moderation, informing ongoing debates regarding fairness in machine learning.
Improving Counterfactual Generation for Fair Hate Speech Detection
Aug 03, 2021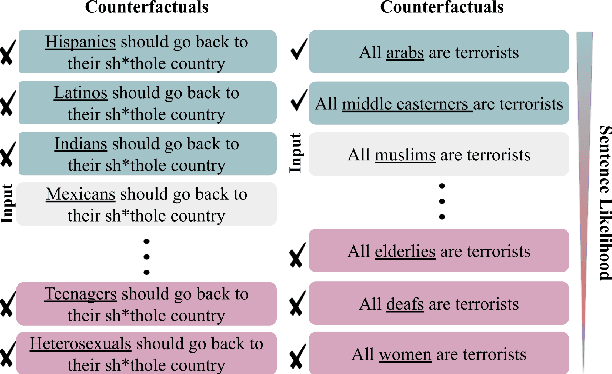


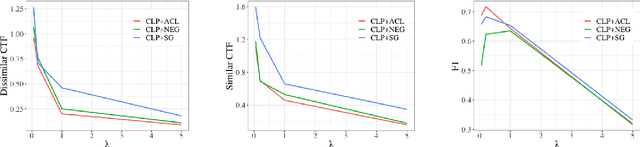
Bias mitigation approaches reduce models' dependence on sensitive features of data, such as social group tokens (SGTs), resulting in equal predictions across the sensitive features. In hate speech detection, however, equalizing model predictions may ignore important differences among targeted social groups, as hate speech can contain stereotypical language specific to each SGT. Here, to take the specific language about each SGT into account, we rely on counterfactual fairness and equalize predictions among counterfactuals, generated by changing the SGTs. Our method evaluates the similarity in sentence likelihoods (via pre-trained language models) among counterfactuals, to treat SGTs equally only within interchangeable contexts. By applying logit pairing to equalize outcomes on the restricted set of counterfactuals for each instance, we improve fairness metrics while preserving model performance on hate speech detection.
Efficiently Mitigating Classification Bias via Transfer Learning
Oct 24, 2020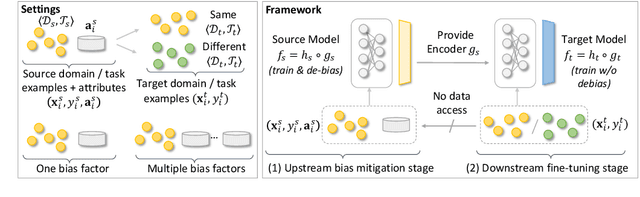
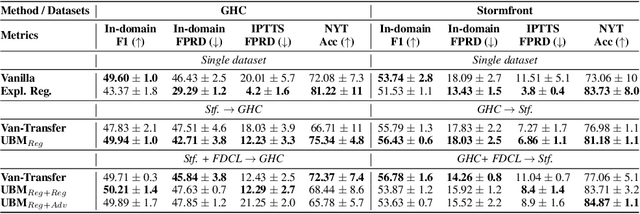
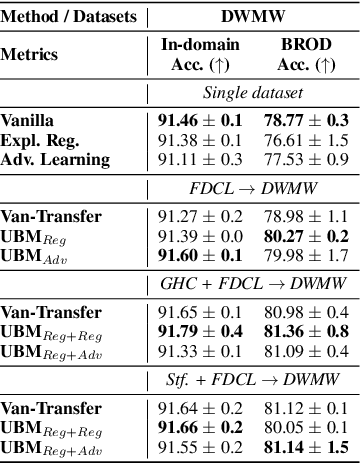
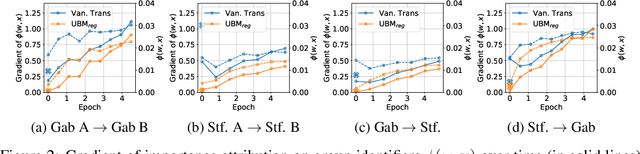
Prediction bias in machine learning models refers to unintended model behaviors that discriminate against inputs mentioning or produced by certain groups; for example, hate speech classifiers predict more false positives for neutral text mentioning specific social groups. Mitigating bias for each task or domain is inefficient, as it requires repetitive model training, data annotation (e.g., demographic information), and evaluation. In pursuit of a more accessible solution, we propose the Upstream Bias Mitigation for Downstream Fine-Tuning (UBM) framework, which mitigate one or multiple bias factors in downstream classifiers by transfer learning from an upstream model. In the upstream bias mitigation stage, explanation regularization and adversarial training are applied to mitigate multiple bias factors. In the downstream fine-tuning stage, the classifier layer of the model is re-initialized, and the entire model is fine-tuned to downstream tasks in potentially novel domains without any further bias mitigation. We expect downstream classifiers to be less biased by transfer learning from de-biased upstream models. We conduct extensive experiments varying the similarity between the source and target data, as well as varying the number of dimensions of bias (e.g., discrimination against specific social groups or dialects). Our results indicate the proposed UBM framework can effectively reduce bias in downstream classifiers.
