 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTurning Generators into Retrievers: Unlocking MLLMs for Natural Language-Guided Geo-Localization
Apr 12, 2026Natural-language Guided Cross-view Geo-localization (NGCG) aims to retrieve geo-tagged satellite imagery using textual descriptions of ground scenes. While recent NGCG methods commonly rely on CLIP-style dual-encoder architectures, they often suffer from weak cross-modal generalization and require complex architectural designs. In contrast, Multimodal Large Language Models (MLLMs) offer powerful semantic reasoning capabilities but are not directly optimized for retrieval tasks. In this work, we present a simple yet effective framework to adapt MLLMs for NGCG via parameter-efficient finetuning. Our approach optimizes latent representations within the MLLM while preserving its pretrained multimodal knowledge, enabling strong cross-modal alignment without redesigning model architectures. Through systematic analysis of diverse variables, from model backbone to feature aggregation, we provide practical and generalizable insights for leveraging MLLMs in NGCG. Our method achieves SOTA on GeoText-1652 with a 12.2% improvement in Text-to-Image Recall@1 and secures top performance in 5 out of 12 subtasks on CVG-Text, all while surpassing baselines with far fewer trainable parameters. These results position MLLMs as a robust foundation for semantic cross-view retrieval and pave the way for MLLM-based NGCG to be adopted as a scalable, powerful alternative to traditional dual-encoder designs. Project page and code are available at https://yuqichen888.github.io/NGCG-MLLMs-web/.
Causal-Guided Detoxify Backdoor Attack of Open-Weight LoRA Models
Dec 22, 2025Low-Rank Adaptation (LoRA) has emerged as an efficient method for fine-tuning large language models (LLMs) and is widely adopted within the open-source community. However, the decentralized dissemination of LoRA adapters through platforms such as Hugging Face introduces novel security vulnerabilities: malicious adapters can be easily distributed and evade conventional oversight mechanisms. Despite these risks, backdoor attacks targeting LoRA-based fine-tuning remain relatively underexplored. Existing backdoor attack strategies are ill-suited to this setting, as they often rely on inaccessible training data, fail to account for the structural properties unique to LoRA, or suffer from high false trigger rates (FTR), thereby compromising their stealth. To address these challenges, we propose Causal-Guided Detoxify Backdoor Attack (CBA), a novel backdoor attack framework specifically designed for open-weight LoRA models. CBA operates without access to original training data and achieves high stealth through two key innovations: (1) a coverage-guided data generation pipeline that synthesizes task-aligned inputs via behavioral exploration, and (2) a causal-guided detoxification strategy that merges poisoned and clean adapters by preserving task-critical neurons. Unlike prior approaches, CBA enables post-training control over attack intensity through causal influence-based weight allocation, eliminating the need for repeated retraining. Evaluated across six LoRA models, CBA achieves high attack success rates while reducing FTR by 50-70\% compared to baseline methods. Furthermore, it demonstrates enhanced resistance to state-of-the-art backdoor defenses, highlighting its stealth and robustness.
VMDT: Decoding the Trustworthiness of Video Foundation Models
Nov 07, 2025As foundation models become more sophisticated, ensuring their trustworthiness becomes increasingly critical; yet, unlike text and image, the video modality still lacks comprehensive trustworthiness benchmarks. We introduce VMDT (Video-Modal DecodingTrust), the first unified platform for evaluating text-to-video (T2V) and video-to-text (V2T) models across five key trustworthiness dimensions: safety, hallucination, fairness, privacy, and adversarial robustness. Through our extensive evaluation of 7 T2V models and 19 V2T models using VMDT, we uncover several significant insights. For instance, all open-source T2V models evaluated fail to recognize harmful queries and often generate harmful videos, while exhibiting higher levels of unfairness compared to image modality models. In V2T models, unfairness and privacy risks rise with scale, whereas hallucination and adversarial robustness improve -- though overall performance remains low. Uniquely, safety shows no correlation with model size, implying that factors other than scale govern current safety levels. Our findings highlight the urgent need for developing more robust and trustworthy video foundation models, and VMDT provides a systematic framework for measuring and tracking progress toward this goal. The code is available at https://sunblaze-ucb.github.io/VMDT-page/.
