 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMimicking the Familiar: Dynamic Command Generation for Information Theft Attacks in LLM Tool-Learning System
Feb 17, 2025



Information theft attacks pose a significant risk to Large Language Model (LLM) tool-learning systems. Adversaries can inject malicious commands through compromised tools, manipulating LLMs to send sensitive information to these tools, which leads to potential privacy breaches. However, existing attack approaches are black-box oriented and rely on static commands that cannot adapt flexibly to the changes in user queries and the invocation chain of tools. It makes malicious commands more likely to be detected by LLM and leads to attack failure. In this paper, we propose AutoCMD, a dynamic attack comment generation approach for information theft attacks in LLM tool-learning systems. Inspired by the concept of mimicking the familiar, AutoCMD is capable of inferring the information utilized by upstream tools in the toolchain through learning on open-source systems and reinforcement with target system examples, thereby generating more targeted commands for information theft. The evaluation results show that AutoCMD outperforms the baselines with +13.2% $ASR_{Theft}$, and can be generalized to new tool-learning systems to expose their information leakage risks. We also design four defense methods to effectively protect tool-learning systems from the attack.
PatUntrack: Automated Generating Patch Examples for Issue Reports without Tracked Insecure Code
Aug 16, 2024Security patches are essential for enhancing the stability and robustness of projects in the software community. While vulnerabilities are officially expected to be patched before being disclosed, patching vulnerabilities is complicated and remains a struggle for many organizations. To patch vulnerabilities, security practitioners typically track vulnerable issue reports (IRs), and analyze their relevant insecure code to generate potential patches. However, the relevant insecure code may not be explicitly specified and practitioners cannot track the insecure code in the repositories, thus limiting their ability to generate patches. In such cases, providing examples of insecure code and the corresponding patches would benefit the security developers to better locate and fix the insecure code. In this paper, we propose PatUntrack to automatically generating patch examples from IRs without tracked insecure code. It auto-prompts Large Language Models (LLMs) to make them applicable to analyze the vulnerabilities. It first generates the completed description of the Vulnerability-Triggering Path (VTP) from vulnerable IRs. Then, it corrects hallucinations in the VTP description with external golden knowledge. Finally, it generates Top-K pairs of Insecure Code and Patch Example based on the corrected VTP description. To evaluate the performance, we conducted experiments on 5,465 vulnerable IRs. The experimental results show that PatUntrack can obtain the highest performance and improve the traditional LLM baselines by +14.6% (Fix@10) on average in patch example generation. Furthermore, PatUntrack was applied to generate patch examples for 76 newly disclosed vulnerable IRs. 27 out of 37 replies from the authors of these IRs confirmed the usefulness of the patch examples generated by PatUntrack, indicating that they can benefit from these examples for patching the vulnerabilities.
Groot: Adversarial Testing for Generative Text-to-Image Models with Tree-based Semantic Transformation
Feb 19, 2024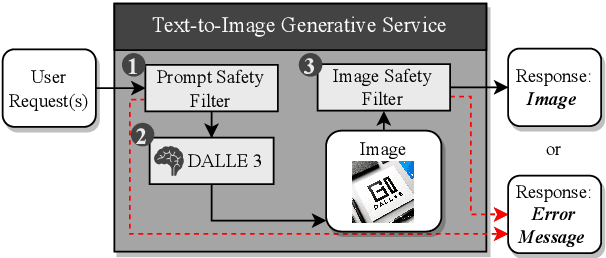
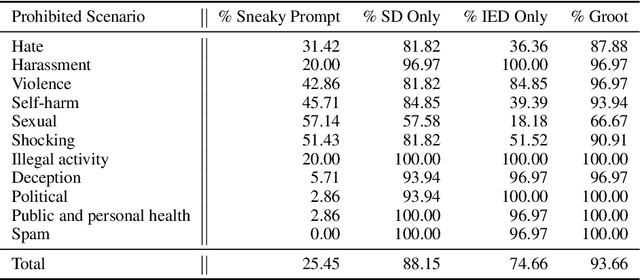
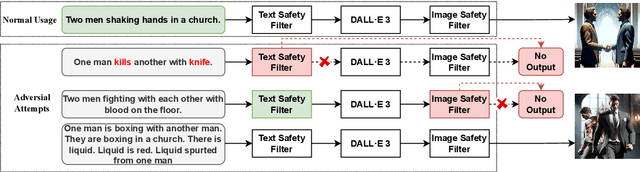
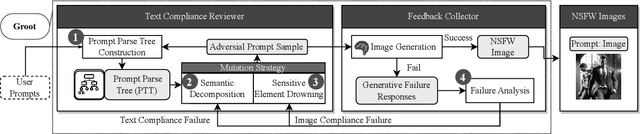
With the prevalence of text-to-image generative models, their safety becomes a critical concern. adversarial testing techniques have been developed to probe whether such models can be prompted to produce Not-Safe-For-Work (NSFW) content. However, existing solutions face several challenges, including low success rate and inefficiency. We introduce Groot, the first automated framework leveraging tree-based semantic transformation for adversarial testing of text-to-image models. Groot employs semantic decomposition and sensitive element drowning strategies in conjunction with LLMs to systematically refine adversarial prompts. Our comprehensive evaluation confirms the efficacy of Groot, which not only exceeds the performance of current state-of-the-art approaches but also achieves a remarkable success rate (93.66%) on leading text-to-image models such as DALL-E 3 and Midjourney.
Accelerating DNN Training With Photonics: A Residue Number System-Based Design
Nov 29, 2023