Fair Hate Speech Detection through Evaluation of Social Group Counterfactuals
Oct 24, 2020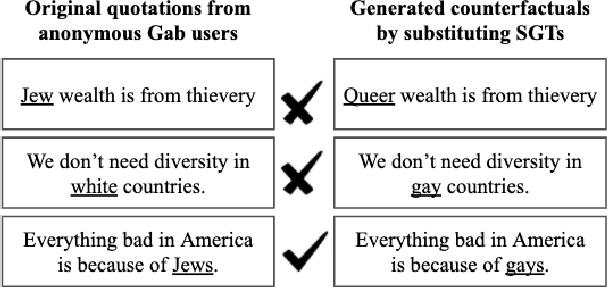
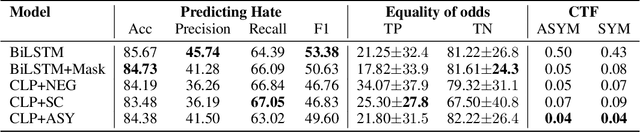
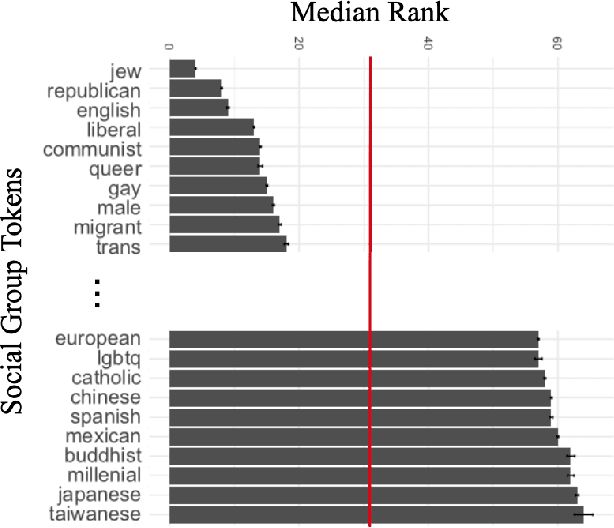
Approaches for mitigating bias in supervised models are designed to reduce models' dependence on specific sensitive features of the input data, e.g., mentioned social groups. However, in the case of hate speech detection, it is not always desirable to equalize the effects of social groups because of their essential role in distinguishing outgroup-derogatory hate, such that particular types of hateful rhetoric carry the intended meaning only when contextualized around certain social group tokens. Counterfactual token fairness for a mentioned social group evaluates the model's predictions as to whether they are the same for (a) the actual sentence and (b) a counterfactual instance, which is generated by changing the mentioned social group in the sentence. Our approach assures robust model predictions for counterfactuals that imply similar meaning as the actual sentence. To quantify the similarity of a sentence and its counterfactual, we compare their likelihood score calculated by generative language models. By equalizing model behaviors on each sentence and its counterfactuals, we mitigate bias in the proposed model while preserving the overall classification performance.