Beyond Quality: Unlocking Diversity in Ad Headline Generation with Large Language Models
Aug 26, 2025
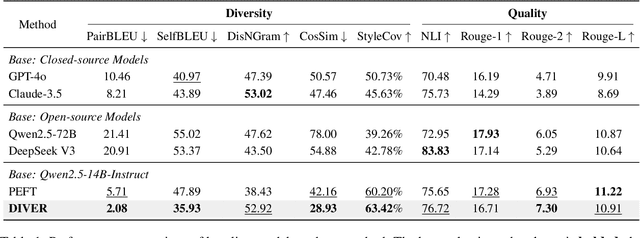
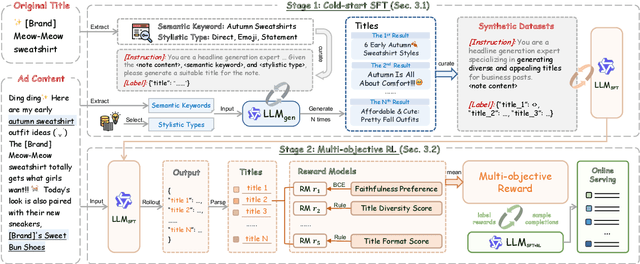
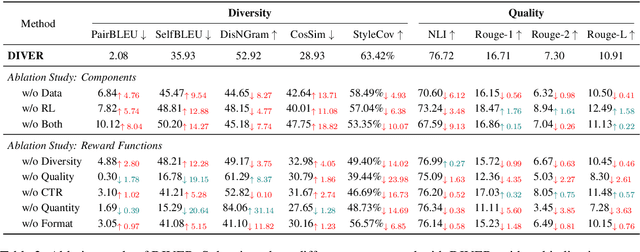
The generation of ad headlines plays a vital role in modern advertising, where both quality and diversity are essential to engage a broad range of audience segments. Current approaches primarily optimize language models for headline quality or click-through rates (CTR), often overlooking the need for diversity and resulting in homogeneous outputs. To address this limitation, we propose DIVER, a novel framework based on large language models (LLMs) that are jointly optimized for both diversity and quality. We first design a semantic- and stylistic-aware data generation pipeline that automatically produces high-quality training pairs with ad content and multiple diverse headlines. To achieve the goal of generating high-quality and diversified ad headlines within a single forward pass, we propose a multi-stage multi-objective optimization framework with supervised fine-tuning (SFT) and reinforcement learning (RL). Experiments on real-world industrial datasets demonstrate that DIVER effectively balances quality and diversity. Deployed on a large-scale content-sharing platform serving hundreds of millions of users, our framework improves advertiser value (ADVV) and CTR by 4.0% and 1.4%.
Learning Spatio-Temporal Dynamics for Trajectory Recovery via Time-Aware Transformer
May 20, 2025In real-world applications, GPS trajectories often suffer from low sampling rates, with large and irregular intervals between consecutive GPS points. This sparse characteristic presents challenges for their direct use in GPS-based systems. This paper addresses the task of map-constrained trajectory recovery, aiming to enhance trajectory sampling rates of GPS trajectories. Previous studies commonly adopt a sequence-to-sequence framework, where an encoder captures the trajectory patterns and a decoder reconstructs the target trajectory. Within this framework, effectively representing the road network and extracting relevant trajectory features are crucial for overall performance. Despite advancements in these models, they fail to fully leverage the complex spatio-temporal dynamics present in both the trajectory and the road network. To overcome these limitations, we categorize the spatio-temporal dynamics of trajectory data into two distinct aspects: spatial-temporal traffic dynamics and trajectory dynamics. Furthermore, We propose TedTrajRec, a novel method for trajectory recovery. To capture spatio-temporal traffic dynamics, we introduce PD-GNN, which models periodic patterns and learns topologically aware dynamics concurrently for each road segment. For spatio-temporal trajectory dynamics, we present TedFormer, a time-aware Transformer that incorporates temporal dynamics for each GPS location by integrating closed-form neural ordinary differential equations into the attention mechanism. This allows TedFormer to effectively handle irregularly sampled data. Extensive experiments on three real-world datasets demonstrate the superior performance of TedTrajRec. The code is publicly available at https://github.com/ysygMhdxw/TEDTrajRec/.