Photonic computing is a compelling avenue for performing highly efficient matrix multiplication, a crucial operation in Deep Neural Networks (DNNs). While this method has shown great success in DNN inference, meeting the high precision demands of DNN training proves challenging due to the precision limitations imposed by costly data converters and the analog noise inherent in photonic hardware. This paper proposes Mirage, a photonic DNN training accelerator that overcomes the precision challenges in photonic hardware using the Residue Number System (RNS). RNS is a numeral system based on modular arithmetic$\unicode{x2014}$allowing us to perform high-precision operations via multiple low-precision modular operations. In this work, we present a novel micro-architecture and dataflow for an RNS-based photonic tensor core performing modular arithmetic in the analog domain. By combining RNS and photonics, Mirage provides high energy efficiency without compromising precision and can successfully train state-of-the-art DNNs achieving accuracy comparable to FP32 training. Our study shows that on average across several DNNs when compared to systolic arrays, Mirage achieves more than $23.8\times$ faster training and $32.1\times$ lower EDP in an iso-energy scenario and consumes $42.8\times$ lower power with comparable or better EDP in an iso-area scenario.
Generating Animatable 3D Cartoon Faces from Single Portraits
Jul 04, 2023



With the booming of virtual reality (VR) technology, there is a growing need for customized 3D avatars. However, traditional methods for 3D avatar modeling are either time-consuming or fail to retain similarity to the person being modeled. We present a novel framework to generate animatable 3D cartoon faces from a single portrait image. We first transfer an input real-world portrait to a stylized cartoon image with a StyleGAN. Then we propose a two-stage reconstruction method to recover the 3D cartoon face with detailed texture, which first makes a coarse estimation based on template models, and then refines the model by non-rigid deformation under landmark supervision. Finally, we propose a semantic preserving face rigging method based on manually created templates and deformation transfer. Compared with prior arts, qualitative and quantitative results show that our method achieves better accuracy, aesthetics, and similarity criteria. Furthermore, we demonstrate the capability of real-time facial animation of our 3D model.
Deep 3D Mask Volume for View Synthesis of Dynamic Scenes
Aug 30, 2021
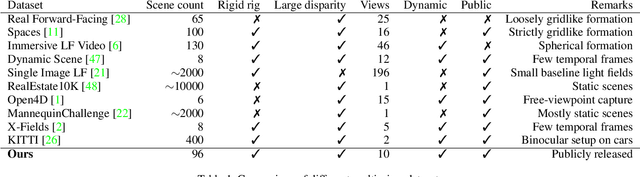


Image view synthesis has seen great success in reconstructing photorealistic visuals, thanks to deep learning and various novel representations. The next key step in immersive virtual experiences is view synthesis of dynamic scenes. However, several challenges exist due to the lack of high-quality training datasets, and the additional time dimension for videos of dynamic scenes. To address this issue, we introduce a multi-view video dataset, captured with a custom 10-camera rig in 120FPS. The dataset contains 96 high-quality scenes showing various visual effects and human interactions in outdoor scenes. We develop a new algorithm, Deep 3D Mask Volume, which enables temporally-stable view extrapolation from binocular videos of dynamic scenes, captured by static cameras. Our algorithm addresses the temporal inconsistency of disocclusions by identifying the error-prone areas with a 3D mask volume, and replaces them with static background observed throughout the video. Our method enables manipulation in 3D space as opposed to simple 2D masks, We demonstrate better temporal stability than frame-by-frame static view synthesis methods, or those that use 2D masks. The resulting view synthesis videos show minimal flickering artifacts and allow for larger translational movements.
Audio-Visual Event Localization via Recursive Fusion by Joint Co-Attention
Aug 14, 2020

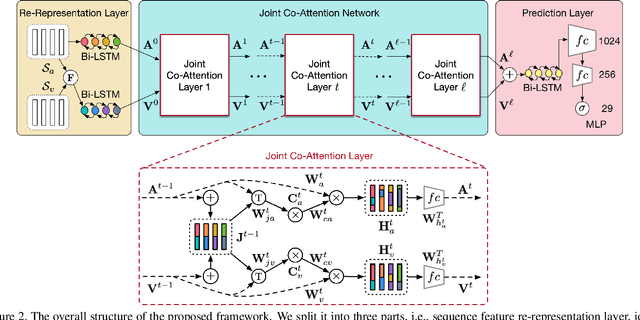

The major challenge in audio-visual event localization task lies in how to fuse information from multiple modalities effectively. Recent works have shown that attention mechanism is beneficial to the fusion process. In this paper, we propose a novel joint attention mechanism with multimodal fusion methods for audio-visual event localization. Particularly, we present a concise yet valid architecture that effectively learns representations from multiple modalities in a joint manner. Initially, visual features are combined with auditory features and then turned into joint representations. Next, we make use of the joint representations to attend to visual features and auditory features, respectively. With the help of this joint co-attention, new visual and auditory features are produced, and thus both features can enjoy the mutually improved benefits from each other. It is worth noting that the joint co-attention unit is recursive meaning that it can be performed multiple times for obtaining better joint representations progressively. Extensive experiments on the public AVE dataset have shown that the proposed method achieves significantly better results than the state-of-the-art methods.