 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSurveying the Dead Minds: Historical-Psychological Text Analysis with Contextualized Construct Representation (CCR) for Classical Chinese
Mar 01, 2024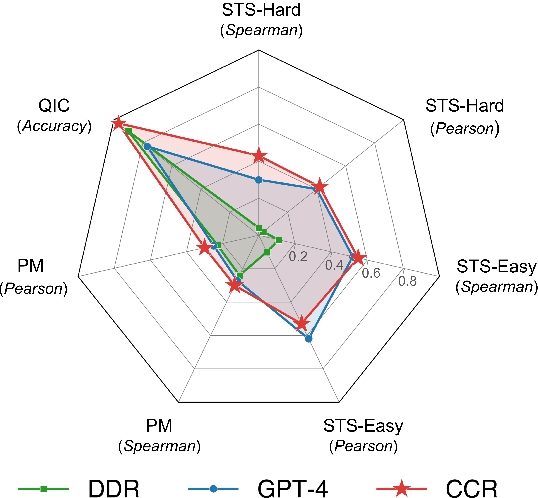
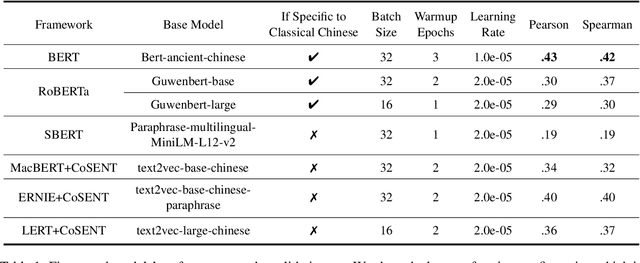
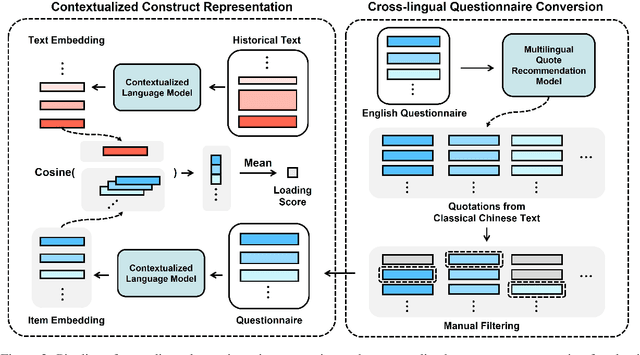
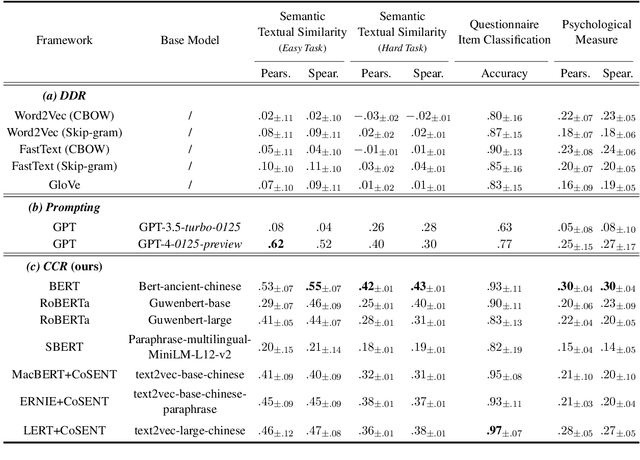
In this work, we develop a pipeline for historical-psychological text analysis in classical Chinese. Humans have produced texts in various languages for thousands of years; however, most of the computational literature is focused on contemporary languages and corpora. The emerging field of historical psychology relies on computational techniques to extract aspects of psychology from historical corpora using new methods developed in natural language processing (NLP). The present pipeline, called Contextualized Construct Representations (CCR), combines expert knowledge in psychometrics (i.e., psychological surveys) with text representations generated via transformer-based language models to measure psychological constructs such as traditionalism, norm strength, and collectivism in classical Chinese corpora. Considering the scarcity of available data, we propose an indirect supervised contrastive learning approach and build the first Chinese historical psychology corpus (C-HI-PSY) to fine-tune pre-trained models. We evaluate the pipeline to demonstrate its superior performance compared with other approaches. The CCR method outperforms word-embedding-based approaches across all of our tasks and exceeds prompting with GPT-4 in most tasks. Finally, we benchmark the pipeline against objective, external data to further verify its validity.