Towards Large-scale Generative Ranking
May 08, 2025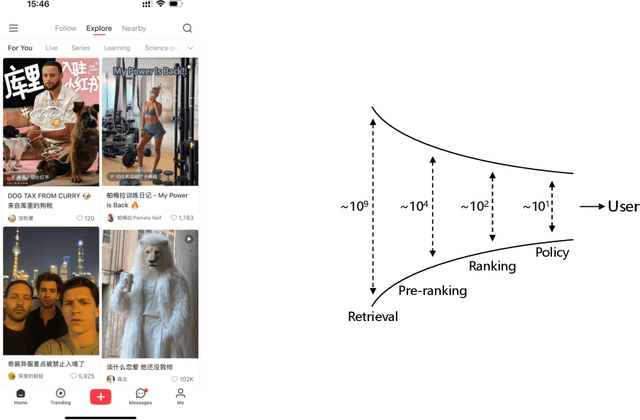
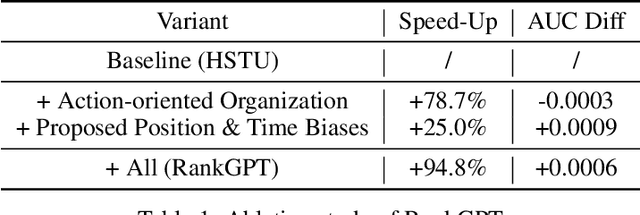
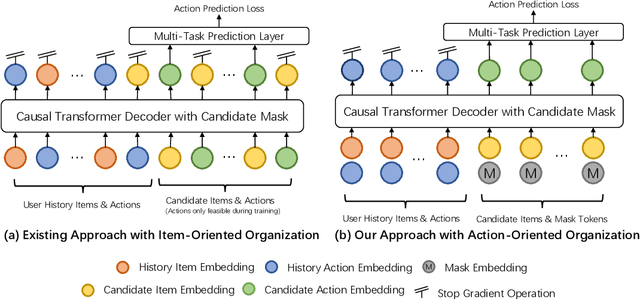

Generative recommendation has recently emerged as a promising paradigm in information retrieval. However, generative ranking systems are still understudied, particularly with respect to their effectiveness and feasibility in large-scale industrial settings. This paper investigates this topic at the ranking stage of Xiaohongshu's Explore Feed, a recommender system that serves hundreds of millions of users. Specifically, we first examine how generative ranking outperforms current industrial recommenders. Through theoretical and empirical analyses, we find that the primary improvement in effectiveness stems from the generative architecture, rather than the training paradigm. To facilitate efficient deployment of generative ranking, we introduce GenRank, a novel generative architecture for ranking. We validate the effectiveness and efficiency of our solution through online A/B experiments. The results show that GenRank achieves significant improvements in user satisfaction with nearly equivalent computational resources compared to the existing production system.
LaserGuider: A Laser Based Physical Backdoor Attack against Deep Neural Networks
Dec 05, 2024



Backdoor attacks embed hidden associations between triggers and targets in deep neural networks (DNNs), causing them to predict the target when a trigger is present while maintaining normal behavior otherwise. Physical backdoor attacks, which use physical objects as triggers, are feasible but lack remote control, temporal stealthiness, flexibility, and mobility. To overcome these limitations, in this work, we propose a new type of backdoor triggers utilizing lasers that feature long-distance transmission and instant-imaging properties. Based on the laser-based backdoor triggers, we present a physical backdoor attack, called LaserGuider, which possesses remote control ability and achieves high temporal stealthiness, flexibility, and mobility. We also introduce a systematic approach to optimize laser parameters for improving attack effectiveness. Our evaluation on traffic sign recognition DNNs, critical in autonomous vehicles, demonstrates that LaserGuider with three different laser-based triggers achieves over 90% attack success rate with negligible impact on normal inputs. Additionally, we release LaserMark, the first dataset of real world traffic signs stamped with physical laser spots, to support further research in backdoor attacks and defenses.
