 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Efficient Hyperdimensional Computing Using Photonics
Nov 29, 2023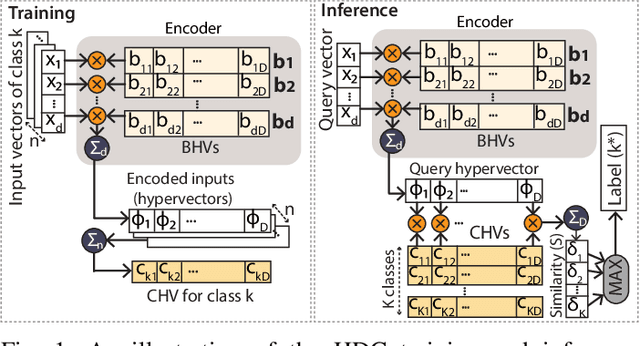
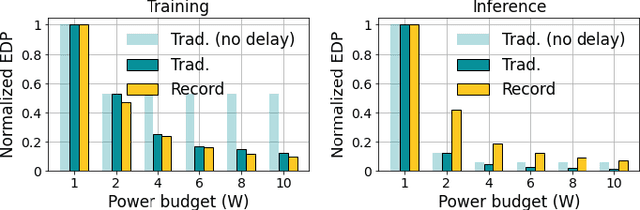
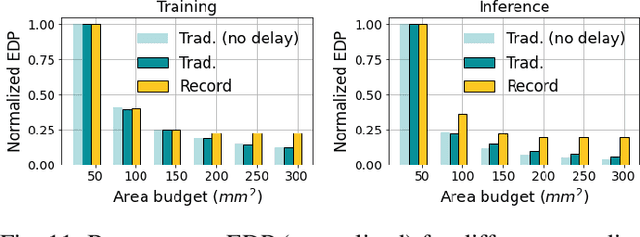
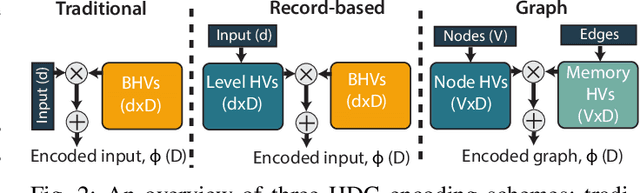
Over the past few years, silicon photonics-based computing has emerged as a promising alternative to CMOS-based computing for Deep Neural Networks (DNN). Unfortunately, the non-linear operations and the high-precision requirements of DNNs make it extremely challenging to design efficient silicon photonics-based systems for DNN inference and training. Hyperdimensional Computing (HDC) is an emerging, brain-inspired machine learning technique that enjoys several advantages over existing DNNs, including being lightweight, requiring low-precision operands, and being robust to noise introduced by the nonidealities in the hardware. For HDC, computing in-memory (CiM) approaches have been widely used, as CiM reduces the data transfer cost if the operands can fit into the memory. However, inefficient multi-bit operations, high write latency, and low endurance make CiM ill-suited for HDC. On the other hand, the existing electro-photonic DNN accelerators are inefficient for HDC because they are specifically optimized for matrix multiplication in DNNs and consume a lot of power with high-precision data converters. In this paper, we argue that photonic computing and HDC complement each other better than photonic computing and DNNs, or CiM and HDC. We propose PhotoHDC, the first-ever electro-photonic accelerator for HDC training and inference, supporting the basic, record-based, and graph encoding schemes. Evaluating with popular datasets, we show that our accelerator can achieve two to five orders of magnitude lower EDP than the state-of-the-art electro-photonic DNN accelerators for implementing HDC training and inference. PhotoHDC also achieves four orders of magnitude lower energy-delay product than CiM-based accelerators for both HDC training and inference.