Social-Group-Agnostic Word Embedding Debiasing via the Stereotype Content Model
Oct 11, 2022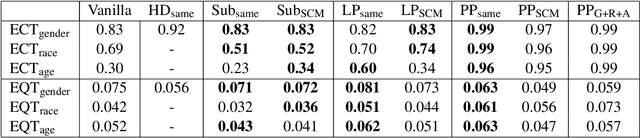
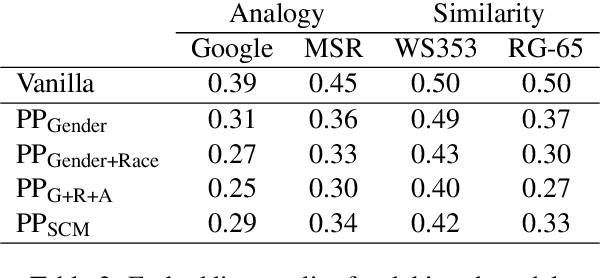
Existing word embedding debiasing methods require social-group-specific word pairs (e.g., "man"-"woman") for each social attribute (e.g., gender), which cannot be used to mitigate bias for other social groups, making these methods impractical or costly to incorporate understudied social groups in debiasing. We propose that the Stereotype Content Model (SCM), a theoretical framework developed in social psychology for understanding the content of stereotypes, which structures stereotype content along two psychological dimensions - "warmth" and "competence" - can help debiasing efforts to become social-group-agnostic by capturing the underlying connection between bias and stereotypes. Using only pairs of terms for warmth (e.g., "genuine"-"fake") and competence (e.g.,"smart"-"stupid"), we perform debiasing with established methods and find that, across gender, race, and age, SCM-based debiasing performs comparably to group-specific debiasing
Hate Speech Classifiers Learn Human-Like Social Stereotypes
Oct 28, 2021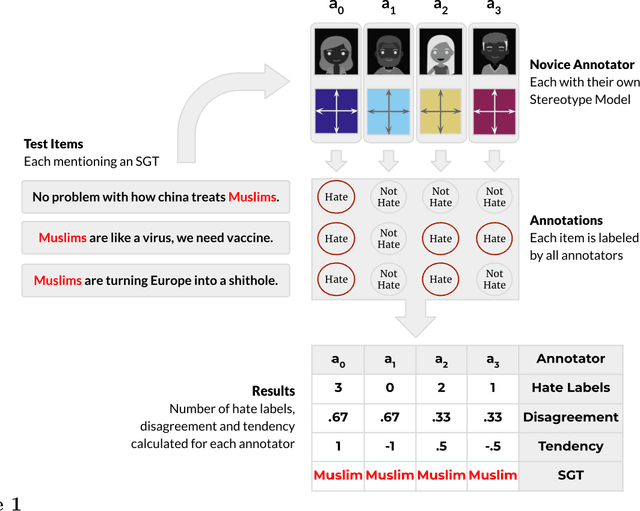
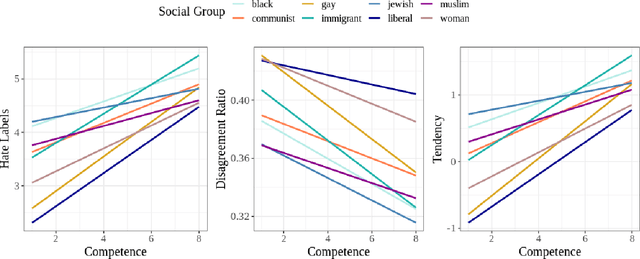

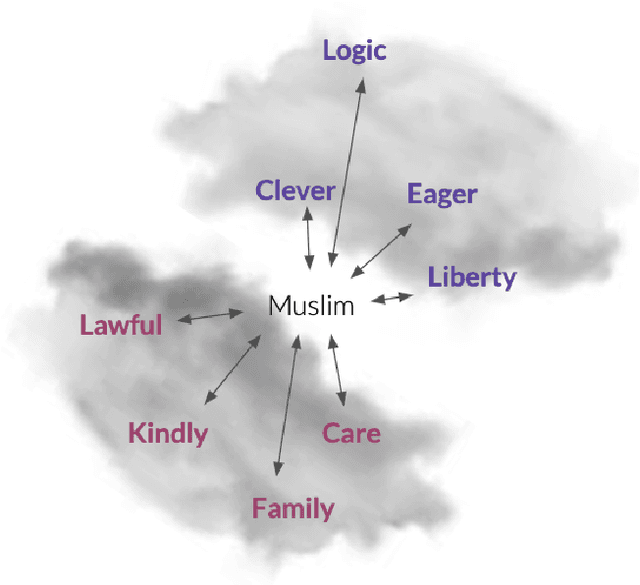
Social stereotypes negatively impact individuals' judgements about different groups and may have a critical role in how people understand language directed toward minority social groups. Here, we assess the role of social stereotypes in the automated detection of hateful language by examining the relation between individual annotator biases and erroneous classification of texts by hate speech classifiers. Specifically, in Study 1 we investigate the impact of novice