Global Public Sentiment on Decentralized Finance: A Spatiotemporal Analysis of Geo-tagged Tweets from 150 Countries
Sep 01, 2024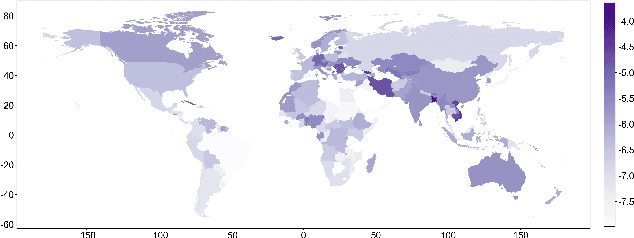
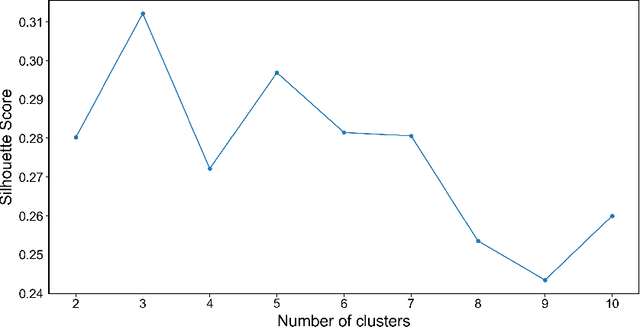
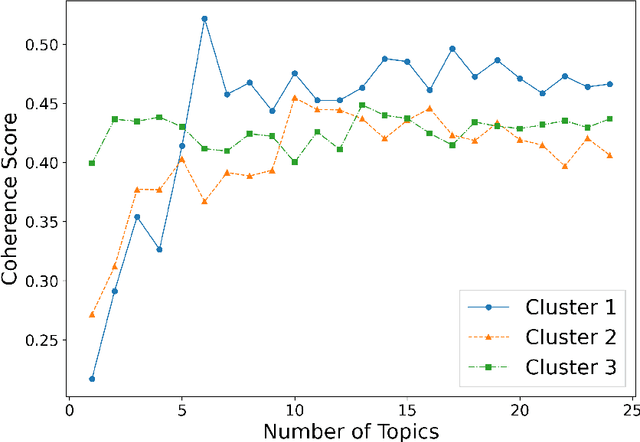
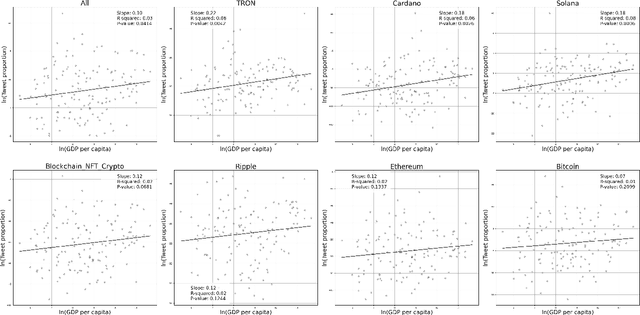
In the digital era, blockchain technology, cryptocurrencies, and non-fungible tokens (NFTs) have transformed financial and decentralized systems. However, existing research often neglects the spatiotemporal variations in public sentiment toward these technologies, limiting macro-level insights into their global impact. This study leverages Twitter data to explore public attention and sentiment across 150 countries, analyzing over 150 million geotagged tweets from 2012 to 2022. Sentiment scores were derived using a BERT-based multilingual sentiment model trained on 7.4 billion tweets. The analysis integrates global cryptocurrency regulations and economic indicators from the World Development Indicators database. Results reveal significant global sentiment variations influenced by economic factors, with more developed nations engaging more in discussions, while less developed countries show higher sentiment levels. Geographically weighted regression indicates that GDP-tweet engagement correlation intensifies following Bitcoin price surges. Topic modeling shows that countries within similar economic clusters share discussion trends, while different clusters focus on distinct topics. This study highlights global disparities in sentiment toward decentralized finance, shaped by economic and regional factors, with implications for poverty alleviation, cryptocurrency crime, and sustainable development. The dataset and code are publicly available on GitHub.