Accelerating DNN Training With Photonics: A Residue Number System-Based Design
Nov 29, 2023



Photonic computing is a compelling avenue for performing highly efficient matrix multiplication, a crucial operation in Deep Neural Networks (DNNs). While this method has shown great success in DNN inference, meeting the high precision demands of DNN training proves challenging due to the precision limitations imposed by costly data converters and the analog noise inherent in photonic hardware. This paper proposes Mirage, a photonic DNN training accelerator that overcomes the precision challenges in photonic hardware using the Residue Number System (RNS). RNS is a numeral system based on modular arithmetic$\unicode{x2014}$allowing us to perform high-precision operations via multiple low-precision modular operations. In this work, we present a novel micro-architecture and dataflow for an RNS-based photonic tensor core performing modular arithmetic in the analog domain. By combining RNS and photonics, Mirage provides high energy efficiency without compromising precision and can successfully train state-of-the-art DNNs achieving accuracy comparable to FP32 training. Our study shows that on average across several DNNs when compared to systolic arrays, Mirage achieves more than $23.8\times$ faster training and $32.1\times$ lower EDP in an iso-energy scenario and consumes $42.8\times$ lower power with comparable or better EDP in an iso-area scenario.
A Blueprint for Precise and Fault-Tolerant Analog Neural Networks
Sep 19, 2023Analog computing has reemerged as a promising avenue for accelerating deep neural networks (DNNs) due to its potential to overcome the energy efficiency and scalability challenges posed by traditional digital architectures. However, achieving high precision and DNN accuracy using such technologies is challenging, as high-precision data converters are costly and impractical. In this paper, we address this challenge by using the residue number system (RNS). RNS allows composing high-precision operations from multiple low-precision operations, thereby eliminating the information loss caused by the limited precision of the data converters. Our study demonstrates that analog accelerators utilizing the RNS-based approach can achieve ${\geq}99\%$ of FP32 accuracy for state-of-the-art DNN inference using data converters with only $6$-bit precision whereas a conventional analog core requires more than $8$-bit precision to achieve the same accuracy in the same DNNs. The reduced precision requirements imply that using RNS can reduce the energy consumption of analog accelerators by several orders of magnitude while maintaining the same throughput and precision. Our study extends this approach to DNN training, where we can efficiently train DNNs using $7$-bit integer arithmetic while achieving accuracy comparable to FP32 precision. Lastly, we present a fault-tolerant dataflow using redundant RNS error-correcting codes to protect the computation against noise and errors inherent within an analog accelerator.
Leveraging Residue Number System for Designing High-Precision Analog Deep Neural Network Accelerators
Jun 15, 2023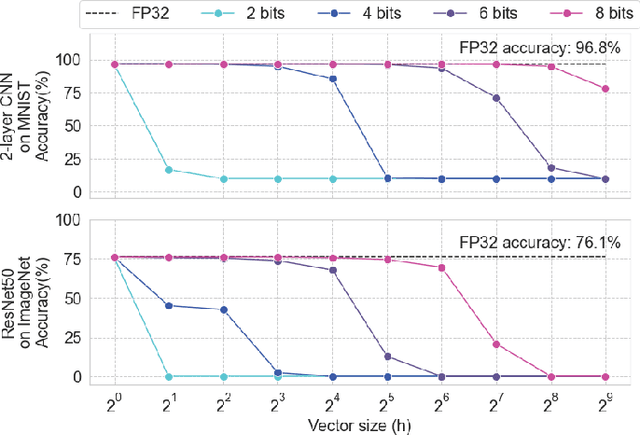
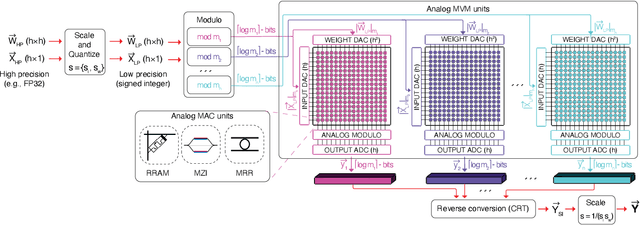
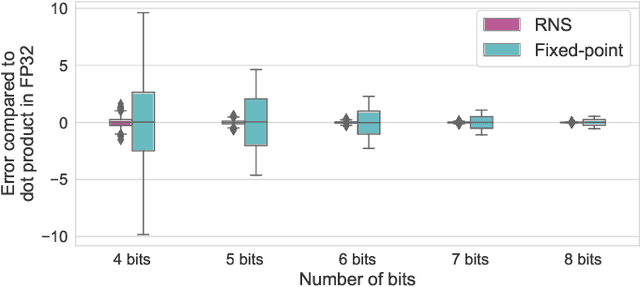
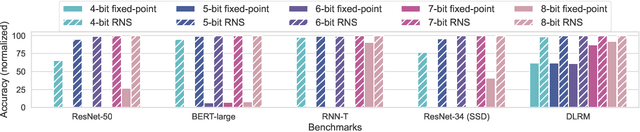
Achieving high accuracy, while maintaining good energy efficiency, in analog DNN accelerators is challenging as high-precision data converters are expensive. In this paper, we overcome this challenge by using the residue number system (RNS) to compose high-precision operations from multiple low-precision operations. This enables us to eliminate the information loss caused by the limited precision of the ADCs. Our study shows that RNS can achieve 99% FP32 accuracy for state-of-the-art DNN inference using data converters with only $6$-bit precision. We propose using redundant RNS to achieve a fault-tolerant analog accelerator. In addition, we show that RNS can reduce the energy consumption of the data converters within an analog accelerator by several orders of magnitude compared to a regular fixed-point approach.