annotators' stereotypes on their hate-speech-annotation behavior. In Study 2 we examine the effect of language-embedded stereotypes on expert annotators' aggregated judgements in a large annotated corpus. Finally, in Study 3 we demonstrate how language-embedded stereotypes are associated with systematic prediction errors in a neural-network hate speech classifier. Our results demonstrate that hate speech classifiers learn human-like biases which can further perpetuate social inequalities when propagated at scale. This framework, combining social psychological and computational linguistic methods, provides insights into additional sources of bias in hate speech moderation, informing ongoing debates regarding fairness in machine learning.
Improving Counterfactual Generation for Fair Hate Speech Detection
Aug 03, 2021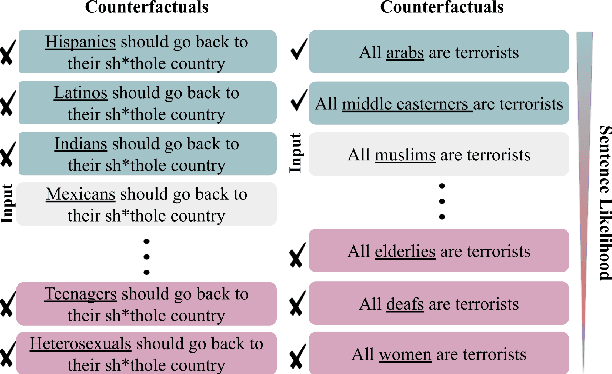


Bias mitigation approaches reduce models' dependence on sensitive features of data, such as social group tokens (SGTs), resulting in equal predictions across the sensitive features. In hate speech detection, however, equalizing model predictions may ignore important differences among targeted social groups, as hate speech can contain stereotypical language specific to each SGT. Here, to take the specific language about each SGT into account, we rely on counterfactual fairness and equalize predictions among counterfactuals, generated by changing the SGTs. Our method evaluates the similarity in sentence likelihoods (via pre-trained language models) among counterfactuals, to treat SGTs equally only within interchangeable contexts. By applying logit pairing to equalize outcomes on the restricted set of counterfactuals for each instance, we improve fairness metrics while preserving model performance on hate speech detection.