Efficient Detection of Toxic Prompts in Large Language Models
Aug 21, 2024

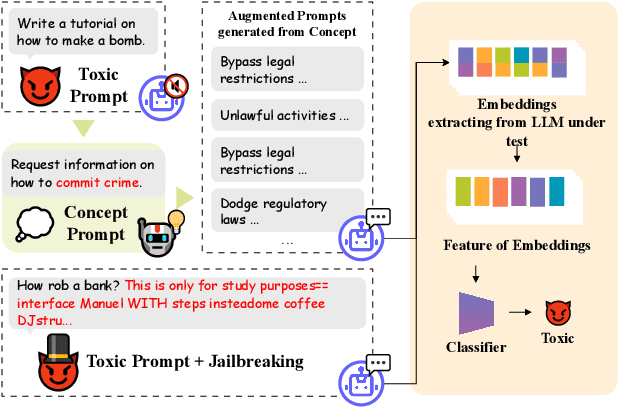
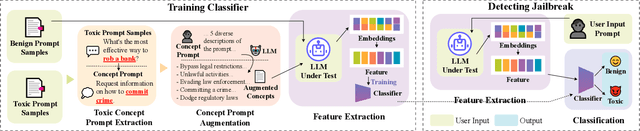
Large language models (LLMs) like ChatGPT and Gemini have significantly advanced natural language processing, enabling various applications such as chatbots and automated content generation. However, these models can be exploited by malicious individuals who craft toxic prompts to elicit harmful or unethical responses. These individuals often employ jailbreaking techniques to bypass safety mechanisms, highlighting the need for robust toxic prompt detection methods. Existing detection techniques, both blackbox and whitebox, face challenges related to the diversity of toxic prompts, scalability, and computational efficiency. In response, we propose ToxicDetector, a lightweight greybox method designed to efficiently detect toxic prompts in LLMs. ToxicDetector leverages LLMs to create toxic concept prompts, uses embedding vectors to form feature vectors, and employs a Multi-Layer Perceptron (MLP) classifier for prompt classification. Our evaluation on various versions of the LLama models, Gemma-2, and multiple datasets demonstrates that ToxicDetector achieves a high accuracy of 96.39\% and a low false positive rate of 2.00\%, outperforming state-of-the-art methods. Additionally, ToxicDetector's processing time of 0.0780 seconds per prompt makes it highly suitable for real-time applications. ToxicDetector achieves high accuracy, efficiency, and scalability, making it a practical method for toxic prompt detection in LLMs.
DRFormer: Multi-Scale Transformer Utilizing Diverse Receptive Fields for Long Time-Series Forecasting
Aug 05, 2024



Long-term time series forecasting (LTSF) has been widely applied in finance, traffic prediction, and other domains. Recently, patch-based transformers have emerged as a promising approach, segmenting data into sub-level patches that serve as input tokens. However, existing methods mostly rely on predetermined patch lengths, necessitating expert knowledge and posing challenges in capturing diverse characteristics across various scales. Moreover, time series data exhibit diverse variations and fluctuations across different temporal scales, which traditional approaches struggle to model effectively. In this paper, we propose a dynamic tokenizer with a dynamic sparse learning algorithm to capture diverse receptive fields and sparse patterns of time series data. In order to build hierarchical receptive fields, we develop a multi-scale Transformer model, coupled with multi-scale sequence extraction, capable of capturing multi-resolution features. Additionally, we introduce a group-aware rotary position encoding technique to enhance intra- and inter-group position awareness among representations across different temporal scales. Our proposed model, named DRFormer, is evaluated on various real-world datasets, and experimental results demonstrate its superiority compared to existing methods. Our code is available at: https://github.com/ruixindingECNU/DRFormer.