Custom Tailored Suite of Random Forests for Prefetcher Adaptation
Aug 01, 2020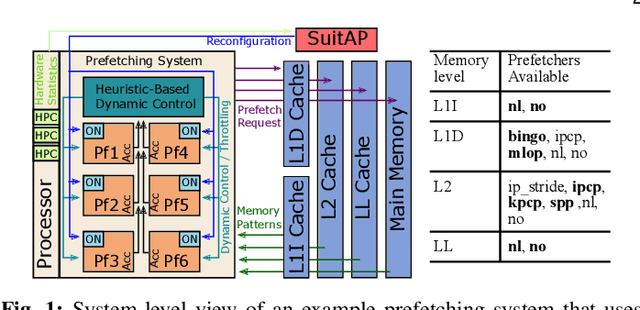

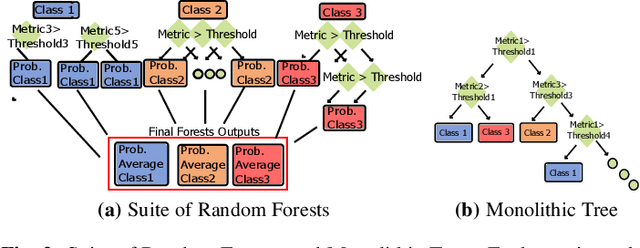
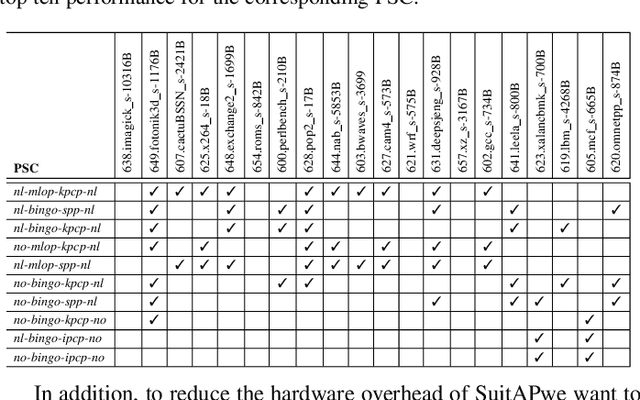
To close the gap between memory and processors, and in turn improve performance, there has been an abundance of work in the area of data/instruction prefetcher designs. Prefetchers are deployed in each level of the memory hierarchy, but typically, each prefetcher gets designed without comprehensively accounting for other prefetchers in the system. As a result, these individual prefetcher designs do not always complement each other, and that leads to low average performance gains and/or many negative outliers. In this work, we propose SuitAP (Suite of random forests for Adaptation of Prefetcher system configuration), which is a hardware prefetcher adapter that uses a suite of random forests to determine at runtime which prefetcher should be ON at each memory level, such that they complement each other. Compared to a design with no prefetchers, using SuitAP we improve IPC by 46% on average across traces generated from SPEC2017 suite with 12KB overhead. Moreover, we also reduce negative outliers using SuitAP.