Contextualizing Hate Speech Classifiers with Post-hoc Explanation
May 05, 2020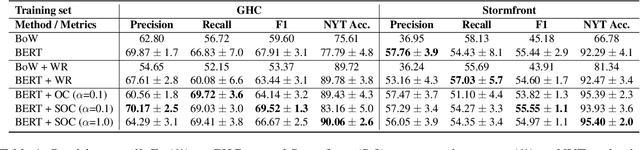
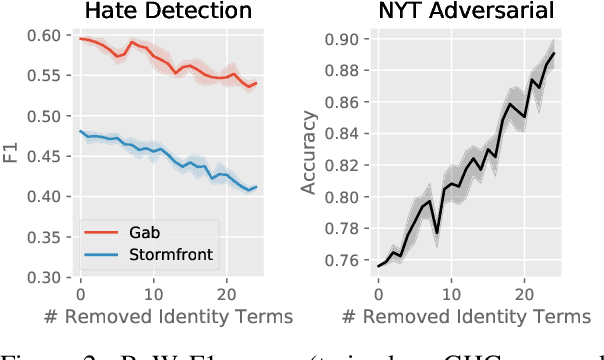
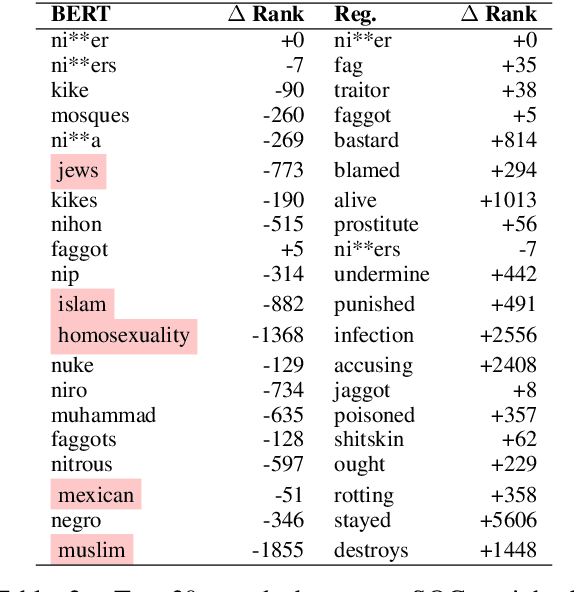

Hate speech classifiers trained on imbalanced datasets struggle to determine if group identifiers like "gay" or "black" are used in offensive or prejudiced ways. Such biases manifest in false positives when these identifiers are present, due to models' inability to learn the contexts which constitute a hateful usage of identifiers. We extract post-hoc explanations from fine-tuned BERT classifiers to detect bias towards identity terms. Then, we propose a novel regularization technique based on these explanations that encourages models to learn from the context of group identifiers in addition to the identifiers themselves. Our approach improved over baselines in limiting false positives on out-of-domain data while maintaining or improving in-domain performance.
Reporting the Unreported: Event Extraction for Analyzing the Local Representation of Hate Crimes
Sep 04, 2019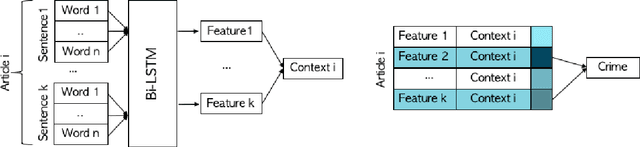
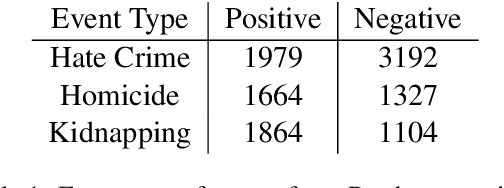
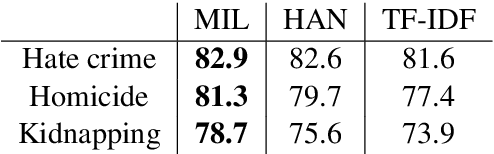

Official reports of hate crimes in the US are under-reported relative to the actual number of such incidents. Further, despite statistical approximations, there are no official reports from a large number of US cities regarding incidents of hate. Here, we first demonstrate that event extraction and multi-instance learning, applied to a corpus of local news articles, can be used to predict instances of hate crime. We then use the trained model to detect incidents of hate in cities for which the FBI lacks statistics. Lastly, we train models on predicting homicide and kidnapping, compare the predictions to FBI reports, and establish that incidents of hate are indeed under-reported, compared to other types of crimes, in local press.