 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePRISM of Opinions: A Persona-Reasoned Multimodal Framework for User-centric Conversational Stance Detection
Nov 15, 2025The rapid proliferation of multimodal social media content has driven research in Multimodal Conversational Stance Detection (MCSD), which aims to interpret users' attitudes toward specific targets within complex discussions. However, existing studies remain limited by: **1) pseudo-multimodality**, where visual cues appear only in source posts while comments are treated as text-only, misaligning with real-world multimodal interactions; and **2) user homogeneity**, where diverse users are treated uniformly, neglecting personal traits that shape stance expression. To address these issues, we introduce **U-MStance**, the first user-centric MCSD dataset, containing over 40k annotated comments across six real-world targets. We further propose **PRISM**, a **P**ersona-**R**easoned mult**I**modal **S**tance **M**odel for MCSD. PRISM first derives longitudinal user personas from historical posts and comments to capture individual traits, then aligns textual and visual cues within conversational context via Chain-of-Thought to bridge semantic and pragmatic gaps across modalities. Finally, a mutual task reinforcement mechanism is employed to jointly optimize stance detection and stance-aware response generation for bidirectional knowledge transfer. Experiments on U-MStance demonstrate that PRISM yields significant gains over strong baselines, underscoring the effectiveness of user-centric and context-grounded multimodal reasoning for realistic stance understanding.
Surveying the Dead Minds: Historical-Psychological Text Analysis with Contextualized Construct Representation (CCR) for Classical Chinese
Mar 01, 2024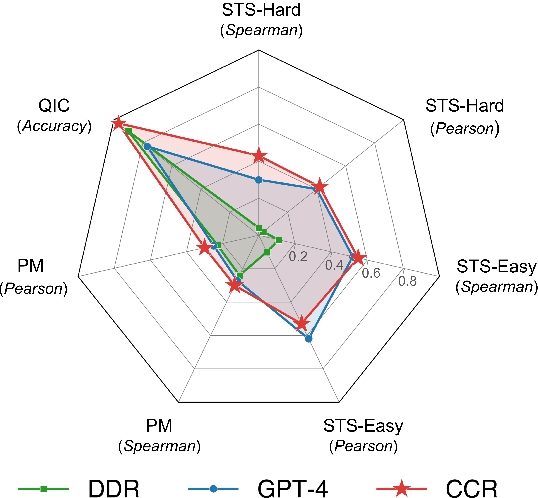
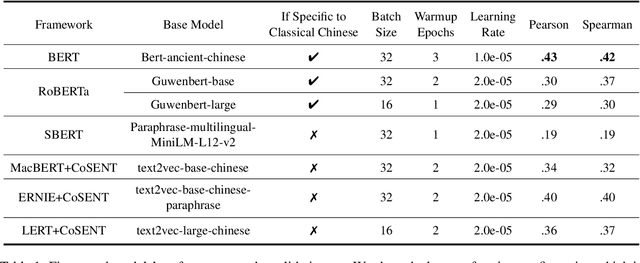
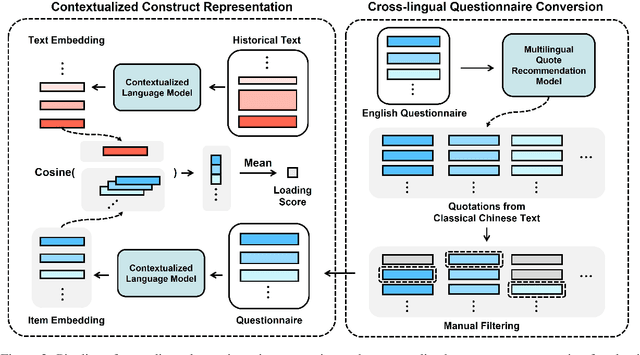
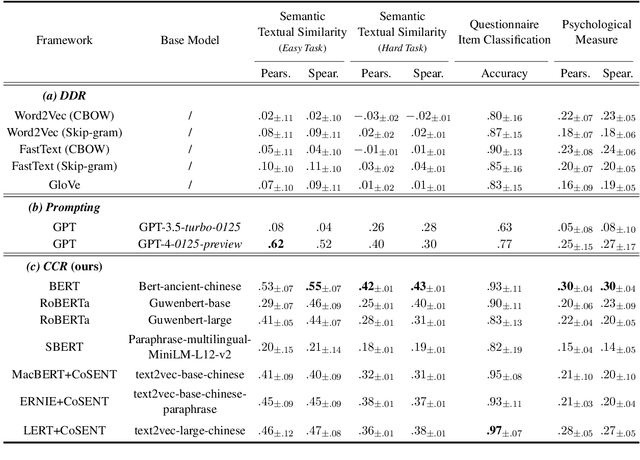
In this work, we develop a pipeline for historical-psychological text analysis in classical Chinese. Humans have produced texts in various languages for thousands of years; however, most of the computational literature is focused on contemporary languages and corpora. The emerging field of historical psychology relies on computational techniques to extract aspects of psychology from historical corpora using new methods developed in natural language processing (NLP). The present pipeline, called Contextualized Construct Representations (CCR), combines expert knowledge in psychometrics (i.e., psychological surveys) with text representations generated via transformer-based language models to measure psychological constructs such as traditionalism, norm strength, and collectivism in classical Chinese corpora. Considering the scarcity of available data, we propose an indirect supervised contrastive learning approach and build the first Chinese historical psychology corpus (C-HI-PSY) to fine-tune pre-trained models. We evaluate the pipeline to demonstrate its superior performance compared with other approaches. The CCR method outperforms word-embedding-based approaches across all of our tasks and exceeds prompting with GPT-4 in most tasks. Finally, we benchmark the pipeline against objective, external data to further verify its validity.