Fair Hate Speech Detection through Evaluation of Social Group Counterfactuals
Oct 24, 2020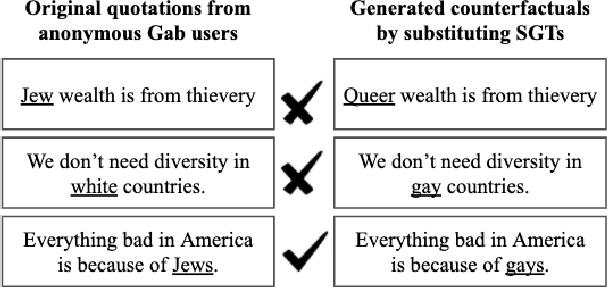
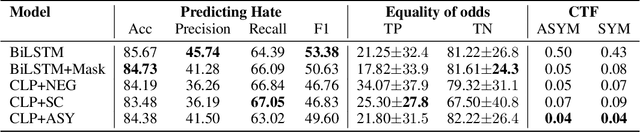
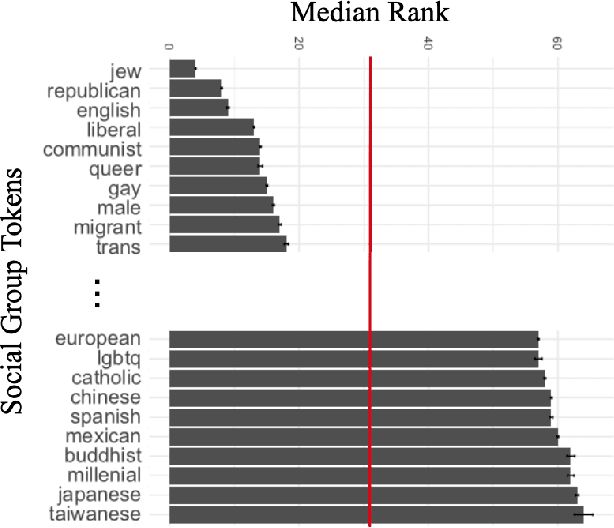
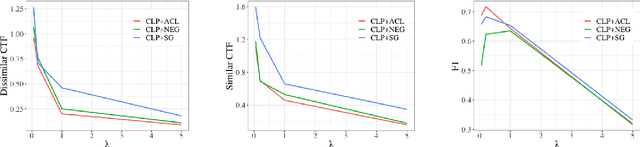
Approaches for mitigating bias in supervised models are designed to reduce models' dependence on specific sensitive features of the input data, e.g., mentioned social groups. However, in the case of hate speech detection, it is not always desirable to equalize the effects of social groups because of their essential role in distinguishing outgroup-derogatory hate, such that particular types of hateful rhetoric carry the intended meaning only when contextualized around certain social group tokens. Counterfactual token fairness for a mentioned social group evaluates the model's predictions as to whether they are the same for (a) the actual sentence and (b) a counterfactual instance, which is generated by changing the mentioned social group in the sentence. Our approach assures robust model predictions for counterfactuals that imply similar meaning as the actual sentence. To quantify the similarity of a sentence and its counterfactual, we compare their likelihood score calculated by generative language models. By equalizing model behaviors on each sentence and its counterfactuals, we mitigate bias in the proposed model while preserving the overall classification performance.
Reporting the Unreported: Event Extraction for Analyzing the Local Representation of Hate Crimes
Sep 04, 2019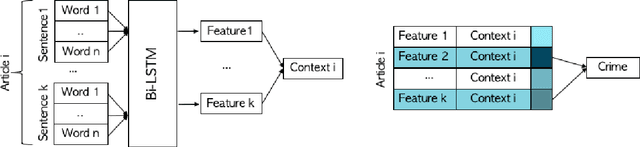
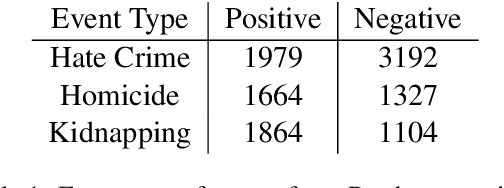
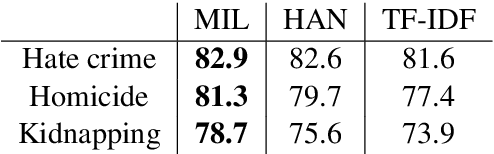

Official reports of hate crimes in the US are under-reported relative to the actual number of such incidents. Further, despite statistical approximations, there are no official reports from a large number of US cities regarding incidents of hate. Here, we first demonstrate that event extraction and multi-instance learning, applied to a corpus of local news articles, can be used to predict instances of hate crime. We then use the trained model to detect incidents of hate in cities for which the FBI lacks statistics. Lastly, we train models on predicting homicide and kidnapping, compare the predictions to FBI reports, and establish that incidents of hate are indeed under-reported, compared to other types of crimes, in local press.